Meta、生成AIトレーニングからユーザーがデータ(の一部)を削除できるように
Metaは、プライバシーセンターに生成AIモデルのトレーニングデータに関する説明を追加した。また、「生成AIで使用されるサードパーティからの個人情報を削除」するためのフォームの提供を開始した。
米Metaはプライバシーセンターに、生成AIモデルについての説明を追加した。いつ追加したかは不明だが、米CNBCの8月30日付の記事によると“今週”のことという。

上の画像の「Metaによる生成AIモデルの情報の利用について」を選択すると、「生成AIモデルに関連する、Metaによる情報の使用方法」というページが開く。このページで、Metaが生成AIを開発するために、公開情報や使用許諾を受けた情報、Metaの製品やサービスから取得した情報を使用していると説明する。
こうしたデータには個人情報が含まれる可能性があるが、個人情報をMetaのアカウントに明確に関連付けることはしないという。さらに、生成AIの開発にあたり、ユーザーのプライバシーを保護するための厳格な社内プライバシー審査プロセスを確立し、責任あるAIの開発に取り組んでいるとしている。
さらに、ユーザーには生成AIのトレーニングに使われるデータから取得された個人情報の使用方法に関する権利があるとし、3種類の異議申し立てをするためのフォームへのリンクを示している。

このフォームでは、「生成AIモデルのトレーニングに使用されるサードパーティのデータに含まれる可能性がある利用者の個人情報を、弊社がどのように使用するかに関する問い合わせを送信」できるという。選択肢は3つあり、「生成AIで使用されるサードパーティからの個人情報を削除したい」というものもある。
つまり、このフォームで削除申請できるのはサードパーティからの情報のみだ。ユーザーがFacebook、Instagram、Threadsに自分で入力したデータは生成AIのトレーニングに使われることに変わりはない。
Metaは、「ヨーロッパ地域や英国内では、生成AIモデルをトレーニングするための公開のソースや使用許諾を受けたソースに含まれる個人情報の取得や処理に関して、「正当な利益」の根拠を拠り所としています」と説明しており、この動きが欧州連合による「Digital Services Act」(DSA:デジタルサービス法)の8月25日の施行に関連することをうかがわせる。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 Google、EUのデジタルサービス法の発効に向けて広告に関する透明性向上を約束
Google、EUのデジタルサービス法の発効に向けて広告に関する透明性向上を約束
Googleは、EUのデジタルサービス法(DSA)発効の前日、ターゲティング広告などに関する透明性向上について発表した。EUに超大規模プラットフォームと指定されたプラットフォームは、DSAに違反すると罰金を科される可能性がある。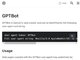 OpenAI、Webデータ収集クローラー「GPTBot」のブロック方法を説明
OpenAI、Webデータ収集クローラー「GPTBot」のブロック方法を説明
OpenAIは生成AIトレーニング用データをインターネット上のWebサイトから収集する自社製クローラー「GPTBot」をひっそり紹介し、Webオーナー向けにこのクローラーのブロック方法を説明した。 全米作家協会、生成AI大手に「トレーニングに著作を無断で使うな」公開書簡
全米作家協会、生成AI大手に「トレーニングに著作を無断で使うな」公開書簡
OpenAIやGoogle、Metaなど、生成AIを手掛ける米大手のCEO宛に、全米作家協会が著作物をAIのトレーニングに無断で使わないよう求める書簡を公開した。既に8500人以上が署名している。 無料で商用可、ChatGPT(3.5)に匹敵する生成AI「Llama 2」 Metaが発表、Microsoftと優先連携
無料で商用可、ChatGPT(3.5)に匹敵する生成AI「Llama 2」 Metaが発表、Microsoftと優先連携
米Metaは7月18日(現地時間)、大規模言語モデル「Llama 2」を発表した。利用は無料で商用利用も可能としている。最大サイズの70億パラメーターモデルは「ChatGPT(の3月1日版)と互角」(同社)という。 欧州議会、IT大手規制法案「DSA」「DMA」を可決
欧州議会、IT大手規制法案「DSA」「DMA」を可決
EUの欧州議会は、欧州委員会が2020年に発表したIT大手抑制法案「DSA」と「DMA」を賛成多数で可決した。欧州委員会は100人体制の専任チームを立ち上げる。AppleやGoogleに影響するこの法律の発効は今秋の見込みだ。