
「GPUを遊ばせない」が鉄則 AIインフラ構築のボトルネックをどう打破するか 記者がハンズオンを体験
AI活用の浸透によって、インフラ戦略はオンプレミス回帰の流れが生まれている。そんな中、SB C&Sが検証環境と構築ノウハウの提供をスタート。記者がハンズオントレーニングを体験した。
AIの波が企業活動の隅々にまで押し寄せ、AIインフラの在り方に変化が起きている。「取りあえずクラウドで」の定石が、ランニングコストやセキュリティ対策、パフォーマンスの壁に直面して揺らいでいる。
しかし、クラウド以外でAIインフラを構築するには従来のITシステムと異なる多くの要件を満たす必要がある。構築・運用に必要な知見を持つエンジニアは少なく、日本でAIインフラを整備するハードルは極めて高い。
この状況を打破するため、SB C&Sが「C&S AI INNOVATION FACTORY」を2025年7月にスタートした。IDCフロンティアが運営する東京・府中データセンターにNVIDIAのサーバやスイッチ、ストレージを用意し、AIインフラの構築から活用まで検証できる環境を整備。データセンターは液冷技術など将来を見据えた冷却設備を有し、AIワークロードに十分対応できる点が特徴だ。
 「C&S AI INNOVATION FACTORY」のサーバを設置する、東京・府中のデータセンター(提供:IDCフロンティア)
「C&S AI INNOVATION FACTORY」のサーバを設置する、東京・府中のデータセンター(提供:IDCフロンティア)
こうした環境を用いて、「C&S AI INNOVATION FACTORY」はデモツアー、ハンズオントレーニング(以下、ハンズオン)、機器貸し出し、コラボレーションのサービスを提供している。特にハンズオンは反響が大きく、GPU環境の基本を学ぶ「Basic」、複数ノードのクラスタ構成を把握する「Advanced」、AIモデルの開発・活用方法をインフラの観点から深める「Master」を用意している。
ITmedia AI+編集部は前回のBasicに続き、Advancedを受講する機会を得た。本稿はその模様をお伝えする。
GPU選定の基準は「GPUメモリの容量」にあり
講義は、AIインフラの構成要素で重要なGPUの説明から始まった。
「AIインフラのサーバ構成は、GPU選定が全てのアプローチの基礎です」と語ったのは、講師を務めるSB C&Sの幸田章氏(ICT事業本部 技術本部 技術統括部 第2技術部 1課)だ。
ディープラーニングは膨大なデータを数値化し、推論の試行とパラメーターの微調整を繰り返すプロセスだ。これに使われるのがGPUで、CPUが少数の高性能コアで複雑な処理を行うのに対し、GPUは多数の低性能コアで大量の簡単な処理を並行して効率的に実行する。
では、GPUは何を基準に選べばよいのか。
幸田氏は「目的に合わせてGPUの型番を選び、演算規模に合わせてコア数を決めます。そのGPUを搭載できるサーバを選び、CPU、メモリをサイジングする流れです」と説明した。
最近は、「NVIDIA RTX PRO 6000 Blackwell Server Edition」が注目されている。GPUメモリは96GBで、学習、推論、3Dグラフィックスなどに対応する万能型だが、特に推論処理の性能の高さが注目される傾向にある。他にも「NVIDIA H200 NVL」は141GBのGPUメモリを搭載しており学習、推論に加えてHPCにも対応可能であり、倍精度(64ビット)の浮動小数点演算に対応している。「NVIDIA L40S」は万能型で安価なため、最新世代ではないが人気が高い。「NVIDIA L4 Tensor コア GPU」は小型かつ低消費電力で、1Uサーバに収まるのが特徴だ。
