テキストだけじゃない? 画像データも理解できる「VLM」(視覚言語モデル)を導入する方法:“超”初心者向けローカルAI「gpt-oss」導入ガイド(4)(2/4 ページ)
本連載ではローカルLLMの導入方法から活用方法に至るまで、「手元にハイエンドPCがあって、生成AIをローカル環境で動かしてみたい」という初心者の方にも分かりやすく連載で解説する。
gemma-3-12bで画像認識機能を試す
gemma-3-12bは添付された写真の内容を認識し、入力されたプロンプトを元に処理が可能なモデルだ。LM Studioと組み合わせることで、初心者でも簡単に画像データを使ったLLMの利用が実現できる優れものだ。
gpt-oss-20bと比べてパラメーター数が少ないため、より高速なテキスト生成が期待できるが、iPhoneで撮影した画像を読み込んでから、処理するまでの時間がどれほどかかるか気になるので、実際に筆者が撮影した写真を用いて試してみた。これが参考になれば幸いだ。
撮影した写真に何が写っているか聞いてみた
それでは早速、gemma-3-12bを読み込んだLM Studioに、筆者が先日に土合駅(群馬県みなかみ町)で撮影してきた写真を添付し、「この写真は日本で撮影されたのですが、何が写っているか教えてください」というプロンプトを実行してみた。

gemma-3-12bを読み込んだ状態のLM Studioを見てみると、gpt-oss-20bを読み込んだ際に表示されなかった写真アイコンが表示されているので、こちらをクリックしよう。

するとプロンプト入力欄に画像のサムネイルが表示される。添付した画像について何を聞きたいのか、プロンプト入力欄に入力して「↑」アイコンをクリックし、プロンプトを実行しよう。
なお、例では「この写真は日本で撮影されたのですが、何が写っているか教えてください」と入力している。

プロンプトを実行すると、下記の通り回答が生成される。少ししか写っていないレールもしっかりと認識している。さらにホームの背景の自然を認識した上で「日本のローカル線の駅のホーム」と回答が得られた。
この写真は日本のローカル線の駅のホームです。
特徴としては、以下のような点が挙げられます。
- 線路とホーム:線路の横に黄色い点字ブロックが設置されているのが見えます。
- 架線柱:電車を動かすための架線を取り付ける柱があります。
- 自然豊かな風景:ホームの背景には緑豊かな山々が広がっており、日本の地方にある駅であることが分かります。
これらの要素から、この写真は日本で撮影されたローカル線の駅のホームであると判断できます。

なおiPhoneで写真を撮影すると、初期設定ではJPG形式ではなく圧縮率の高いHEIC形式で保存される。
今回はHEIC形式のままLM Studioに添付した場合と、PCでJPGに変換した場合とで、それぞれ回答が生成されるまでの時間を測定してみた。結果は以下の通りだ。
| ファイル形式 | 画像の読み込みにかかった時間 | 回答が生成されるまでにかかった時間 |
|---|---|---|
| HEIC形式 | 約41秒 | 約2秒 |
| JPG形式 | 約9秒 | 約2秒 |
HEIC形式のままでもLM Studioで取り扱えるが、ファイルを開くまでにかなりの時間を要する。もし利用するのであれば事前にJPG形式にPCで変換しておく方が無難だろう。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 「gpt-oss」はチャット機能以外にも活用方法がたくさん? 最新のWeb情報を利用するやり方も伝授
「gpt-oss」はチャット機能以外にも活用方法がたくさん? 最新のWeb情報を利用するやり方も伝授
本連載ではローカルLLMの導入方法から活用方法に至るまで、「手元にハイエンドPCがあって、生成AIをローカル環境で動かしてみたい」という初心者の方にも分かりやすく連載で解説する。 手元にあるゲーミングPCを活用して生成AIを動かす! 無料で使える「LM Studio」のキホンを解説
手元にあるゲーミングPCを活用して生成AIを動かす! 無料で使える「LM Studio」のキホンを解説
本連載ではローカルLLMの導入方法から活用方法に至るまで、「手元にハイエンドPCがあって、生成AIをローカル環境で動かしてみたい」という初心者の方にも分かりやすく連載で解説する。 手元にゲーミングPCがあれば、オフライン環境でも生成AIが利用できるってホント? ローカルLLM(大規模言語モデル)導入を解説
手元にゲーミングPCがあれば、オフライン環境でも生成AIが利用できるってホント? ローカルLLM(大規模言語モデル)導入を解説
本連載ではローカルLLMの導入方法から活用方法に至るまで、「手元にハイエンドPCがあって、生成AIをローカル環境で動かしてみたい」という初心者の方にも分かりやすく連載で解説する。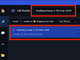 米AMD、RyzenやRadeonで生成AIをローカル実行するハウツーガイドを公開
米AMD、RyzenやRadeonで生成AIをローカル実行するハウツーガイドを公開
GPTベースのLLM(大規模言語モデル)を使ったAIチャットbotの実行、LLMをローカルでカスタマイズできる検索拡張生成(RAG)の導入、プログラミングにおけるコーディングアシスタントの実行という3つの手順を紹介している。 NVIDIAがPC上のデータを使うAIチャットbotツール「Chat with RTX」公開/AMD製CPUに複数の脆弱性
NVIDIAがPC上のデータを使うAIチャットbotツール「Chat with RTX」公開/AMD製CPUに複数の脆弱性
うっかり見逃していたけれど、ちょっと気になる――そんなニュースを週末に“一気読み”する連載。今回は、2月11日週を中心に公開された主なニュースを一気にチェックしましょう!