
さらなるAI活用に備えよ
AIインフラ構築のハンズオンに潜入取材 NVIDIAのGPUサーバに触ってみた
ますます重要、だが課題も多いAIインフラ構築
数年前から注目を集めてきた生成AIは、検証フェーズから本番運用フェーズに移行しつつある。実用化に向けて動き出した企業にとって課題となるのが、AIインフラをどう構築するかだ。AIをビジネスの競争力につなげるためには、蓄積してきたデータとAIを掛け合わせられるかどうかが鍵になるだろう。機密性の高いデータなどを扱うケースでは、オンプレミスのAIインフラが有力な選択肢だ。
しかし、AIインフラの構築はGPUサーバやネットワークからストレージ、ファシリティー、ソフトウェアまで従来の仮想化基盤とは異なる点が多い。高い性能を実現するためには電力や冷却などの要件も考慮する必要があり、安定した基盤の実装はハードルが高い。AIインフラに関する専門知識を持つエンジニアは不足しており、人材の確保も大きな課題だ。
AI活用を後押しする「C&S AI INNOVATION FACTORY」
この状況を打開する存在として注目したいのが、2025年7月にオープンした「C&S AI INNOVATION FACTORY」だ。AIワークロードに必要な環境をそろえ、デモツアーやリモートでの機器貸し出しなどを通じてインフラ構築から活用までの検証などに利用できる。
IDCフロンティアが運営する東京・府中のデータセンターに、NVIDIAのサーバをはじめ、スイッチ、ストレージまでひと通りのAIインフラを構築。府中のデータセンターは以前から高負荷ハウジングサービスを提供し、電力供給や液冷技術など将来を見据えた冷却設備も有しており、AIワークロードに十分対応できる環境を誇る。
サーバは「NVIDIA DGX H200」を採用。これはNVIDIAがAIやディープラーニング向けに開発したプラットフォームで、GPUの進化に合わせてメモリなどの性能も強化するなど、AIワークロードを高速化するための工夫が随所に施されている。
 稼働しているNVIDIA DGX H200(ぼかし加工は編集部によるもの)
稼働しているNVIDIA DGX H200(ぼかし加工は編集部によるもの)
「C&S AI INNOVATION FACTORY」は、こうした環境を用いたハンズオントレーニングを実施している。GPU環境の基本を学ぶ「Basic」、複数ノードのクラスタを構築する「Advanced」、AIモデル開発のインフラ構築手順まで含む「Master」(2025年9月開始予定)という3つのメニューをラインアップ。実際にAIインフラに触れながら、構築手順などを習得できると受講者からの反響は大きい。
人気ハンズオンに潜入 座学&演習でGPUサーバの基本を習得
今回はBasicのハンズオンに参加する機会を得たので、詳細をレポートしたい。前半のオンラインで行う座学(60分)でNVIDIAサーバの詳細を学び、後半の演習(90分)で実際に操作を体験する構成だ。
座学は、利用するサーバ「NVIDIA DGX H200」についてハードウェア、ソフトウェアの両面から詳細な解説があった。NVIDIA DGXシリーズはいずれも発表された時点で最新のGPUアーキテクチャを搭載しており、特にNVIDIA DGX H200はメモリ性能を強化している点が特徴。GPU1基当たりのメモリ容量は141GB、メモリ帯域幅も約4.8TB/sと前世代から大幅に進化しており、講義を担当したSB C&Sの下山翔也氏(ICT事業本部 技術本部 技術統括部 第2技術部 1課)は「AIワークロードにこれ以上ないと言って差し支えない」と話す。
NVIDIAのサーバはGPU間を直接接続する高速インタフェース「NVIDIA NVLink」「NVSwitch」を用意している。それらの構成要素が筐体にどのように配置されているのかについての解説もあった。
専用のシステム管理・監視ツールまで、必要なソフトウェアを装備