サーバは一般的なメーカーの主力モデルで問題ない。OSは「Ubuntu」や「Red Hat Enterprise Linux」(RHEL)がよく使われる。AI領域はオープンソースのソフトウェアが盛んに活用されており、商用環境においても無償のUbuntuが採用されるケースは珍しくない。GPUドライバはNVIDIA製品を利用。コンテナエンジンは「Docker」が使われることが多いが、Red Hat環境では「Podman」が使われる。「NVIDIA Container Toolkit」が、コンテナからGPUを利用できるように仲介する役割を果たす。
演習では、ブラウザで仮想デスクトップ環境にアクセスしてターミナルから「NVIDIA DGX H200」へログイン。コマンドを入力すると、8基のGPUが搭載されていることを確認できた。
GPUの性能を最大化する低遅延、高速ネットワークの重要性
続いて、ネットワークの説明があった。GPUがAIインフラの“心臓”ならば、ネットワークは“血管”に当たる。
AIインフラにおけるネットワークは、ノード間通信とストレージ接続を担う。
ノード間通信で威力を発揮するのがInfiniBandだ。輻輳(ふくそう)によるパケットロスが生じず、低遅延と広帯域幅が特徴で、200Gbps、400Gbpsに加えて、800Gbpsといった超高速通信も実現している。CPUやOSカーネルを介さずにデータを渡す技術「RDMA(Remote Direct Memory Access)」をサポートしており、転送速度を大幅に向上させる。
イーサネットも進化を続けている。400ギガビットイーサネット(GbE)、800GbEといった高速規格が登場し、NVIDIAによるRoCE(RDMA over Converged Ethernet)の弱点の補強によって、イーサネット上でのRDMA利用もノード間接続の現実的な選択肢となった。
ネットワーク設計は、ノード間通信とストレージ接続に最適なスイッチとトポロジーを選ぶことがポイントだ。
演習は、複数のサーバを使ったマルチノード環境で行った。複数のサーバで分散学習を体験し、ノード間の通信状況を確認する。ネットワークの状態をチェックし、正常に通信できているか、十分にGPUやネットワークの性能が発揮されているかを検証する作業は、実務に必須のスキルだ。実機を操作しながら、クラスタ構成の理解をより深められた。
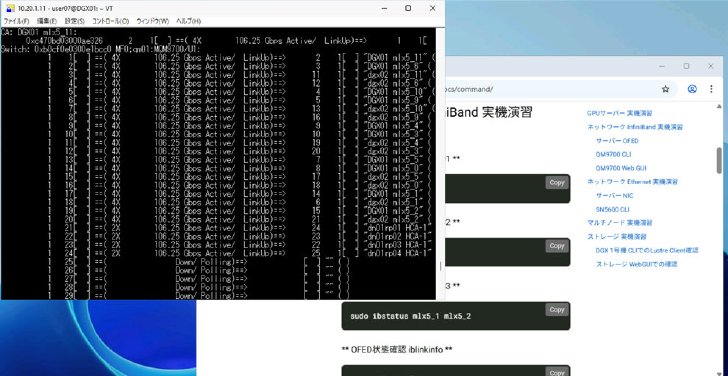 InfiniBandのステータスで、コマンドを入力し、スイッチとポート、レーンの速度、ノードなどをチェック《クリックで拡大》
InfiniBandのステータスで、コマンドを入力し、スイッチとポート、レーンの速度、ノードなどをチェック《クリックで拡大》
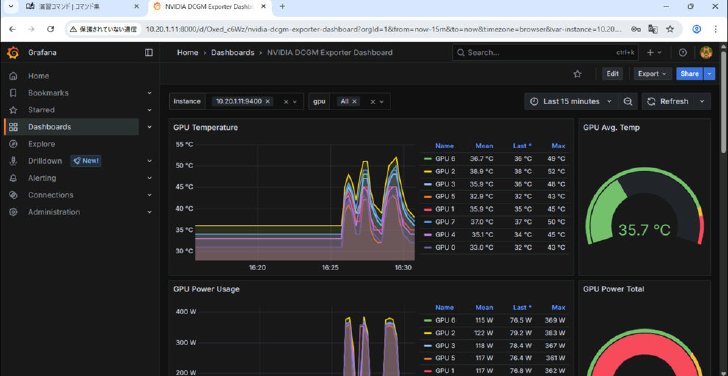 マルチノード環境の演習では、まず1号機でダッシュボードツール「Grafana」でGPUのステータスを確認した《クリックで拡大》
マルチノード環境の演習では、まず1号機でダッシュボードツール「Grafana」でGPUのステータスを確認した《クリックで拡大》
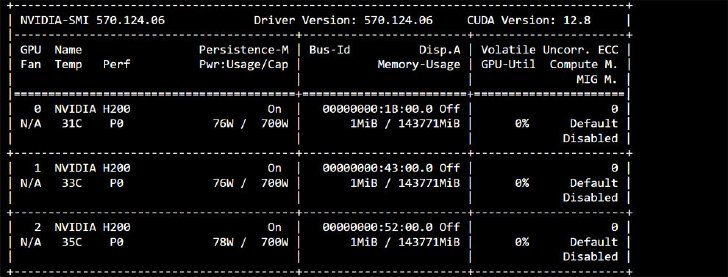 続いて2号機でGPUをモニタリングした《クリックで拡大》
続いて2号機でGPUをモニタリングした《クリックで拡大》
GPUの待機を解消する、並列ファイルシステムと「GPUDirect Storage」
計算リソースとネットワークが整っても、データを供給するストレージがボトルネックになると高価なGPUはアイドリング状態に陥る。「GPUを遊ばせないこと、これがAIインフラの鉄則です」と幸田氏は強調した。
これに応えるのが並列分散ファイルシステムであり、その代表格の一つが「Lustre」(ラスター)だ。Lustreはメタデータサーバ(MDS)とオブジェクトストレージサーバ(OSS)を分離して、ファイル情報とデータを分けて管理する。複数のOSSに並列でアクセスできるので読み書きが高速化する。スケーラビリティが高く、ストレージの追加で性能を向上させられるというメリットもある。
