AWS障害、複数のアベイラビリティゾーン利用でも影響 AWSが説明を修正
AWS東京リージョンの大規模障害について、AWSが追加の報告を行い、複数のアベイラビリティゾーンで稼働していたアプリケーションでも障害の影響があったことを認めた。
この記事は新野淳一氏のブログ「Publickey」に掲載された「AWS、複数のアベイラビリティゾーンで稼働していたアプリケーションでも大規模障害の影響があったと説明を修正。東京リージョンの大規模障害で追加報告」(2019年8月29日掲載)を、ITmediaNEWS編集部で一部編集し、転載したものです。
8月23日午後に発生したAWS(Amazon Web Services)東京リージョンの大規模障害について、AWSは追加の報告を行い、複数のアベイラビリティゾーンで稼働していたアプリケーションでも障害の影響があったことを認めました。
下記は大規模障害の報告ページです。赤枠で囲った部分が、8月28日付で追記されました。

当初の報告は、障害の原因が空調装置のバグであり、それが引き金となってサーバのオーバーヒートが発生したことなどが説明されていました。
そして障害の影響範囲は単一のアベイラビリティゾーンに閉じており、
複数のアベイラビリティゾーンでアプリケーションを稼働させていたお客さまは、事象発生中も可用性を確保できている状況でした。
と説明されていました。
複数のアベイラビリティゾーンでも障害の影響を受けた
今回追記された部分を見ていきましょう。
まず、当初報告されたAmazon EC2、Amazon EBS以外のサービスにも影響があったことが示されました。
この影響は当該 AZ の Amazon EC2 および Amazon EBS のリソースに対するものですが、基盤としている EC2 インスタンスが影響を受けた場合には、当該AZの他のサービス(RDS、Redshift、ElastiCacheおよびWorkspaces等)にも影響がありました。
そして、複数のアベイラビリティゾーンで稼働していたアプリケーションであっても障害の影響を受けたと、次のように説明しています。
お客さまと今回のイベントの調査をさらに進めたところ、個別のケースのいくつかで、複数のアベイラビリティゾーンで稼働していたお客さまのアプリケーションにも、予期せぬ影響(例えば、Application Load Balancer を AWS Web Application Firewallやスティッキーセッションと組み合わせてご利用しているお客さまの一部で、想定されるより高い割合でリクエストが Internal Server Errorを返す)があったことをAWSでは確認しております。
複数アベイラビリティゾーンで稼働していたアプリケーションへの影響はあくまでも「お客さまの一部で、想定されるより高い割合でリクエストがInternal Server Errorを返す」といった程度であることには留意すべきですが、当初の「複数のアベイラビリティゾーンで〜(中略)〜事象発生中も可用性を確保できている」という説明を一部修正するものだといえます。
具体的にどの程度の割合でInternal Server Errorが発生したのか、そして何よりも「ではどうすればこの影響を防ぐことができたのか」については、
AWSでは、個別の問題についての詳細な情報を、影響を受けたお客さまに直接、共有を行う予定です。
と、個別対応するという歯切れの悪い説明になっています。
これまでAWSは、障害が単一のアベイラビリティゾーンに閉じているかぎり、アプリケーションを複数のアベイラビリティゾーンに対応させれば可用性を確保できると説明してきました。
しかし今回、一部とはいえその説明が有効ではない事象が実際に東京リージョンで発生しました。ネット上では「どうすれば今回のような障害に対応できるシステムを設計し得るのか?」について、多くの議論や意見が表明されており、真剣なAWSユーザーであれば誰でも、そのオフィシャルな答えを求めています。
現在はまだAWS自身が調査中なのかもしれませんが、なぜ今回のような事象が起きたのか、今後可用性を確保するにはどのような対策をとるべきなのか、などについて、AWSは調査後にあらためて広く説明するべきではないでしょうか。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 AWS障害、“マルチAZ”なら大丈夫だったのか? インフラエンジニアたちはどう捉えたか、生の声で分かった「実情」
AWS障害、“マルチAZ”なら大丈夫だったのか? インフラエンジニアたちはどう捉えたか、生の声で分かった「実情」
AWSの障害に、各社はどのように対応したのか。ITmedia NEWS編集部では問題に直面した企業やエンジニアに聞き取り調査を行った。生の声から、実情が見えてきた。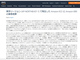 AWS、東京リージョン23日午後の大規模障害について詳細を報告。冷却システムにバグ、フェイルセーフに失敗、手動操作に切り替えるも反応せず
AWS、東京リージョン23日午後の大規模障害について詳細を報告。冷却システムにバグ、フェイルセーフに失敗、手動操作に切り替えるも反応せず
2019年8月23日金曜日の午後、AWS東京リージョンで大規模障害が発生した。これについて、AWSが日本語での詳しい報告を発表した。 AWS障害、大部分の復旧完了 原因は「サーバの過熱」
AWS障害、大部分の復旧完了 原因は「サーバの過熱」
米AWSは午後8時18分、クラウドサーバの復旧がほぼ完了したことを明らかにした。制御システムの障害により、サーバの温度が上がりすぎたことが原因だったという。