| News | 2003年7月8日 04:36 PM 更新 |
純国産検索エンジンを支える「SIGUMA」アルゴリズムの正体とは?
Web検索サービスの主流はフルテキストによる検索処理。検索精度と高速処理のために単語インデックスは必須。しかし、単語の切り出しが難しい日本語では、これが非常に困難な作業なのだ。一方、インデックスを使用しない検索エンジンでは、パフォーマンスに難がある。この相反する条件を満たす検索エンジンのコアテクノロジーを紹介しよう。
国士舘大学は7月7日、新しい図書館統合知識情報サービス「Kiss」を発表した。このシステムは、図書館の蔵書データベースの検索のみならず、動画などを組み合わせたマルチメディアコンテンツなどの国士舘大学で使われるあらゆる情報を利用できる、独自のデータベース検索ツールだ。
Kissトップページ。汎用的な検索は組み込まれた「Google」などの商用検索エンジンを利用できる。国士舘大学内部の独自コンテンツは「KISS-WIN」(大学施設FAQデータベース)、「KISS-DB」(大学出版物、内部資料)、「KISS-DIC」(学内専門用語、時事用語、人物プロファイルデータベース)、「KISS-MA」(授業などのマルチメディアコンテンツ)の4種類のツールで検索する
この発表会では、Kissの機能紹介、デモンストレーションと併せて、Kissの基幹技術であるXML対応のフルテキスト検索データベース「フルサーチ瞬索」の技術解説も行われた。
XML対応フルテキスト検索エンジン、というものはそれほど新しいテクノロジーではない。Web検索サービスでは広く使われているもので、ご存じ「Google」もXML対応の検索エンジンを実装している。
Googleと聞いて、「いまさら、キラーサービスが存在する検索サービスを研究開発して何になるのか」、と思う読者も多いと思うが、フルテキスト検索エンジンに関しては、まだ決定的なものが現れていないのが現状。Googleでも「フルテキスト検索機能」の弱さを指摘する専門家が多い。
従来のフルテキスト検索システムは、蓄積されているテキストデータからインデックスファイルを生成する仕組みになっている。インデックスは検索キーとの照合に使われる非常に重要なデータである。検索にあたってはそれこそ、一文字の相違が影響することになる。欧文対応のシステムの場合、スペースが存在するおかげで、単語の切り出しはまず間違いないが、単語の区切りに規則のない日本語では、この単語の切り出しで非常に苦労することになる。
