企業のAI活用の“真打ち” 「プライベートLLM」の可能性から実践方法まで、専門家が解説
デジタル変革の波が押し寄せる中、生成AIの活用が企業の競争力を左右する時代が到来している。ChatGPTの登場以来、多くの企業がクラウドベースの生成AIサービスの導入を検討してきた。しかし、機密情報や社内データの保護が特に重要な業界では、新たな選択肢として「プライベートLLM」が注目を集めている。
プライベートLLMとは、企業が自社の環境内に構築・運用する大規模言語モデル(LLM)のことを指す。この技術は、一般に公開されているパブリッククラウド上のAIサービスとは異なり、企業の内部ネットワークで完結するシステムだ。
日本ヒューレット・パッカード(以下、HPE)のサービスデリバリー統括本部に所属する安江啓人氏は、プライベートLLMの本質的な価値をこう説明する。
「オンプレミス環境で構築するプライベートLLMは、ネットワークを遮断した環境でも稼動可能であり、データセキュリティを万全に確保することができます。高度な機密性を要する社内システムとのシームレスな連携や、企業独自のガバナンスに即したカスタマイズも実現できます」
 HPEの安江啓人氏(サービスデリバリー統括本部 金融・公共サービスデリバリー本部 第五部)
HPEの安江啓人氏(サービスデリバリー統括本部 金融・公共サービスデリバリー本部 第五部)
これは、金融業界をはじめとしたセキュリティの要求が厳しい分野で大きな反響を呼んでいる。HPEのHPC&AI事業統括に所属する山口涼美氏も、セキュリティの観点からプライベートLLMの重要性を強調する。
「パブリッククラウドサービスでも、顧客データの保護をうたっていますが、生成AIサービス関連だと倫理や悪用防止の観点で、基本的にはクラウド運営内部の社員が必要に応じて閲覧できる契約になっているケースが多く、情報の安全性を完全に保証するのは難しいのが現状です。特に金融や通信関連の顧客は、重要な情報や社内データをパブリッククラウドで扱うことに大きな懸念を抱いています」
プライベートLLMの価値はセキュリティだけにとどまらない。山口氏は、マシンリソース確保の観点からもその利点を説明する。
「現在、クラウド上のGPUリソースは常に不足しており、まさに奪い合いの状態です。自社でリソースを確保して自由に使いこなせる環境を構築したいというニーズが高まっています」
プライベートLLM:4段階の構築プロセス
プライベートLLMはどのようなプロセスで構築し、活用していくのだろうか。その道筋は4つのフェーズに分けられる。
第1フェーズは、オープンソースのLLMをオンプレミス環境に展開して稼動させる「LLMの実行」から始まる。第2フェーズで、検索拡張生成(RAG:Retrieval-Augmented Generation)などの技術を駆使して社内の機密情報を安全に扱う「LLMの活用」へと進化させる。さらに高度な利用を目指す場合は、第3フェーズとして特定の用途や要件に適合させるためにモデルを最適化する「LLMの微調整」(ファインチューニング)、第4フェーズで企業固有のドメイン知識を大規模に学習させる「LLMの事前学習」へと発展させていく。
「ファインチューニングは既存のモデルを微調整するのに対し、事前学習はより大規模なドメイン知識の獲得を目指します。後者は多くのGPUリソースを必要としますが、特定の業界や分野に特化したモデルを作る上で非常に重要な技術となります」(山口氏)
こうしたプライベートLLMの構築ステップには、最適なモデルとハードウェアの選定が不可欠だ。
「オープンソースのモデルには多様なサイズが存在するので、企業のGPUリソースに適合した選択が求められます。例えば、パラメータ数が7B(70億)、13B(130億)、70B(700億)といったモデルサイズがありますが、それぞれ必要リソースが異なります」
ChatGPTに匹敵するといわれる日本語対応LLM「Vicuna-13B」を使った検証では、「NVIDIA A100 40GB」 1枚でLLMを実行できた。使用するGPUメモリを削減できるVicuna-13Bの8bit量子化モデルを採用したことで、約16GBのVRAM利用で安定した運用を実現したという。
「モデルサイズが大きければ大きいほど高精度な出力を実現しますが、実行時間や必要なGPUメモリも大きくなります。そのあたりは学習でも推論でも色々と工夫できる手法がありますので、活用しながらGPUをうまく使いこなすことが重要です」
 HPEの山口涼美氏(HPE&AI事業統括 プリセールスコンサルタント 兼 AIビジネス開発マネージャー)
HPEの山口涼美氏(HPE&AI事業統括 プリセールスコンサルタント 兼 AIビジネス開発マネージャー)
RAGの精度をどう向上させるか?
