「NoOps」を実現できる時が来た! NoOpsとは運用の“うれしくない”ことをなくすこと:NoOps Meetup Tokyo #1(3/4 ページ)
NoOpsとは運用をなくすことではなく、運用の「うれしくない」ことをなくすこと――。都内で開かれた「NoOps Meetup Tokyo」で行われたセッション「15分で分かるNoOps」をダイジェストで紹介します。
NoOpsの作り方
NoOpsの実現には「復元力(Resiliencability)」だけではなく、障害が起きたときにそれをいかに早く検知する観察力「Observability」も必要です。ログを見て検知するのでは遅い。そして、障害を検知したら、システムを再構成する能力「Cofigurability」も必要です。
仮に、クラウドのあるリージョンが死んだとしましょう。それを検知してオンタイムで別のリージョンで同じシステムを構成して復元する――ということも現在では可能です。データさえ同期させておけば、検知して、構成して、復元できるのです。
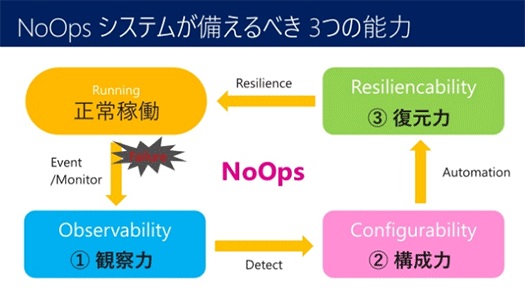
こうしたシステムを実現する上で一番大事なのは、仕様には書かれていない観察力、構成力、復元力を兼ね備えたシステムやサービスを採用すること。これには目利きが必要です。
ミドルウェアやインフラが回復力を持っていても、例えばバッチ処理を回しているときに落ちました、というときにはインフラだけ復元させてもダメで、バッチ処理のどこで落ちたか、どこから再実行するかといった人力の作業が処理の回復に必要です。だからこそ、アプリケーション側にも回復力を持たせる必要があります。

そのための原則として、粒度はできるだけ小さくします。1時間もかかる処理は復元が難しくなるでしょう。処理はステートレスで。ステートを持たせても消えてしまいます。そして非同期処理。同期処理だと全てのプロセスが連鎖していくので、途中で落ちたら最初からやり直しです。
最後に一番大事なのが処理の冪等(べきとう)性を担保すること。どのサーバで何回リトライしても、正常終了したら、結果は同じ場所に同じ値が書き込まれる。この冪等性を全ての処理で担保する。さらに追跡可能性という意味で、処理結果を記録します。
これらの要件の目指すところは、シンプルなリトライです。落ちました、それならリトライする。それでダメなら別サーバでリトライする、それでもダメなら別リージョンでリトライする……それで大丈夫な設計にしていきたいということです。

Copyright © ITmedia, Inc. All Rights Reserved.