Webを進化させるスクレイピングのセオリー:まとめサイト2.0(2/2 ページ)
例えば、オルタナティブ・ブログには、「週間アクセスランキング」という項目がある。
この部分は、図1のように、div id="ranking"というid属性が付いている。そして、それぞれのランキング項目は、span class="rank1"、span class="rank2"…、といったデータ構造になっている。
なお、CSSを見ると分かるが、class="rank1"、class="rank2"というのは、文字列の前に「1」や「2」、といったランキング順位を画像として表示するためのものだ。
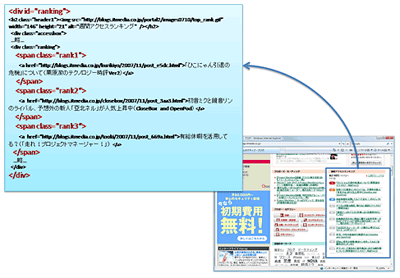 図1■id属性とclass属性で要素を特定する
図1■id属性とclass属性で要素を特定する例えば、「週間アクセスランキング第1位」を取得したいのであれば、
1)div id="ranking"の内部にある
2)span class="rank1"の中身
をたどればよいことになる。
このようにid属性とclass属性を基準にスクレイピングすれば、多少、ブロックの前後関係が変わったとしても対応でき、汎用性が高くなるのだ。
条件を修正しやすいスクレイピング方法を選ぶ
それでは、特定のid属性やclass属性をもった要素をどのようにして抜き出すか。
その主な方法は、次の3通りだ。
1)正規表現で特定する
すぐに思いつく方法は、正規表現を用いて、パターンマッチで抜き出す方法だ。正規表現は、ほとんどのプログラミング言語が対応しており、外部ライブラリが必要ないという利点がある。
実際、単純なHTMLであれば、この方法がもっとも簡単だろう。
しかしこの方法には、「単一の要素」を抜き出すならともかく、「列構造/行構造」でそれぞれの要素を抜き出そうとすると、ループ処理を行う必要があり、要素の階層が深ければ深いほど、プログラムが煩雑になりがちだ。
2)XHTMLにしてXPathで特定する
次に挙げる方法は、HTMLをXHTML化して、XPathで要素を特定するという方法だ。
XPathとは、要素名や順序、属性の値などを基に要素の位置を指定する式である。すでに説明したように、id属性やclass属性を使うとスクレイピングしやすいということを考えると、この方法は理にかなっている。
問題は、XPathに対応しているプログラミング言語もしくはXPathに対応したライブラリが必要になるという点だ。
3)スクレイピング用のライブラリを使う
2)の方法でもさらに面倒だと思うならば、スクレイピング用のライブラリを使うという方法がある。この方法であれば、抜き出したい要素や属性など、条件を指定するだけで、必要な要素を抜き出せ、プログラミングがもっとも簡単である。
スクレイピングする際には、「元のHTMLコンテンツが、いつでもコンテンツ制作者によって変更される恐れがある」ことを考慮する必要がある。ここが、WebAPIを使う場合と大きく違う。
WebAPIは公式な方法であるから、APIの引数が変わったりすることは、基本的にあり得ない。つまり保証された方法である。それに対し、スクレイピングは非公式な方法であり、コンテンツの構造が永続的に同じであることは保証されないのだ。
構造が変わってしまったら、スクレイピングの条件を変更しなければならなくなる。このため、スクレイピングする上では、コンテンツ構成が変わった時に修正しやすいようプログラミングしておくのがよいわけだ。
苦労して作ったスクレイピングのプログラムが、一夜にして動かなくなってしまうこともあるだろう。そう考えると、スクレイピングのプログラミングに時間をかけて本気で取り組むのは、かなりリスクを伴うという側面もある。
そのように考えていくと、上記、1)の正規表現による方法は、修正が困難になりがちだ。作ったスクレイピングのプログラムを保守して長い間使い続けるのであれば、2)や3)の方法が望ましいということになる。
相手の負荷を考える
本連載では、Perlを使って、実際に、「オルタナティブ・ブログ」からコンテンツを引っ張って、いわゆる「まとめサイト」を作っていく手順を説明する。
この連載では、サーバにPerlのプログラムを配置する。そしてそのプログラムを定期的に動かして静的なHTMLを作り、ユーザーは、その生成された静的なHTMLを見るというものにする。定期的にプログラムを動かすにはcronを使うことになるだろう。
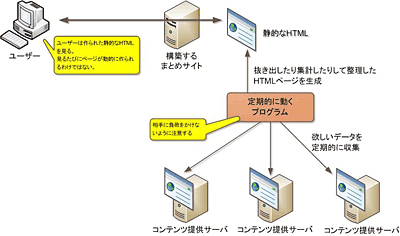 図2■本連載で考える「まとめサイト」の作り方概要
図2■本連載で考える「まとめサイト」の作り方概要図2でポイントとなるのは、ユーザーが見ているページは、アクセスのたびに動的に作られるのではなく、定期的に動作するプログラムによって作られた「静的なHTML」であるという点だ。
仕組みとしては、「まとめサイト」をCGIとして構成し、動的に作ることもできる。つまり、前編の図1に示した「サーバサイドでWebAPIを呼び出す構成」と同じようにも作ることができる。
しかし、スクレイピングはHTMLを解析するため、WebAPIの呼び出しに比べて負荷が高い。しかも、ユーザーがアクセスするたびに、「コンテンツ提供元のサイト」にアクセスすることになり、相手に対して多くの負荷となる可能性がある。WebAPIを提供しているサイトなら、ある程度の負荷を予測しているだろう。しかし、スクレイピングを想定しているサイトはそれほど多くないだろう。
実際、1つのIPアドレスから多数のアクセスが殺到すれば、監視システムが作動して、アクセス制限を受けることもあり得る。そのような背景で、スクレイピングする際には十分に注意し、相手のサーバに負荷をかけすぎないような細心の配慮が必要だ。
必要以上の間隔で情報取得をしないように設定し、また、場合によっては、最終更新日を見て(これはHTTPのLast-Modifiedヘッダで確認できる)、更新されていない場合には処理をスキップするといった工夫をするのが望ましい。
次回は、実際にPerlを使ったスクレイピングのプログラミング方法を説明していくことにしよう。
Copyright © ITmedia, Inc. All Rights Reserved.
注目のテーマ




人気記事ランキング
- 江崎グリコ、基幹システムの切り替え失敗によって出荷や業務が一時停止
- Microsoft DefenderとKaspersky EDRに“完全解決困難”な脆弱性 マルウェア検出機能を悪用
- 生成AIは2025年には“オワコン”か? 投資の先細りを後押しする「ある問題」
- 「欧州 AI法」がついに成立 罰金「50億円超」を回避するためのポイントは?
- 「Copilot for Securityを使ってみた」 セキュリティ担当者が感じた4つのメリットと課題
- 日本企業は従業員を“信頼しすぎ”? 情報漏えいのリスクと現状をProofpointが調査
- トレンドマイクロが推奨する、長期休暇前にすべきセキュリティ対策
- AWSリソースを保護するための5つのベストプラクティス CrowdStrikeが指南
- VMwareが「ESXi無償版」の提供を終了 移行先の有力候補は?
- Javaは他のプログラミング言語と比較してどのくらい危険なのか? Datadog調査
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。