性能への要求が厳しいケースでは、GPUDirect Storageの利用が強く推奨される。ストレージのデータはOSのカーネル(CPUやメモリ)を経由してGPUに渡されるのが一般的だが、GPUDirect StorageはストレージからGPUにデータを直接転送できる。CPUのボトルネックを解消して、処理速度を大幅に上げられる。
演習では、Lustreベースでシンプルな操作画面が特徴の「DDN EXAScaler」(以下、EXAScaler)を使用した。幸田氏は「細かい設定も含めてDDNがセットアップしてくれるので、ユーザーの負担は少ないでしょう」と説明した。
演習では、EXAScalerの使い勝手を確認できた。使用感は一般的なLinuxの外付けストレージと変わらず、特殊な操作は不要だ。設定ファイル「fstab」の記述も、通常のストレージマウントと大差ない。
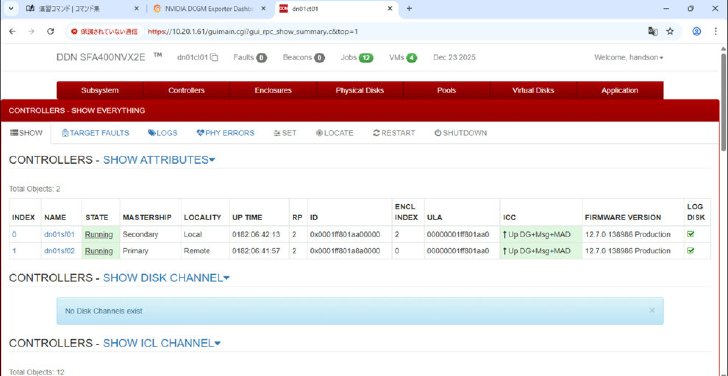 DDN EXAScalerの実機演習。データを読み書きするコンポーネント「Controller」のステータスを確認した《クリックで拡大》
DDN EXAScalerの実機演習。データを読み書きするコンポーネント「Controller」のステータスを確認した《クリックで拡大》
水冷技術が変えるデータセンター
AIインフラの構築で見過ごせないのが、データセンターの要件だ。特に電力と冷却は、GPUサーバを安定稼働させる上で大きな壁になる。
一般的なITシステムは1ラック当たり約6キロワットを中央値として数キロワット上下する程度だが、GPUサーバを用いるシステムは20キロワット、あるいはそれ以上必要となるケースがある。
電力消費の増加を受けて、冷却技術は進化している。空冷による冷却は1ラック当たり6キロ~17キロワット程度が限界だが、水冷技術を使えばより高い電力消費に対応可能だ。ラックの後方ドアに水を流して冷却するリアドア型水冷はその倍ほどの電力消費に対応できる上、サーバ本体に影響がないため導入しやすい。
より強力なのが、直接液体冷却(DLC:Direct Liquid Cooling)だ。サーバ内部のGPUやCPUに液体を循環させ、熱を効率的に排出する。専用サーバが必要だが、80キロワット程度、あるいはそれ以上の電力消費と発熱に対応できる。サーバ内部には銅板のコールドプレートを設置して冷たい液体を流入させ、温まった液体を排出する。冷却効果がさらに高いのは、電気を通さない液体にサーバを丸ごと浸す液浸冷却だが、液体の扱いが難しくコストもまだまだ高くなりがちであるため、現段階での国内の導入実績は多くない。
幸田氏が紹介したのが、IDCフロンティアの高負荷ハウジングサービスだ。リアドア型水冷を採用し、ほぼ全ての空冷式GPUサーバを設置できる。2025年7月には最大150キロワット対応のDLCハウジングサービスも開始した。「データセンターの選定は非常に重要です。電力と冷却の要件を満たせるかどうかで、導入できるシステムが決まります」
AIインフラを構築し、運用する力
質疑応答をもって、ハンズオンは終了。受講者にハンズオンに参加したきっかけを尋ねると「これまでハードウェア領域に手を出せていませんでした。オンプレミス回帰の流れがあり、われわれも対応する必要があると感じて受講しました」と語った。
別の受講者は「初めて知る用語が出てきて、良い勉強になりました。業務はクラウドが多くハードウェアに触る機会が少なかったので、ハンズオンで勉強する機会ができて有意義でした。社内でも勉強会をしたいです」と意欲を見せた。
実機に触れる機会の少ないエンジニアにとって、ハンズオンは体系的な知識を習得できる貴重な場だ。クラウドが専門のエンジニアも、オンプレミスAIインフラの全体像を把握することで顧客への提案の幅が広がるだろう。今回参加したAdvancedの他、Masterコースも機会があれば受講してみたい。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事



SB C&S株式会社
アイティメディア営業企画/制作:ITmedia AI+編集部/掲載内容有効期限:2026年2月18日



