スマホで“口パク入力”を気軽にできるアプリ 東大とソニーCSLが「LipLearner」開発:Innovative Tech
東京大学とソニーコンピュータサイエンス研究所(CSL)に所属する研究者らは、口パク(無声発話)を検出し、スマートフォンの入力に使用できるモバイルアプリケーションを提案した研究報告を発表した。
Innovative Tech:
このコーナーでは、テクノロジーの最新研究を紹介するWebメディア「Seamless」を主宰する山下裕毅氏が執筆。新規性の高い科学論文を山下氏がピックアップし、解説する。Twitter: @shiropen2
東京大学とソニーコンピュータサイエンス研究所(CSL)に所属する研究者らが発表した論文「LipLearner: Customizable Silent Speech Interactions on Mobile Devices」は、口パク(無声発話)を検出し、スマートフォンの入力に使用できるモバイルアプリケーションを提案した研究報告である。
事前設定として、使用前にスマートフォンに声を出してコマンドを登録するところから始める。そして、電車などの公共の場でそのコマンドをスマートフォンに向かって無声発話すると、検出して指定した動きが発動する。


LipLearnerの使用例。(A)ユーザーはスマートフォンに向かってコマンドを一度声に出して記録させる。(B)地下鉄などの公共の場で事前登録したコマンドをスマートフォンに向かって無声発話すると認識する
音声入力は、プライバシーやセキュリティの問題が発生する恐れがあり公共の場では好まれない、周囲の雑音が多いと話しづらい、発話に障害のある人には利用できない、などの問題がある。プライバシーや社会的受容性の問題に取り組むため、無声発話でも音声認識を可能にするサイレント・スピーチ・インタラクション(SSI)が有望な選択肢として浮上している。
これまでにもSSIの研究は報告されてきたが、その多くはユーザーから何百ものサンプルを収集する必要があったり、制御された実験室環境で集中的に収集されたこのようなデータは、照明、顔の向き、姿勢などの要因で認識されなかったりする。またモデルの学習プロセスには時間がかかり、ハイエンドのGPUが必要で、万人が気軽に使える技術ではないのが現状だ。
この研究では、これらの課題を解決するためのSSIを提案する。モデルは、まず数百人の異なる話者によって作成した映像データセットを用いて数回のショットで唇を読み取るための特徴抽出器の事前学習を行う。このデータセットは、照明や背景、カメラ視点などの多様な記録条件をカバーしている。
ラベル付けしたデータを用いて、入力を既知のクラスに分類する従来の教師あり学習ではなく、特徴量を比較する仕組みを用いる対照学習を採用する。これにより、サンプルが与えられたとき、そのサンプルが未知のクラスに属していたとしても、最も類似したコマンドを見つけられる。

予備実験として、さまざまなシチュエーションによる発話データを収集し、照明条件(晴れた屋外、暗い室内など)、ユーザーの姿勢(立つ、座る、歩く)、スマートフォンの持ち方(片手、両手など)に対するモデルの性能とロバスト性を評価した。その結果、このモデルはさまざまな環境下で一貫した性能を発揮し、従来の教師あり手法を超えることを示した。

次に、ユーザーの一度もしくは数回の発話で新規コマンドの登録が可能な技術「Voice2Lip」を導入する。これは従来のように多数のサンプルを収集する必要がなく、声に出して一度もしくは数回コマンドを言うだけで、音声信号から認識したテキストをラベルとして、システムが唇の動きを学習する。これにより、新規コマンドの登録にかかるユーザーの負担を最小限に抑えることができる。
新規コマンドは自然言語だけでなく、顔の表情で入力できるジェスチャー設定も可能だ。例えば、笑うと笑顔の顔文字が入力されたり、困った顔をすると困った顔の絵文字が入力されたり、などである。このように自由度が高いコマンド設定が行える。

ユーザー調査の結果、モデルは30個のコマンドを一発で認識し、81.7%の精度で認識すると分かった。また、ユーザーから提供されるサンプル数が増えるにつれて性能が向上し、最終的に1コマンド当たり5サンプルで98.8%の精度を達成した。また、ユーザーの主観的なフィードバックにより、LipLearnerは使いやすく、学習しやすいことを示唆した。
このようにスマートフォン上で素早く始められるLipLearnerは、無声発話による入力が誰でも気軽に使える環境を作り出している。

本論文は、2023年4月に開催予定のHuman-Computer Interaction(HCI)の国際会議「CHI 2023」(Conference on Human Factors in Computing Systems 2023)に採択された研究である。
Source and Image Credits: Su, Zixiong, Shitao Fang, and Jun Rekimoto. "LipLearner: Customizable Silent Speech Interactions on Mobile Devices." arXiv preprint arXiv:2302.05907(2023); Zixiong Su, Shitao Fang, and Jun Rekimoto. 2023. LipLearner: Customizable Silent Speech Interactions on Mobile Devices. In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems(CHI ’23), April 23-28, 2023, Hamburg, Germany. ACM, New York, NY, USA, 21 pages. https://doi.org/10.1145/3544548.3581465
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 “考えている単語”を脳から読み取り特定 口パクは不要 米カリフォルニア工科大が発表
“考えている単語”を脳から読み取り特定 口パクは不要 米カリフォルニア工科大が発表
米カリフォルニア工科大学に所属する研究者らは、四肢まひの参加者が話したり話すまね(口パク)をしたりせず、単に考えている単語を脳から予測できるブレイン・マシン・インタフェース(BMI)を提案した研究報告を発表した。 口パクで長文の音声入力ができるメガネ型デバイス 立命館大が開発
口パクで長文の音声入力ができるメガネ型デバイス 立命館大が開発
立命館大学とデジタルスピリッツテック社の五十嵐雄也、双見京介、村尾和哉らは、口パク(無声発話)による音声入力が行えるメガネ型デバイスと耳掛け型マイクデバイスを提案した研究報告を発表した。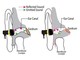 口パクで音声入力できるイヤフォン 口を動かした際の耳穴の変形から予測 米国チームが開発
口パクで音声入力できるイヤフォン 口を動かした際の耳穴の変形から予測 米国チームが開発
米University at Buffalo, State University of New York、米ノースウェスタン大学、米ワシントン大学、米コロラド大学の研究チームは、口パク(無声発話)で音声入力できるイヤフォンを開発した。口を動かした際の耳穴の変化を取得して入力を区別する。 音声だけで完全な長文が書ける技術、東大教授が開発 ささやき声で“改行”や“修正”などコマンドを入力
音声だけで完全な長文が書ける技術、東大教授が開発 ささやき声で“改行”や“修正”などコマンドを入力
ソニーコンピュータサイエンス研究所(CSL)フェロー・副所長であり東京大学大学院情報学環の暦本純一教授は、キーボードやマウスなどを使用せず、音声入力だけで長い文章が書ける技術を開発した。 1文字ずつ口パクでスペル入力できるシステム、東大などが技術開発 タイピング速度はスマホに匹敵
1文字ずつ口パクでスペル入力できるシステム、東大などが技術開発 タイピング速度はスマホに匹敵
東京大学、米ジョージア工科大学などによる研究チームは、口パク(無声発話)で1文字ずつタイピングするハンズフリーの入力システムを開発した。