プライベートLLMの具体的な活用例として注目が集まっているのが、RAGを使った企業内の情報検索や問い合わせ対応の効率化だ。
「RAGに対する関心が特に高まっています。企業独自のデータを活用してAIの力を引き出そうとする動きが活発化しているのです」(安江氏)
多くの企業が特定の有識者に質問が集中して業務効率が低下するという共通の課題を抱えているが、プライベートLLMを一次スクリーニングとして活用することで、この課題を劇的に改善できる。さらに、AIの回答がどの文書のどの部分を参照しているかを明示できるため、誤った情報生成(ハルシネーション)も容易に確認できるといった利点がある。
RAGを使った問い合わせ対応を実現するには、まず社内文書を適切なサイズに分割し、それをベクトル化してデータベースに格納する。ユーザーからの問い合わせに対して、作成したデータベースから関連性の高い情報を検索して結果をLLMに入力することで、社内情報を基にした回答を生成することができる。
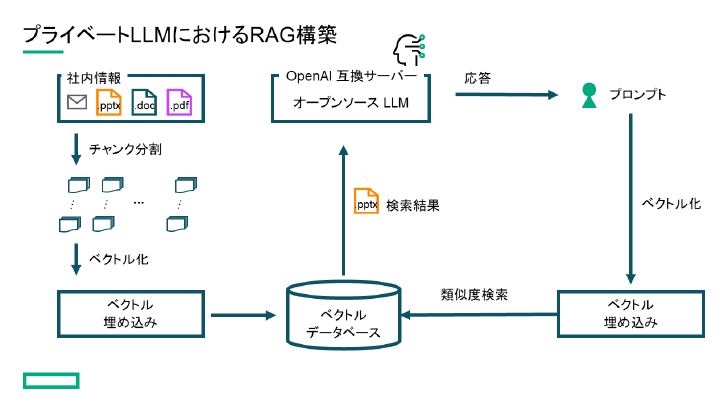 プライベートLLMにおけるRAG構築の概要図(出典:HPE提供資料)
プライベートLLMにおけるRAG構築の概要図(出典:HPE提供資料)
しかし、RAGの精度向上にはさまざまな課題が立ちはだかる。安江氏は、その難しさをこう語る。
「多くの企業は、RAGの初期構築後、45%程度の精度で足踏みしてしまう傾向があります。そこからさらに精度を引き上げるには、検索アルゴリズムの最適化や検索結果のリランキングなど、多面的な改善アプローチが求められます。HPEではお客さまのユースケースやデータに合わせて、精度を向上させるためのさまざまなご提案をさせていただきます」
企業内でのデータガバナンスとアクセス制御もRAGの導入にとって解決しなくてはいけない課題だ。
「企業内では部署ごとに閲覧可能な情報が異なります。そのため、複数のベクトルデータベースを構築して緻密なアクセス制御を実装する必要があります。全社共通の情報、部署別の機密情報、関係者外秘の戦略的情報など、多層的な管理体制が要求されるのです」(安江氏)
NVIDIAとの協業も HPEの生成AIソリューション
生成AIの活用、プライベートLLMの導入、RAGによる回答精度アップ――このような多岐にわたる要求に応えるため、HPEは包括的なAIソリューションポートフォリオを用意している。
「軽量な推論用システムから大規模な学習用システムまで、幅広いラインアップを取りそろえています。2Uサイズの汎用(はんよう)サーバから8個のGPUを1枚のボードに集約したハイエンドモデル、スーパーコンピュータ『Cray』のノウハウを生かした水冷システムまで、企業の多様なニーズに柔軟に対応できる製品群を用意しています」(山口氏)
