ビッグデータ対応は今に始まったことではない IBMのソフト&ハード統括責任者:IBM Information On Demand 2011 Report
これまでもIBMでは顧客の情報活用を支援するためにさまざまな製品やサービスを提供してきた。「ビッグデータ」に対する市場のニーズの高まりを受けて基盤を整備した。
10月25日(現地時間)、米IBMがラスベガスで開催中のデータ分析製品に関する年次カンファレンス「IBM Information On Demand 2011」は2日目を迎えた。午前中のキーノートセッションでは、同社のソフトウェア部門およびハードウェア部門を統括するシニアバイスプレジデント、スティーブ・ミルズ氏が「ビッグデータ」におけるIBMの優位性を強調した。

「最近はビッグデータという言葉を聞かない日はない。どこもかしこもビッグデータで、まるで突然データが爆発したかのようだ」。ミルズ氏はこう切り出し、ビッグデータに対する世の中の過熱ぶりを改めて聴衆に示した。ミルズ氏がIT業界に入った38年前はデータの単位はキロバイト(KB)が限界だったというが、今やテラバイト(TB)、ペタバイト(PB)、さらにはペタバイトの10億倍であるヨタバイト(YB)という単位まで登場している。データの量に加えて、内容も多様化している。従来のように静的な構造化データだけではなく、センサデータやコールセンターの音声データ、TwitterやFacebookのテキストデータなど、動的で非構造的なデータが増加の一途をたどっている。
こうしたビッグデータの世界に企業が対応するには、「いかに利用できるデータを抽出し、そこから洞察を得てデータの関連性やパターンを見つけ、行動に移すかが重要だ」とミルズ氏は説明する。
ビッグデータに関して、ミルズ氏は「概念は昔から存在しており、それに対してIBMは長年取り組んできたことである」と述べる。顧客が情報からより良い結果を引き出すのを支援するために、ハードウェア、ソフトウェア、ネットワークインフラなどに投資してきたという。そうした経験をビッグデータに対応する形で改めて整理したのが、「Big Data Platform」といえる(図1)。
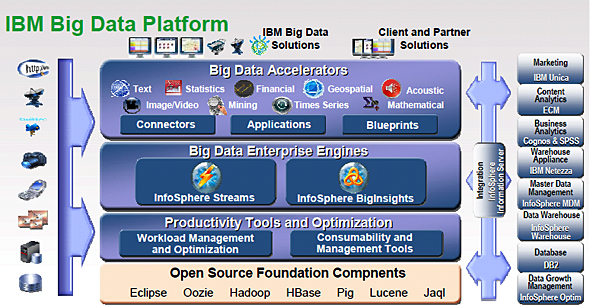
Big Data Platformは、さまざまな製品やソリューション、各種機能が組み合わさって1つの情報活用基盤となっている。トータル提供できる点がIBMの強みだとミルズ氏は言う。その中で中核となる製品が、Apache Hadoopを用いて大量データ分析システムを構築するミドルウェア「InfoSphere BigInsights」と、CEP(Complex Event Processing:複合イベント処理)/ストリーム処理ソフトウェア「InfoSphere Streams」である。両製品は新版が発表されており、機能のさらなる強化を実現している。同社はこの基盤によって、情報活用における顧客課題にまとめて対応していくとしている。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 BM Information On Demand 2011 Report:金融危機を読みきったビジネスアナリティクス
BM Information On Demand 2011 Report:金融危機を読みきったビジネスアナリティクス
「ビッグデータ」の中核となるべき製品群をラインアップする、IBMソフトウェアブランドの年次カンファレンスが開幕した。 IBM Information on Demand 2010 Report:洞察力――進化を遂げる企業の情報活用
IBM Information on Demand 2010 Report:洞察力――進化を遂げる企業の情報活用
ラスベガスで開催中の「Information on Demand 2010」では、従来型の「情報の見える化」や「情報管理」にとどまらない新たな情報活用の羅針盤が示された。- IBM Information on Demand 2010 Report:ボーイングなどで導入、IBMがビジネス分析ツールの最新版を発表
- Weekly Memo:ビッグデータ時代の悩ましき問題
- Oracle OpenWorld 2011 Report:「ビッグデータ」時代への回答