この単語の切り出しでよく行われているのが、品詞で分割する方法。ただし、品詞の判別精度に問題がある場合、インデックスに登録される単語に不適切なものが紛れ込み、検索で必要なデータがヒットしなかったり、逆に適切でないデータが検出される可能性が出てくる。
現在、フルテキスト検索系サービスでよく使われている単語切り出し技術が、n-gram方式と日本語変換ソフトでも普及している形態素解析。どちらも冗長性や複雑な手順によって、精度の高い、もしくはヒット率の高いインテックステーブルを作成できる。しかし、その分、インデックス作成に要する負荷はデータベースの構造が複雑さに比例して、膨大なのものになってしまう。
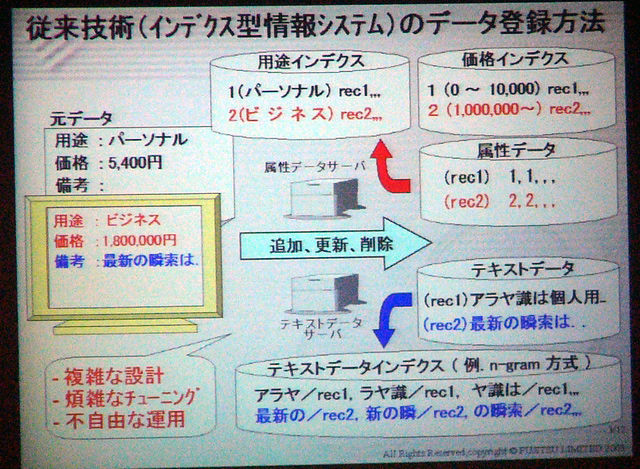
インデックステーブルを作成し、フルテキスト検索のインデックス作成にn-gram法を採用している場合。インデックステーブルを利用すると、検索パフォーマンスが高いなどのメリットがあるが、一方で、インテックステーブルの変更や、データベース構造そのものの変更が非常に大変、という側面を持つ
これに対して瞬索検索エンジンは、インデックスファイルを用いずに全文検索を行うところが特徴。この形式のデータベースでは、レコードフィールドをタグ付きテキスト(このタグ記述がXMLに準拠していればXML対応検索エンジンとなる)で整理したテーブルを構築し、入力された検索項目に対応したタグに対して、入力値とデータベースの値が照合される。
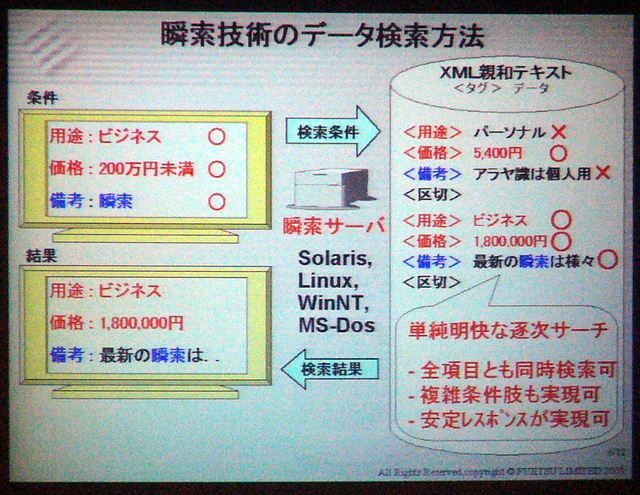
タグ付きテキストの形式で構成されたデータベースに対して検索を行う場合、全データを順次サーチしていき、タグの識別と値の照合を行って、検索条件に一致するレコードを抽出する。インデックスを生成する必要がないので、データベースの構造を柔軟に変更できるメリットがある
しかし、インデックスファイルを用いない場合、照合処理に非常に時間がかかるといった欠点がある。この欠点を補うため、瞬索では九州大学の有川節夫教授が考案した「SIGUMA」検索アルゴリズムを採用している。
このアルゴリズムはパターン認識法の一種。データベースに入力されたテキストデータも検索データもすべて文字コードとして認識させてしまう。両者のコード配列が一致した場合に「条件に合うレコード」として抽出される仕組みだ。
インデックスファイルを使わない検索では、一つの検索条件ごとに、データベースに登録されているすべてのデータをサーチしなければならない。そのため、複数の項目で検索をかけたり、複数のユーザーから検索のリクエストがかかると、その分だけ全件検索を繰り返すことになり、膨大な時間を費やしてしまう。
