| News | 2002年2月13日 06:22 PM 更新 |
ハイパースレッディング――その仕組みと未来図(1)
プロセッサの“利用されていないハードウェア資源”を有効活用するハイパースレッディングは,Intelにとってコストをかけずパフォーマンスを向上させる「切り札」ともいえる。この新アーキテクチャーがどのように機能し,Intelがどのような将来図を描いているのか,より詳細に解説しよう。
1つのプロセッサを2つのプロセッサに見立て,異なる2つのプログラムスレッドを効率よく複数パイプラインに振り分けて実行する「ハイパースレッディング(Hyper-Threading)」。この新機能を搭載するIntelのXeonプロセッサが先週,発表された。
従来のプロセッサは,プロセッサに入力される命令レベルで並列実行できるものを,複数パイプラインに分割し並列実行していた。だが,この新アーキテクチャでは,OS側で依存関係のない仕事を2つ同時に受け付けることで,プロセッサ内部の資源の利用効率を上げることができる。
スーパースケーラとの違いは何か
Intelは初代Pentiumでx86プロセッサにスーパースケーラ技術を採用して以来,この機能を強化してきた。スーパースケーラとは,命令を実行するための処理パイプラインを複数持ち,演算結果による依存関係を持たない命令を同時に実行するアーキテクチャのことをいう。
このため,プロセッサ内部には命令バッファが存在し,実行命令(Pentium IIIやPentium 4の場合はx86命令を分解したμOPsという単純命令に分解される)を複数バッファにプールしたあと,都合の良い順番で可能な限り並列に命令を自動処理していく。実行後は結果を正しい順番で出力するため,さらに並べ替えも行っている。
こうした複雑な処理を行っているにもかかわらず,並列に実行される平均の命令数は(理想的なプログラムでも)2つ程度にしかならない。ちなみにPentium 4アーキテクチャには4つの整数演算処理用パイプラインとロード用,ストア用ユニット,それに浮動小数点演算用(MMX,SSE処理含む)パイプラインに浮動小数点演算用ロード/ストアユニットが組み込まれている。つまり,ほとんどの実行ユニットは同時に使われていないことになる。
そこで利用されていないハードウェア資源を利用し,高速化を行うのがハイパースレッディングである。ハイパースレッディングは,1つのプロセッサで2つの独立したプログラムスレッドを実行し,実行ユニットの隙間を互いが埋めあわせることで実行ユニットの利用効率を向上させる。
ハイパースレッディング対応プロセッサはソフトウェアから2つのプロセッサが存在するように見え,OSはひとつのプロセッサに2つのスレッドを割り当てる。プロセッサ側には2つのスレッドを同時実行できるように2系統のレジスタセットが割り振られるため,各スレッドのプログラムは他方のスレッドから影響を受けることなく,同時実行が可能になるわけだ。
本来は1つしかないプロセッサコアを2つのスレッドで共有するため,デュアルプロセッサやデュアルコア(プロセッサ内部でコアを二重化することにより1チップでデュアルプロセッサを実現する手法)よりも,絶対的な性能には劣ることになる。
しかし,2倍の物量を投入するデュアルプロセッサや,チップ上に2倍のトランジスタを集積しなければならないデュアルコアに比べると,ハイパースレッディングは最小限のトランジスタ数増加で最大30%性能が向上する。よりコストエフェクティブであると言うことができる。
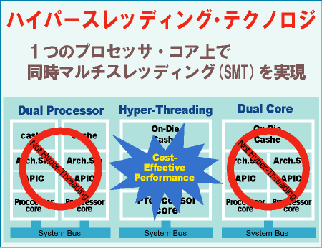 |
| デュアルプロセッサでも,1チップに2つのプロセッサを実装する方法でも,増えた分だけコストが上昇する。しかし,ハイパースレッディングでは,ハードウェアの追加が最小限でいいのでコストパフォーマンスが良い。 |
ハイパースレッディングの能力を活かすためにはOSがマルチプロセッサをサポートしている必要があるが,各OSベンダーはハイパースレッディング対応プロセッサであっても物理的に1個のプロセッサとしてライセンスをカウントするとしている。
このため,ハイパースレッディング対応プロセッサを2個搭載するシステムはOSから4個のプロセッサが動作するように見えるが,2プロセッサまでのOSライセンスで利用することが可能である。
これからの性能向上のために
マイクロプロセッサの性能向上には,ある程度“物量”を投入することで対処しなければならない面がある。高速なx86プロセッサを作るためには,複雑なx86命令を高速でデコードし,パイプラインの段数を増やし,パイプライン数を増やす。さらにそれらが効率的に動作するように,分岐予測の精度を高めたり,並列度向上のための複雑なロジックを内蔵させ,さらに大量のキャッシュメモリを内蔵させる必要があるのだ。
そしてアーキテクチャの進化に伴って,物量投入による効果も少しづつ薄れてきているのが実情だ。大量のトランジスタを実装し,プロセッサのアーキテクチャを改良しても,かつてのように倍々ゲームでパフォーマンスは増えていかない。Intelはプロセッサのハードウェアリソース利用効率が,現在の35%から将来的にも上がっていかないと予測しているという。
こうしたx86プロセッサの現状に対して,さらにパフォーマンスを上げるために複数スレッドを同時並行処理するためのアーキテクチャが,複数個のプロセッサを用いる「マルチプロセッサ」や,複数コアを1チップに統合する「デュアルコア」といった発想だ。特にバックエンドのサーバではこうした手法が有効であるため,サーバのスケーラビリティをアップさせる手段としてマルチプロセッサはポピュラーである。
しかし,こうした手法も結局は物量でパフォーマンスを引き上げているに過ぎず,むしろトランジスタあたりの処理効率という面では落ちる。少しでもパフォーマンスを引き上げたい分野は別として,一般論ではコスト対効果が悪すぎるのだ。さらに将来を見据えると,1つのプロセッサで処理の効率を向上させる方がいい。
せっかく使われていない実行ユニットが数多くあるのだから,ひとつのプロセッサで処理効率を向上させた上で,さらにデュアルプロセッサなどの手段を講じればいいのである。
これらを図解したのが,リソースの活用の様子を示した模式図だ。
![]()
ITmediaはアイティメディア株式会社の登録商標です。