NVIDIA DGXはOSやドライバからオーケストレーションツールまで、専用のソフトウェアスタックを提供している。中でも重要なのが、オーケストレーションを担う「NVIDIA Base Command」だ。AI開発のライフサイクル管理からインフラ運用の効率化まで実現するソフトウェアプラットフォームで、「DGXという土台の上でワークフローを統括する司令塔のような役割」(下山氏)を果たす。
DGX H200にプリインストールされているOSやGPUドライバ、Docker Engineなどのソフトウェアが紹介されたが、覚えておきたいのがシステム管理・監視ソフトウェアの「NVIDIA System Management」(NVSM)と「NVIDIA Data Center GPU Manager」(DCGM)だ。NVIDIAのサーバは汎用(はんよう)サーバよりもコンポーネントが多く、AIワークロードに最適化するために特殊な構成を取っている。そのためシステム管理にも専用のソフトウェアが用意されている。この2つの下位レイヤーにあるAPIでGPUの基本情報を収集し、DCGMでGPUを管理・監視する。DCGMの情報を基にNVSMでDGXノードのヘルスチェックやアラート監視、GPUパラメーター管理などを行うという関係になっている。
プリインストールされていないソフトウェアとしては「NVIDIA AI Enterprise」と「NVIDIA NGC」などがある。NVIDIA AI EnterpriseはAI開発から本番運用までカバーするソフトウェアスイートで、AIフレームワークやライブラリ、事前学習モデル、管理ツールなどが含まれる。NVIDIA NGCはGPUに最適化されたソフトウェアを集めた“カタログ”で、事前学習済みのモデルやSDKなどをコンテナ形式で配布している。つまり、必要な環境をダウンロードしてすぐに利用できるというわけだ。NVIDIA AI Enterpriseの各種リソースもNVIDIA NGCを介して提供している。
最後に、ハードウェアの設置や初期セットアップまでの解説を聞いた。NVIDIA DGX H200はかなりの重量があるため、搬入などにも気を使う必要がある。安全な移動やラッキングの注意点なども説明があるのは興味深い。
いざ演習! サーバにログインし、コマンドなどでの操作を体験
座学が終了した後は演習だ。ブラウザで仮想デスクトップ環境にアクセスして、NVIDIA DGX H200の環境に接続した。
演習はOSやGPU、NICなどの環境を確認するところから始まった。指定されたコマンドを入力して情報を取得する形式で、受講者8人分の8基のGPUが搭載されていることが見て取れた。
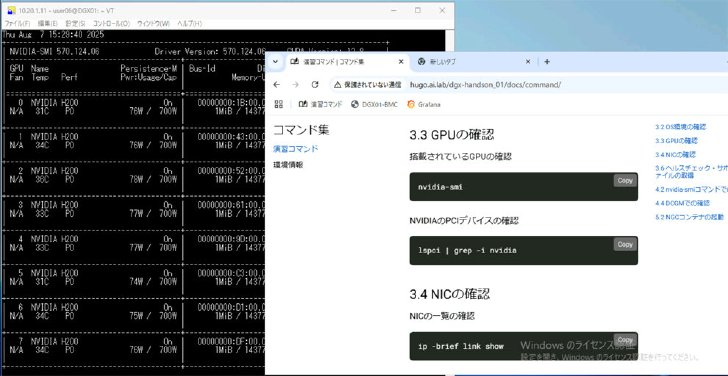 講師の解説を聞き、用意されたコマンドをコピー&ペーストしながら環境を確認する。操作につまずいたり不明点があったりしたら、いつでも質問できるので安心だ《クリックで拡大》
講師の解説を聞き、用意されたコマンドをコピー&ペーストしながら環境を確認する。操作につまずいたり不明点があったりしたら、いつでも質問できるので安心だ《クリックで拡大》
続いてBaseboard Management Controllerを利用してセンサーの値やインベントリ情報を確認した。ブラウザで、各種情報がまとめられたダッシュボードにアクセスできる。特に難しい操作は必要なく、一般的な管理ツールと同じ感覚で使えるという印象だった。
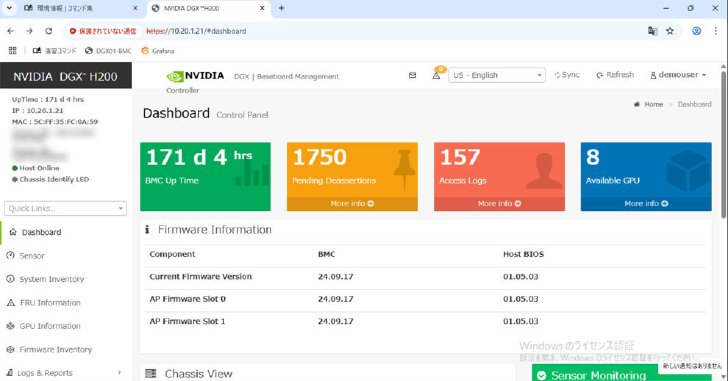 Baseboard Management Controllerのダッシュボード。コンポーネントの状態やイベントログの確認などを行える(ぼかし加工は編集部によるもの)《クリックで拡大》
Baseboard Management Controllerのダッシュボード。コンポーネントの状態やイベントログの確認などを行える(ぼかし加工は編集部によるもの)《クリックで拡大》
NVSMによるヘルスチェックに加え、DCGMを用いたGPUの監視なども実施。いずれもコマンドでの操作だったが、有効化の手順やどのような情報を確認できるか、ヘルスチェック実施時の注意点など実際の運用を想定した内容となっていた。
