特集・音声言語インタフェース最前線
自然な音声作る「WaveNet」の衝撃 なぜ機械は人と話せるようになったのか(1/2 ページ)
2017年、米Googleや米Amazonなどの「スマートスピーカー」と呼ばれるデバイスの普及が日本で始まった。例えば、「ねえGoogle、今日の予定は?」と話しかけると、カレンダーアプリに入力していた予定を流ちょうな日本語で読み上げてくれる。中に人がいるわけではない。デバイスが人の声を認識し、応答となる声を合成しているのだ。
 米Amazonの「Amazon Echo」と米Googleのスマートスピーカー「Google Home」
米Amazonの「Amazon Echo」と米Googleのスマートスピーカー「Google Home」
このデバイスが音声で応答するために使用しているコアの技術は、「音声認識」と「音声合成」という2つの技術だ。音声認識は人の声の波形を機械で処理し、どんな文であったかを推定する技術。音声合成は与えられた文やデータから、人が話す音声を合成する技術だ。
ここに、音声認識で推定した文に対して適切な応答文を出力する「対話制御」という技術が加わり、「人の話を聞いて適切な応答を音声で返す」という一連の動作を実現している。
音声認識・合成ともに、コンピュータを利用した研究は1950年ごろから始まったとされている。一般的になったのは1990年代後半からで、音声認識であれば「Dragon naturally Speaking」(ドラゴンスピーチ、1997年)という音声書き起こしソフトや、コンシューマーゲームであれば「ピカチュウげんきでチュウ」(1998年)や「シーマン」(1999年)を思い浮かべる人もいるかもしれない。
音声合成であればコールセンターの機械応答、ボーカロイド「初音ミク」(正確には歌声合成)、ニコニコ動画の「ゆっくり実況」などで使用される「SofTalk」など、それぞれ以前から一般消費者が触れられる技術ではあった。
一方で、音声認識の精度の甘さや、合成された音声の「機械っぽさ」を覚えている人も多いだろう。しかし、スマートスピーカーでは(完全とはまだ言えないが)、人の声を精度良く認識して、人の声と遜色ない合成音声で返答するということをやってのけている。
ここにはどんなブレークスルーがあったのか。音声情報処理について研究する、名古屋大学の戸田智基教授に話を伺った。戸田教授は、「音声合成については『WaveNet』の登場が衝撃的だった」と語る。
囲碁AI「AlphaGo」開発元が作った「WaveNet」とは
WaveNetは、人工ニューラルネットワークによる音声合成アルゴリズムの1つで、米Googleのスマートスピーカー「Google Home」や、Android端末に搭載される「Google アシスタント」の合成音声として使用されている。開発したのは、囲碁で世界トップの実力を持つプロ棋士に勝利したAI「AlphaGo」を作った、Google傘下のDeepMindだ。

WaveNetのサンプルボイスを聞くと分かるが、従来の合成音声からかなり「自然」な発声に改善されている。
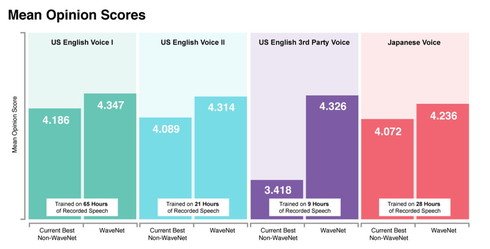 聴覚上の音声の品質を評価する「平均オピニオン評点」(最低が1、最高が5)によるWaveNet(2017年10月の改良版)の評価。既存の音声合成アルゴリズムより高評価で、人の声のスコア(4.667)にも迫るという
聴覚上の音声の品質を評価する「平均オピニオン評点」(最低が1、最高が5)によるWaveNet(2017年10月の改良版)の評価。既存の音声合成アルゴリズムより高評価で、人の声のスコア(4.667)にも迫るという
戸田教授は「WaveNetのようなものが出てくるのはあと10年かかると思っていた」と、その衝撃を振り返る。
音声を合成するのに必要なこと
そもそも、人の声を合成するとはどういう作業だろうか。戸田教授は「『声の高さの成分』と『共振特性』(音色)という2つの特徴を推定すること」だという。
 名古屋大学の戸田智基教授(本人提供)
名古屋大学の戸田智基教授(本人提供)
「人間では声帯でブザー音が生成されて、それが口を通る時に共振が発生する。共振の特性が付与されてその人の声になる。テキストからの音声合成は、これを時々刻々と推定して波形を生成するということです」(戸田教授)
