| News | 2002年8月2日 10:57 PM 更新 |
IBM東京基礎研究所が開発中の“使える技術”
日本IBMが「IBM東京基礎研究所」で研究開発を進めている最先端の技術を、報道関係者に公開した。次世代携帯電話向けのコンテンツ管理システムや「ASIMO」に搭載されている音声認識技術などが紹介された
日本アイ・ビー・エム(IBM)は8月2日、「IBM東京基礎研究所」(神奈川県・大和市)における研究内容を報道関係者に公開、最先端の音声認識技術やコンテンツ管理システムのデモンストレーションを行った。基礎研究所というと、要素技術関連を思い浮かべるかもしれないが、展示会では、実用化が念頭にある“使える技術”がいろいろと並べられていた。
試合映像にインデックス情報
「パーソナル・ビデオ・ダイジェスト」は、次世代携帯電話向けの映像配信サービスを対象にしたコンテンツ管理システム。サッカーなどの試合映像に、「ゴール」「シュート」などの約30種類のインデックス情報を付加することで、「シュートシーンが見たいといったユーザーのニーズに応えられるようにする」(東京基礎研究所の益満健副主任研究員)ものだ。「携帯電話で配信する際には、無駄なシーンが多いとパケット料金が高くなってしまう。見たいシーンを必要十分なだけ送れるシステムが必要とされている」(益満氏)。

インデックス用のメタデータは、だいたい3秒に1回のペースで挿入することができる。映像データを再生しながら、目的のシーンにきたところでプルダウンメニューからプレー内容を選択・指定する。作業時間としては、サッカーの試合の場合、ハーフがロスタイムを入れて50分とすると75分程度。映像時間の約1.5倍が目安となる。試合終了までメタデータを入れると、試合の“盛り上がり度”がグラフ化される。下の写真で、グラフの目盛りが上に伸び得ているところが、シュートシーンやゴールシーンを示しており、試合のハイライトを配信する場合などは、目盛りの値が大きいところが対象になるというわけだ。
ところで、実際に配信された映像を見てみると、“スルーパス→ゴール”という流れができている。加えて、ゴール後のパフォーマンスもちゃんと映し出された。「ゴール」というメタデータを加えただけなのに、ゴールした瞬間だけでなく、なぜその前後もちゃんと含まれているのだろうか? 益満氏によれば、「インデックスの前後何秒かを自動的に追加するといったようなことはしていない」という。
実は、上記の“盛り上がりデータ”を応用しているのだ。例えば、ゴールシーンの前には「スルーパス」などといった盛り上がり要素の高いシーンがあるはず。つまり、目盛りの山が頂点までゆっくりと近づいていれば、ゴールシーンの前にも重要なプレーが連発していることになり、目盛りが急激に盛り上がった場合は、突然、ゴールが生まれたことになる。「その辺りを、碓率的に判断している」(益満氏)。
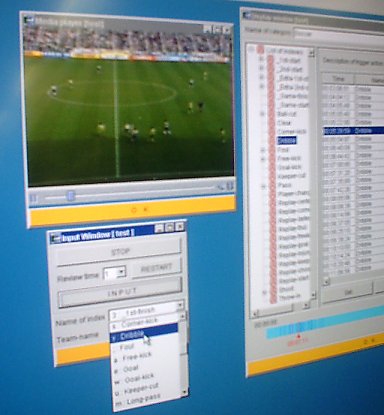
サッカー用のメタデータは30種類程度だが、任意に追加・削除することもできる。今後は、例えばファウルの中でも「試合の中で意味を持つファウル」と「無駄なファウル」といったように優劣をつけられるようにしたいという
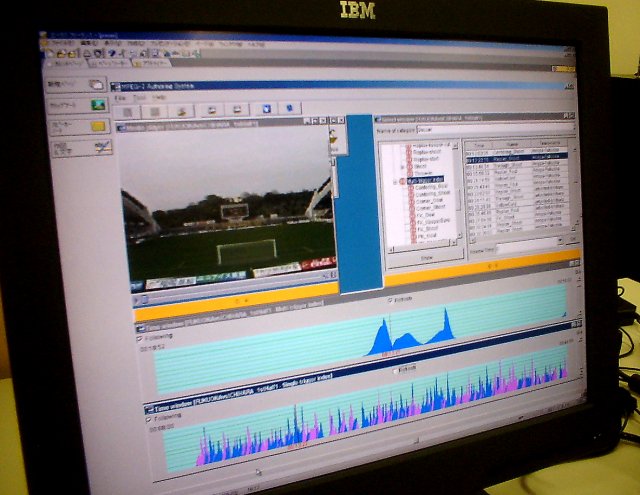
グラフには、ブルーとピンクの2種類があるが、これはチームごとにインデックス情報を追加しているため。このため、お気に入りのチームのハイライトだけを見るといったことも可能だ