DCGMについてはDCGM-Exporterによる可視化まで体験できた。DCGM Exporterとはメモリ使用量や消費電力などメトリクスを収集、出力するものだ。出力したメトリクス情報を時系列データベース「Prometheus」に保存し、それをダッシュボードツール「Grafana」で可視化する。ハンズオンではGrafanaによるダッシュボードが構築されており、GPUごとの温度や使用電力などをグラフで確認できた。グラフのテンプレートを調整してもよいし、イチから画面を作成することも可能だ。
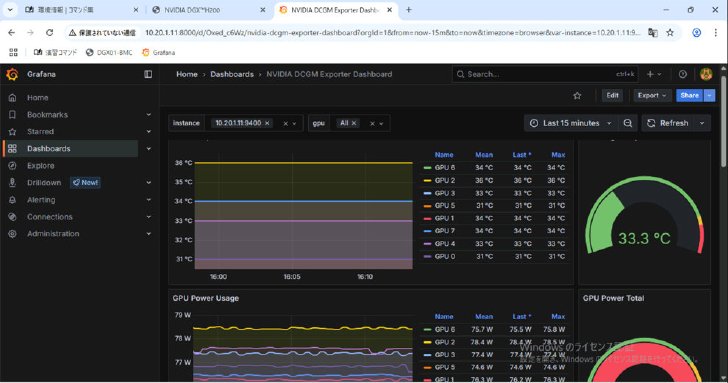 DCGM-Exporterで収集したメトリクス情報を可視化。GPUごとの温度や使用電力などを確認できる《クリックで拡大》
DCGM-Exporterで収集したメトリクス情報を可視化。GPUごとの温度や使用電力などを確認できる《クリックで拡大》
AIによる学習、推論、ファインチューニングまで体験
演習の最後は、GPUリソースを活用したAIワークロードの体験だ。「物体検出モデルを用いた画像セグメンテーションとファインチューニング」というテーマで、画像から特定の物体を検出するモデルを作成し、ファインチューニングで精度を向上させて結果の違いを比較して成果を確認するという流れだった。
今回はNVIDIA NGCで配布されているコンテナイメージを利用して、画像から「ヘルメットの有無」を認識するモデルを作成した。コマンドでコンテナを起動した後、用意されたコードをJupyterLab上で手順に沿って実行した。
学習済みモデルで推論すると、ヘルメットの有無ではなく一般的な物体として「person」「car」といったラベルが付けられた。
その後ファインチューニングを経て再度推論すると、ヘルメット着用の有無を判断できるようになった。この間、Grafanaで環境を確認すると学習中はGPUの温度や電力使用量が上昇している様子が見られた点も含め、非常に面白い体験だった。
 始めは人や車などを認識しているが、ヘルメットの着用有無はまだ判断できていない。ファインチューニング後の推論は、ヘルメット着用の有無を判断できるようになった《クリックで拡大》
始めは人や車などを認識しているが、ヘルメットの着用有無はまだ判断できていない。ファインチューニング後の推論は、ヘルメット着用の有無を判断できるようになった《クリックで拡大》
AIインフラ活用への第一歩に
演習後の質疑応答をもって、ハンズオンは無事に終了。受講者に話を聞くと、事業戦略としてGPUサーバを積極的に扱うようになったことがきっかけでハンズオンに参加したという。座学から演習まで全体を通して非常に分かりやすかったと、総じて好評だった。
特に今回の演習は、GPUサーバの導入、設置後にステータス確認としてひと通りチェックすべきポイントを網羅している。「インフラチームとして、サーバのデリバリーから顧客が利用できる状態にするまでがミッション」という受講者は、納品時にヘルスチェックなどのエビデンスを残す際に「NVIDIA DGX H200ならここまでやればよい」という具体的なイメージを持てたとコメントしていた。
今回参加したハンズオンは、NVIDIAのGPUサーバについて基本からしっかり学べる貴重な機会だった。AIインフラの重要度が高まっているとはいえ、サーバを操作できる機会は少なく、学習のハードル自体が高いことは否めない。触ったことがないから導入が進まず、導入できないから触る機会もない……といった悪循環を断ち切る良いチャンスになるはずだ。
「C&S AI INNOVATION FACTORY」は、Basicの他にもAdvanced、Masterと、より応用的な内容を学べるハンズオンも開講している。機会があれば、これらも受講してみたい。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事


SB C&S株式会社
アイティメディア営業企画/制作:ITmedia AI+編集部/掲載内容有効期限:2025年10月10日