従来は、推定のために発声メカニズムの数理モデルが用いられていた。しかし、この数理モデルで自然な音声を出すには「ある困難」があったという。
「例えば、私が2回『あいうえお』と言ったとします。言った文は同じですが、この2回の波形を実際に比べると違うものになっています。この違いを『ゆらぎ成分』というのですが、これを音声合成で復元するのはとても難しいことでした」(戸田教授)
「ゆらぎ」がない声は、こもったような声に聞こえるという。サンプルした声を平均化したような声で、「口の動きを平均化すると口の動きが小さくなり、肉声感がなくなる、そんなイメージ」だと戸田教授はいう。
数理モデルによる音声合成では、「ゆらぎ」に対応するために確率的なアプローチがよく用いられるが、不確実な「ゆらぎ」のみを記述する確率モデルを構築するのは難しい。いかに精度良く「ゆらぎ」を付与するか──そういった研究に戸田教授は以前から注力していたが、それでも10年はかかるだろうと試算していた。
そんな中、2016年に現れたWaveNetが、精度良くゆらぎを表現した「自然な音声」を実現した。「こんなことができるとは多分皆思っていなかったし、私も思っていなかった」と戸田教授はその衝撃度合いを表現する。
鍵は音声を「点」として考える“ディープラーニング”
WaveNetはどのように「自然な音声」を作っているのか。戸田教授はインフラ的な側面として「データ量と計算能力」と、アルゴリズム的な側面として「音声を『点』の時系列として捉え、ディープラーニングに入力するということ」があると指摘する。
ディープラーニングを音声情報処理に使えるようになった背景にも関わるが、近年の音声認識・合成技術が改善された大きな理由には「データを大量に集められるようになったこと」と、「大量のデータを処理する計算が可能になったこと」が挙げられる。
ディープラーニングの典型的な応用例では、基本的にはあるデータをディープニューラルネットワーク(DNN)に入力し、出力データを対応する教師データと比較し、出力データと教師データの差が小さくなるように繰り返し学ばせる作業を行う。従来の機械学習で研究者が設計していた「特徴量」(データの特徴を表す数値)を設計する必要がない代わりに、精度の良い学習のためにはサンプルとなるデータを大量に用意しなければいけない。
大量のデータをDNNで学習するには大量の計算を行わなければならず、ディープラーニングの成功にはデータ量と計算機の性能を両立しなくてはいけない。今、ディープラーニングが華々しい成果を上げている画像処理も、インターネットの発達によるネット上の大量の画像データや計算機の発達があってこそのものだ。
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia NEWSに関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
本日の新着記事
アクセスランキング
-
1
陸自が「イオンモール熊本」内部をドローン撮影 防衛省が映像公開
-
2
熊本「通れた道」マップ、トヨタが公開 ホンダも「通行実績情報マップ」
-
3
PayPayアプリで熊本地震への寄付が可能に 最短3ステップ・1円から
-
4
「Xが情報収集に役立たない……」熊本地震で不満の声続出 「Twitterを返して」
-
5
TSMC熊本工場、段階的に通常操業へ 熊本の地震で一時中断、従業員の無事確認 台湾報道
-
6
熊本で非常時Wi-Fi「00000JAPAN」発動中 KDDIが無料開放、他社ユーザーも利用可
-
7
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
8
紙にもiPadにもそのまま書ける驚きのペン、ゼブラ「STYLUS 2WAY」開発秘話 “失敗”を逆手にとったアイデアとは?
-
9
Anthropicのミュトス、暗号アルゴリズムの新たな攻撃法を発見――耐量子署名「HAWK」の強度を半減
-
10
「痺れるほどにミスを繰り返す」Gemini 3.6 Flashは変わった? 公開から1週間、当初のおバカ回答を今検証する
ITmedia NEWS SNS
インフォメーション
注目情報をチェック
ITmediaNEWSをフォロー
あなたにおすすめの記事PR