配信時にには、再生時間、ならびにゴールやシュートといった各項目について、「多め」「普通」「少なめ」「なし」を選択する
なお、益満氏によれば、日本IBMでは現在、このシステムを同社ラグビー部で実際に使用しているという。「対戦相手の分析や戦術の理解、浸透を図るために、有効なツールだ。オンデマンド配信できるので、個々の選手がeラーニングに使うこともできる」(同氏)。
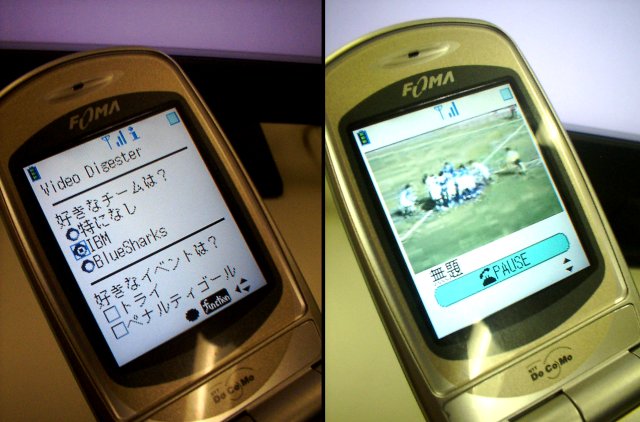
「次世代携帯電話向け」を掲げているだけに、展示会場では、NTTドコモの次世代携帯電話「FOMA」を使用したデモンストレーションを披露した
ASIMOの音声認識は「まだまだこれから」
ホンダの「ASIMO」には東京基礎研究所が開発した音声認識/合成技術が搭載されている。ASIMOが、説明会の行われた日本IBMの箱崎事業所に“勤務”していることもあり(3月6日の記事参照)、実際にデモンストレーションが行われた。

「前に来て」と言われたASIMOは、「前にいきます」と宣言してから、いつも通りそつなくこなしてみせる。音声認識については、あらかじめキーワードを入力してあるのだから、当然といえば当然だ。だが、いつまでもこのままというわけではない。
音声認識には、大まかに分類して「システム主導」「混合主導」「ユーザー主導」という3段階がある。東京基礎研究所で開発している電話音声による路線案内システムを例に説明すると、システム主導型では「出発駅を教えて下さい」というコンピュータの質問に対し、「青山一丁目」などとユーザーが応えることになる。混合主導型では、システムは「出発駅と到着駅をお願いします」と聞く。「青山一丁目から中央林間までお願いしますと」答えた場合、システムはどちらが出発駅なのかを判断しなければならない。ユーザー主導型になるとシステムは、「どのようなご案内をいたしましょうか?」としか聞かない。これに対しては、「青山一丁目から、中央林間までで、えーと、3時までに到着するやつ」などと自由発話しても理解できるようになる。

東京基礎研究所で開発中の「電話音声による列車時刻案内システム」
東京基礎研究所の音声認識技術のレベルは、「ユーザー主導型の一歩手前ぐらい」だという。では、ASIMOも、もうすぐ自由発話をサポートできるようになるのだろうか? 音声認識技術の担当者によれば、「技術的には可能だが、実際の運用はまだまだ難しい」と説明する。というのも、電話音声の場合は、周囲の雑音がかなり排除された状態でシステムに音声が届く。その分、認識率が高まるのだが、頭部のマイクで音声を拾っているASIMOは、周囲の雑音に非常に影響を受けやすいのだという。
「以前は、専用のマイクを使い、音声をデータ化してASIMOに送っていたが、それではASIMOと話しているという気がしない。やはり、ASIMOの音声認識は耳でやるべき。すぐに実現されるわけではない、そこを目指して開発していく」(同担当者)。
ASIMOと自由な会話――は、まだもう少し先の話のようである。
関連記事
関連リンク
[中村琢磨, ITmedia]
Copyright © ITmedia, Inc. All Rights Reserved.
![]()
ITmediaはアイティメディア株式会社の登録商標です。