SIGUMA検索エンジンでは、複数の検索条件を一つの検索入力に「重ね合わせる」ことで、一度の処理で検索を終了できるのが特徴だ。
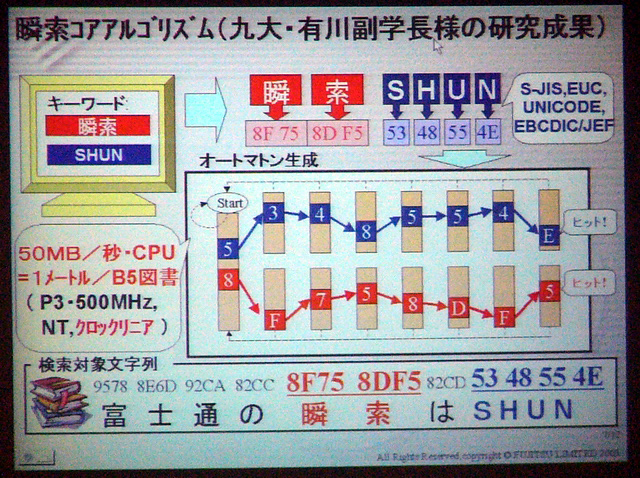
瞬索のSIGUMAアルゴリズムで採用されている「オートマトン」生成による検索条件の重ね合わせ。パターン検索では、コード配列が検索値とデータベース値で一致した場合、条件が一致したものと扱われる。SIGUMAでは、重ね合わせたそれぞれの配列パターンをマッチングさせることで、複数の検索条件を一度に処理できる
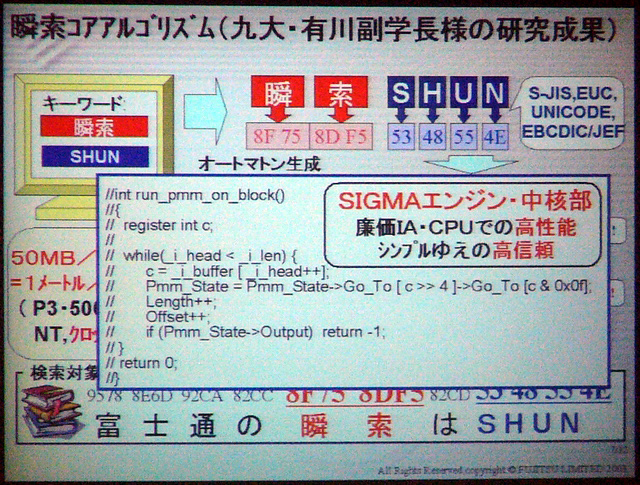
プレゼンテーションで示されたSIGUMAアルゴリズムのコアプログラム。わずか6ステップのwhile文でパターン認識を実行している。このため、パフォーマンスの低いCPUでも実用的なパフォーマンスを発揮する。富士通の評価では、Pentium III/500MHzのマシンで、300ページ(2000文字/ページ)の本40冊を1秒で検索できた
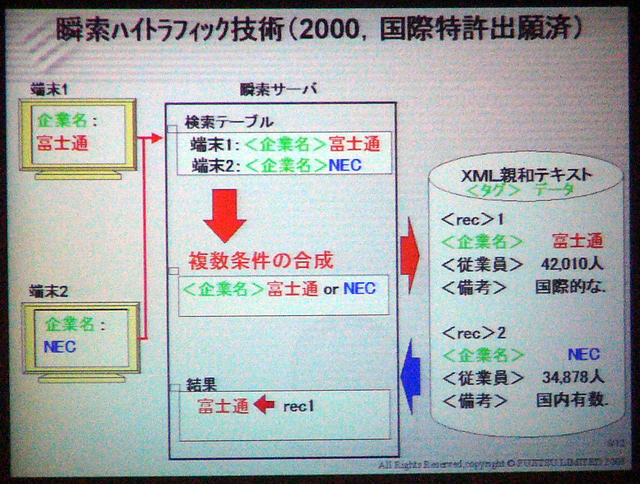
複数の検索条件を重ね合わせられる特徴を利用した「ハイトラフィック技術」。複数のユーザーから要求された検索条件を重ね合わせて一度に処理できるため、検索トラフィックが集中しても、検索パフォーマンスはほとんど変わらない
瞬索も1993年に出荷が開始されているので、すでに「10年選手」の古株である。ハローワークや大学入試センター、NHKのアーカイブシステムなどに採用されているが、マルチサーバシステムへの対応など改良も加えられ、まだまだ性能向上の可能性を残している。
現在、Webで展開している商用大手検索サービスは、ほとんど海外製エンジンが稼動している状況だ。しかし、国内でもジャストシステムのConceptBaseや、NTT インテリジェントテクノロジのInfoBeeなど優秀なエンジンも存在する。冒頭でも述べたように、まだ圧倒的なエンジンは存在しないフルテキスト検索で、国産検索エンジンにも、まだチャンスがあるのではないだろうか。
関連記事関連リンク
[長浜和也, ITmedia]
Copyright © ITmedia, Inc. All Rights Reserved.
![]()
ITmediaはアイティメディア株式会社の登録商標です。