「ビッグデータという呼び方は嫌いだ」とTeradataのブロブストCTO:Teradata PARTNERS 2013 Report(2/2 ページ)
「Hadoopオープンソースの取り組みは素晴らしいが、それだけではデータから価値を引き出すことは難しい。Hadoopでは、エンジニアがMapReduceフレームワークでプログラミングする必要があるからだ」とブロブスト氏。
Teradataが買収したAster Data Systemsは、スタンフォード大学の学生寮から生まれた。プログラミングに精通したエンジニアでなくとも、ビッグデータという無限の宇宙の中から新たなビジネスチャンスを見つけ出せるようにしたい、という学生のアイデアが始まりだった。彼らのnClusterデータベースは、安価なIAサーバでクラスタを構築し、「SQL-MapReduce」フレームワークによって、使い慣れたSQL操作でビッグデータ分析を並列処理させることができた。
Teradataによる買収後、AsterはHadoopとの統合が進められ、「Aster Big Analytics Appliance」もリリースされたほか、Teradata、Aster、そしてHadoopという3種類の並列処理型データベースをシームレスに連携できる「Unified Data Architecture」(UDA)では、「ディスカバリープラットフォーム」としてその中核をなしている。
データの「実験」を担うデータサイエンティスト
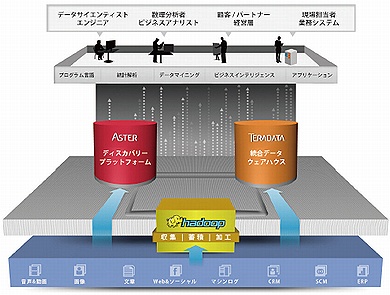 TeradataのUnified Data Architecture
TeradataのUnified Data Architecture「われわれのビッグデータに対するアプローチは、UDAだ。1つのテクノロジーでは、膨大かつ多様なビッグデータから価値を見つけ出し、より良いアクションに結び付けていくのは難しいからだ」とブロブスト氏。
UDAは、統合データウェアハウスのTeradata、ディスカバリープラットフォームのAster、データプラットフォームとしてのHadoopを適材適所で活用するアプローチだ。
いま最もセクシーともてはやされている「データサイエンティスト」の仕事は、仮説を立て、膨大かつ多様なデータの中から例えば、購買に結び付くパターンを見つけ出すこと。その「実験室」のツールとしては、コンピュータのエンジニアではなくても分析処理できるAsterが適している。一方、データサイエンティストが見つけ出したデータへの「問い」を活用し、ビジネスの課題を解決し、価値を引き出すのはビジネスアナリストだ。
「Hadoopに取り込んだビッグデータを素材とし、Asterという実験室で研究開発し、Teradataという工場で商用化してデータの価値を引き出していく」(ブロブスト氏)
人材不足が懸念されているデータサイエンティストだが、ブロブスト氏は、応用化学や応用物理学、あるいは社会学を学んだ人たちが向いているのではないかと指摘する。
「大学の研究室で埋もれてしまっている能力がデータサイエンティストとして生きるはず。わたしは甥(おい)にも“データサイエンティストになれ”と言っている」とブロブスト氏は笑う。
関連記事
Copyright © ITmedia, Inc. All Rights Reserved.
注目のテーマ




人気記事ランキング
- 江崎グリコ、基幹システムの切り替え失敗によって出荷や業務が一時停止
- Microsoft DefenderとKaspersky EDRに“完全解決困難”な脆弱性 マルウェア検出機能を悪用
- 生成AIは2025年には“オワコン”か? 投資の先細りを後押しする「ある問題」
- 「欧州 AI法」がついに成立 罰金「50億円超」を回避するためのポイントは?
- 「Copilot for Securityを使ってみた」 セキュリティ担当者が感じた4つのメリットと課題
- 日本企業は従業員を“信頼しすぎ”? 情報漏えいのリスクと現状をProofpointが調査
- AWSリソースを保護するための5つのベストプラクティス CrowdStrikeが指南
- トレンドマイクロが推奨する、長期休暇前にすべきセキュリティ対策
- VMwareが「ESXi無償版」の提供を終了 移行先の有力候補は?
- Javaは他のプログラミング言語と比較してどのくらい危険なのか? Datadog調査
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。