PDFファイルを分析する
悪意あるPDFファイルコーディングに段階的変化が見られる。getPageNthWordやgetPageNumWordsのような、Adobeに特有なJavaScriptオブジェクトを使用して分析するのは有効かもしれない。
悪意あるPDFファイルコーディングに段階的変化が見られる(マルウェアオーサーは自分たちのテクニックを適応させることができるし、実際適応させてきたことを考えれば当然のことだ)。
長いことわれわれは、シェルコード、ダウンロード/実行、ドロップ、ロードなどなど、悪質なコードの目的を容易に判別できるような、シンプルな悪意あるPDFファイルを見てきた。
現在は、ますます複雑な難読化が使用されており、PDFファイルを分析することが必要だ。特にこの難読化により、自動化された分析ツールやAV検出ツールさえ回避される可能性があるため、このことは、アナリストの日常生活をより惨めに、あるいは興味深いものにし得る。
ここ数カ月、わたしが遭遇した1つのテクニックは、getPageNthWordやgetPageNumWordsのような、Adobeに特有なJavaScriptオブジェクトを使用するものだ。以下はある例のスクリーンショットだ。
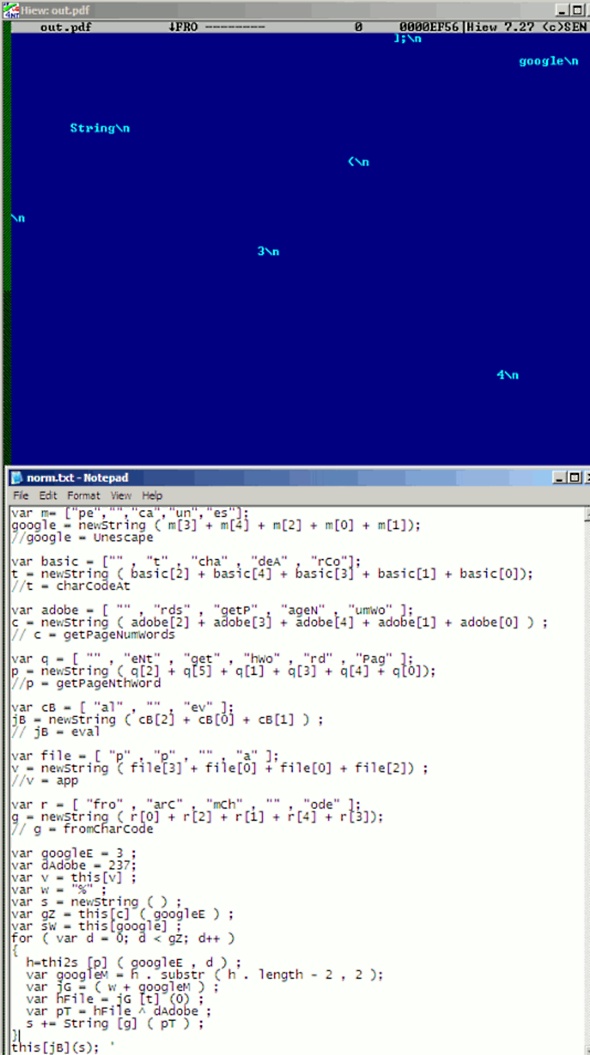
保守的なスタイルのスペーシングが使用されていることに注意してほ欲しい。ノートパッドのコメントは、より簡単に読めるように加えられたものだ。
いずれにせよ、いったんこれが標準化されれば、読んだり分析するのが、ずっと容易なものになるだろう。
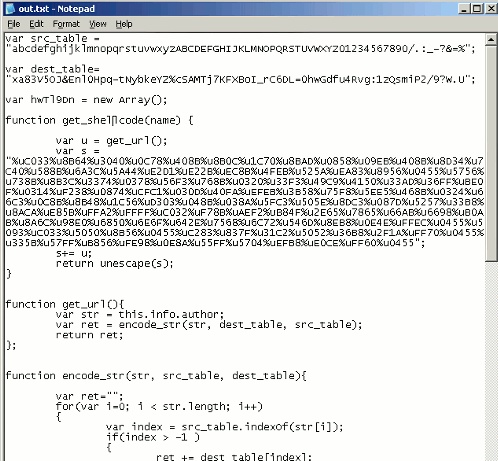
PDF難読化に関する興味深い分析は、SANSにも掲載されている。
投稿はZimryによる。
関連記事
 未修正の脆弱性を狙うPDFファイルに注意、SANSが再度警告
未修正の脆弱性を狙うPDFファイルに注意、SANSが再度警告
Adobe ReaderやAcrobatの未修正の脆弱性を悪用する不審なPDFファイルによる攻撃が増加しているとして、SANSが改めて注意を呼び掛けた。 Adobe ReaderとAcrobatの脆弱性、修正パッチは1月12日にリリース
Adobe ReaderとAcrobatの脆弱性、修正パッチは1月12日にリリース
ゼロデイ攻撃も発生しているReaderとAcrobatの脆弱性が解決されるのは1月12日になる。 Adobe ReaderとAcrobatを悪用する攻撃発生、未修正の新たな脆弱性が見つかる
Adobe ReaderとAcrobatを悪用する攻撃発生、未修正の新たな脆弱性が見つかる
脆弱性を突いた悪質なPDFが電子メールの添付ファイルとして出回っているという。
関連リンク
Copyright © ITmedia, Inc. All Rights Reserved.
注目のテーマ




人気記事ランキング
- 江崎グリコ、基幹システムの切り替え失敗によって出荷や業務が一時停止
- Microsoft DefenderとKaspersky EDRに“完全解決困難”な脆弱性 マルウェア検出機能を悪用
- 生成AIは2025年には“オワコン”か? 投資の先細りを後押しする「ある問題」
- 投資家たちがセキュリティ人材を“喉から手が出るほどほしい”ワケ
- Javaは他のプログラミング言語と比較してどのくらい危険なのか? Datadog調査
- ゼロトラストの最新トレンド5つをガートナーが発表
- 大田区役所、2023年に発生したシステム障害の全貌を報告 NECとの和解の経緯
- トレンドマイクロが推奨する、長期休暇前にすべきセキュリティ対策
- 「Copilot for Securityを使ってみた」 セキュリティ担当者が感じた4つのメリットと課題
- WordPressプラグイン「Forminator」にCVSS 9.8の脆弱性 急ぎ対処を
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。