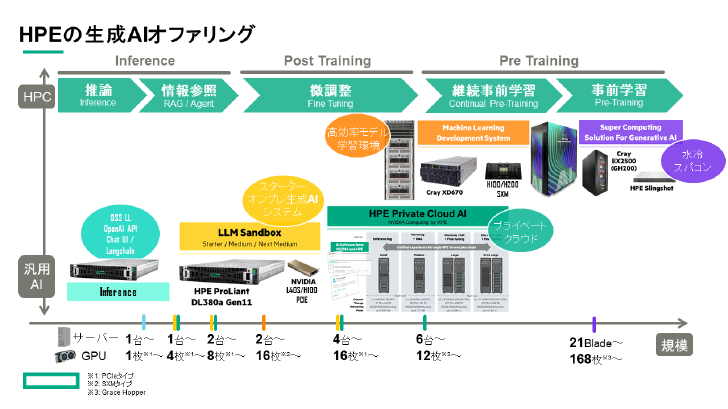 HPEの生成AIソリューション群(出典:HPE提供資料)
HPEの生成AIソリューション群(出典:HPE提供資料)
さらに2024年6月、HPEはNVIDIAとの戦略的協業を通じて、AIソリューション群「NVIDIA AI Computing by HPE」を発表しており、その一環としてAI向けプライベートクラウド「HPE Private Cloud AI」の提供を開始する。
「NVIDIAのAI向けアクセラレータやネットワーク、ソフトウェアと『HPE GreenLake』を融合させた製品です。両者が合わさることによって、企業は迅速かつ効率的にAI環境を構築、運用できるようになります」と山口氏は説明する。
HPE GreenLakeは、オンプレミス環境でありながらパブリッククラウドのような柔軟性を実現するサービスだ。必要なタイミングでマシンリソースにアクセスできて使用量に応じた従量課金制になっている。これにより、AIワークロードの動的な管理や迅速なスケーリングが可能になるという。
「仮想化やコンテナ、データベース連携などGreenLakeのサービスポータルを通してリソースを柔軟に活用できることも特徴です。AIや分析ツールもそれらの環境上ですぐに使い始めることができます」(山口氏)
 HPE Private Cloud AIの概要(出典:HPE提供資料)
HPE Private Cloud AIの概要(出典:HPE提供資料)
プライベートLLMの導入を検討する企業に、安江氏は次のようなメッセージを送る。「プライベートLLMの最大の強みは、秘匿情報の安全な取り扱いと高度なカスタマイズ性です。私たちは、お客さまの要望に沿って、適切なシステムの設計と構築をサポート致します」
山口氏も、その重要性をこう強調する。「今日の企業にとって、セキュリティと信頼性は何よりも重要です。プライベートLLMを活用することで、社内データを安全に扱いながらAIの恩恵を最大限に享受できます」

プライベートLLMは、企業がAIを安全かつ効果的に活用するための新たな選択肢として、急速にその存在感を増している。特に、セキュリティ要件が厳しい業界や大規模なAI活用を目指す企業にとって、プライベートLLMの導入は大きな価値をもたらす可能性を秘めている。HPEのような専門家のサポートを受けて自社に適したプライベートLLM環境を構築することで、生成AIの力を最大限に引き出し、新たなイノベーションの扉を開くことができるだろう。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
日本ヒューレット・パッカード合同会社
アイティメディア営業企画/制作:ITmedia AI+編集部/掲載内容有効期限:2024年9月6日