9.6.3 クエリの見直し
「遅いクエリ」が明確になれば,遅い原因を究明しなければならない。そのために,クエリ自身に原因が潜んでいないか,クエリ自体を見直さなければならない。すなわち,次のような観点からクエリ全体を検証する。
○大きな結果セットを要求していないか
クライアントに返される結果セットが大きい場合に問題となるのは,ネットワークリソースを消費することである。特に多数のクライアントが接続されている場合や,意思決定支援システムなどのように多くのデータをクライアントに返してクライアントでデータを分析する場合には,ネットワークがボトルネックになり得る。
○不要な行や不要な列を取り出していないか
クライアントに多量のデータ行を返し,クライアントアプリケーションでそのなかから必要なデータを抽出して処理するようなアプリケーションを作成している場合がある。あるいは,データ行の一部の列しか処理する必要がないのに,行全体をクライアントに返して,それをクライアントアプリケーションで処理するように設計されているクライアントアプリケーションがある。このような設計では,ネットワークリソースに加え,クライアントのプロセッサリソースやメモリリソースを浪費することになりかねない。
○同じデータをくり返し要求していないか
1つのトランザクション内で同じデータをくり返しSQL
Serverに要求している場合には,クライアント,ネットワーク,サーバーの各リソースを余分に消費することになる。もし同じデータをくり返し参照する必要があるならば,クライアントのローカルに一時的に格納するなどの方法を検討すべきである。
○1つのSQLステートメントで実行できる処理を複数のSQLステートメントに分割していないか
単純に1つのSQLステートメントで実行できる処理を複数のSQLステートメントに分割してSQL
Serverに処理させると,分割した回数だけネットワークを介してSQL
Serverに送信され,解釈され,実行され,そして結果が返される。その結果,システムの全リソースを余分に消費することになる。このような場合は,1つのSQLステートメントでクエリを実行すべきである。
○4つ以上のテーブルの結合を多用していないか
SQL Server 7.0では最大32テーブルまで結合することができる。しかし,性能を考慮すれば,結合するテーブル数はできるだけ3個または4個以内に抑えるべきである。リレーショナルエンジンは,各テーブルの組み合わせのそれぞれについて,どの組み合わせが最適なコストであるかを評価する。もし3つのテーブルを結合させたならば6通り,4つのテーブルを結合させたならば24通り,6つのテーブルを結合させたならば720通りの組み合わせができる。当然ながら,その評価には時間がかかってしまう。また,結合させるテーブルの数が増えれば,その分だけディスクI/Oも増すことになる。
○特定のテーブル,行,列に対して更新処理を集中させていないか
特定のデータにアクセスが集中することによって,ホットスポットが発生する。そのため,先行トランザクションの処理が完了するまで処理が停止してしまうことになる。
○排他制御は適切か
多数のアプリケーションが同時にSQL
Serverにアクセスする場合には,データベースの一貫性を確保するためにロックによる排他制御が必要である。しかし,不適切なロックを指定すると,ほかのアプリケーションのアクセスを長時間ブロックすることになり,最悪の場合はデッドロックを招くことにもなりかねない。必要以上に大きなロックを設定したり,長時間ロックを保持したままで解放しなかったりといったことは避ける必要がある。
○ストアドプロシージャが適切に使用されているか
数十ステップから数百ステップのSQLステートメントから構成されるクエリであれば,ネットワークのリソースを消費するので,ストアドプロシージャを使用してSQL
