Google Research、1枚の人物画像からその人物が話す動画を生成するAI「VLOGGER」発表
Google Researchは、人物の1枚の画像から“音声駆動で”発話する、その人物の動画を生成するAIシステム「VLOGGER」に関する論文を公開した。人物ごとにトレーニングする必要はなく、顔全体の表情の変化や、上半身画像の場合、手のジェスチャーも表現できる。
米Googleの研究部門Google Researchは3月13日、人物の1枚の画像から“音声駆動で”発話する、その人物の動画を生成するAIシステム「VLOGGER」に関する論文を公開した。関連ページのトップには、VLOGGERについて説明する音声を発話しているように見える10人の人物の動画が掲載されている。

VLOGGERは、人物画像から3Dモーションへの確率的拡散モデルと空間および時間的制御の両方でテキストから画像にモデルを強化する新しい拡散ベースのアーキテクチャで構成されている。これにより、可変長の高品質動画の生成が可能になったとしている。

人物画像ごとにトレーニングする必要はなく、口元だけでなく、瞬きなどの顔全体の表情の変化や、上半身画像の場合、手のジェスチャーも表現できる。
80万個のアイデンティティの以前のデータセットより「1桁大きいく、動的なジェスチャーを備えた」新しいデータセット「MENTOR」に基づいてトレーニングした。
研究者らは論文で、VLOGGERは「身体化された会話エージェント」への一歩だと語る。「プレゼンテーション、教育、ナレーション、低帯域幅のオンライン通信用独立ソリューションとして、人間とコンピュータの対話のためのインタフェースとして」活用できるとしている。
動画はVLOGGERのページを参照されたい。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 YouTube、生成AIを使ったリアルな動画へのラベル付け義務化開始
YouTube、生成AIを使ったリアルな動画へのラベル付け義務化開始
YouTubeは、予告どおりクリエイターツールをアップデートし、生成AIで編集あるういは生成したリアルな動画へのラベル付けを義務付ける。誤解を招く動画にクリエイターが放置する場合はYouTubeがラベルを付ける可能性もある。 GPT-3.5で生成した対話可能なデジタルなマリリン・モンロー、SXSWでデビュー
GPT-3.5で生成した対話可能なデジタルなマリリン・モンロー、SXSWでデビュー
60年以上前に亡くなった人気女優、マリリン・モンローのリアルなデジタル版がSXSWでデビューした。対話者の表情や声に応じた対応をし、逸話を共有する。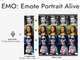 Alibaba、1枚の画像と音声でリアルな動画を生成する「EMO」発表
Alibaba、1枚の画像と音声でリアルな動画を生成する「EMO」発表
Alibabaは、1枚の人物画像からその人物が歌ったりしゃべったりする動画を生成するAIシステム「EMO」(Emote Portrait Alive)を発表した。 OpenAI、テキスト→最長1分の動画の生成AI「Sora」発表 一般公開はせず
OpenAI、テキスト→最長1分の動画の生成AI「Sora」発表 一般公開はせず
OpenAIは、テキストプロンプトから最長1分の動画を生成するAIモデル「Sora」を発表した。「AGIを達成するための重要なマイルストーンになる」としている。 “テイラー・スウィフト偽AI画像”の衝撃 一般人にも広がるディープフェイクの脅威 対策は?
“テイラー・スウィフト偽AI画像”の衝撃 一般人にも広がるディープフェイクの脅威 対策は?
テイラー・スウィフトの写真をAIツールで合成したわいせつ画像がXで拡散した事件は、幅広い方面に衝撃を与えた。だがこうした問題の深刻な影響を受けるのは、SNSに気軽に自分の写真を掲載する一般人の方かもしれない。対策はあるのだろうか? Google Research、かなり自然なテキスト→動画生成AI「Lumiere」発表
Google Research、かなり自然なテキスト→動画生成AI「Lumiere」発表
Google Researchは、「リアルな動画生成のための時空拡散モデル」の「Lumiere」を発表した。テキストあるいは画像から5秒間のなめらかな動画を生成する。