Serverで処理させ,ネットワークリソースの消費を抑制させるとよい。また,ユーザー間で共通して,かつ頻繁に利用するクエリは,ストアドプロシージャとして定義することで,コンパイルの時間を削減し,クエリの実行計画をSQL
Serverのキャッシュに保持できる可能性が高くなる。
○ORDER BY句やGROUP BY句を利用した複雑なビューを使用していないか
ORDER BY句やGROUP BY句を利用すると,プロセッサ,メモリ,ディスクなどのリソースを消費する。ORDER
BY句は,インデックス順でなかったり,利用可能なインデックスがなかったりすると,ソートが必要となり,そのためのオーバーヘッドが発生する。またGROUP
BY句も,グループ化のために重複行をソートして削除するなどのオーバーヘッドが発生する。結果セットをソートしたりグループ化したりする作業領域としてtempdbデータベースを使用する場合には,ディスクI/Oが増加するので,性能が低下することもある。
クエリ全体を検証したら,次にクエリを構成する個々のSQLステートメントに含まれるWHERE句(条件句)を検証する。
○WHERE句に指定した条件式は適切か
たとえば,WHERE句に論理和(ORまたはIN)や否定比較演算子(NOT,<>,!=)などを使用していないかを検証する。これらが指定されている場合,テーブルスキャンが選択される。
また,条件式で比較するデータの型が互いに一致しているか否かを検証する。データ型が一致していなければ,変換しなければならないため,時間がかかる。
○CONVERT()関数を使用していないか
CONVERT()関数は,さまざまな特殊データ形式を取得するときに使用される変換関数である。しかし,この関数を使用することで,変換オーバーヘッドが発生する。style機能を利用するのでなければ,できるだけ,この関数の使用は避けるべきである。
Fig.9-35 CONVERT()関数の使用例
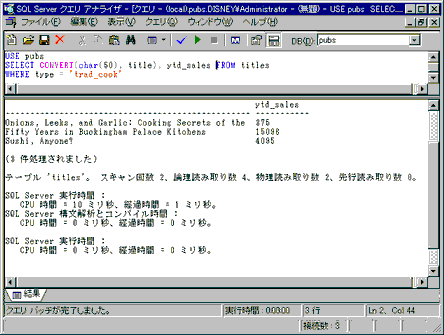
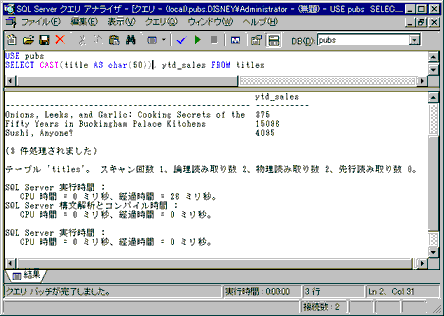
もし変換関数を使用するのであれば,SQL-92に準拠したCAST関数を使用したほうがよい。ただし,SQL Serverでは,charデータ型とdatetimeデータ型,smallintデータ型とintデータ型,あるいは異なる長さのcharデータ型同士を比較する場合は,SQL Serverが自動的に変換する(これは「暗黙の変換」と呼ばれる)ので,CAST関数を使う必要はない。
Fig.9-36 CAST関数の使用例
○SUM句を使用していないか
SUM句は,式のすべての値を返す場合,またはDISTINCT値のみの合計を返す場合に使用されるものの,インデックスが利用できないとテーブルスキャンで処理される。WHERE句にインデックスの設定されている列が指定されている場合にはそのインデックスが,WHERE句にインデックスの設定されている列が指定されていなければクラスタ化インデックスが,それぞれ使用される。しかし,いずれも利用できなければ,テーブルスキャンで処理され,データ量が多ければ性能問題となることもあり得る。
○カバーリングインデックスを利用できないか
カバーリングインデックスとは,クエリの結果セットとして返す必要のあるすべての列を非クラスタ化インデックスとして定義することである。カバーリングインデックスが設定されている場合,クエリの要求条件はリーフレベルをアクセスするだけで満足するため,データページへのアクセスは不要になり,応答が高速になる。この結果,クラスタ化インデックスのデータページと同様に,リーフレベルをスキャンすることもできる。頻繁に組み合わせて参照するデータ列を非クラスタ化インデックスとして定義することができるかどうかを確認する。
| Chapter 9 15/46 |