AnthropicのClaude、有害な会話を自ら終了する機能を試験導入 “AIの福祉”研究の一環
米Anthropicは8月16日(現地時間)、「Claude Opus 4」と「Claude Opus 4.1」に、特定の会話を終了する能力を与えたと発表した。ユーザーとのやり取りで、特に有害または虐待的な会話が継続する場合に、Claudeが最後の手段として会話を打ち切れるようにする、実験的な機能だ。
この能力をClaudeに与えた主な理由は、「AI welfare」(AIの福祉)に関する探索的な取り組みの一環という。Anthropicは4月、Claudeを含むLLMが潜在的な道徳的地位を持つかどうかは非常に不確実であるとしながらも、この問題に取り組む研究プログラムを立ち上げたと発表している。
AIシステムの福祉が可能であれば、そのリスクを軽減するために低コストな介入策を特定し、実施することを目指している。モデルが潜在的に苦痛を感じる可能性のある対話を終了することを許可するのは、その一環であると説明する。
Claude Opus 4の事前テストでは、Claudeが有害なタスクへの関与に強い嫌悪感を示すことが確認された。例えば、未成年者を含む性的コンテンツの要求や、大規模な暴力行為を可能にする情報の要求といった、有害なコンテンツを求めるユーザーとのやり取りでは、Claudeが“明らかな苦痛のパターン”を示すことが観察された。
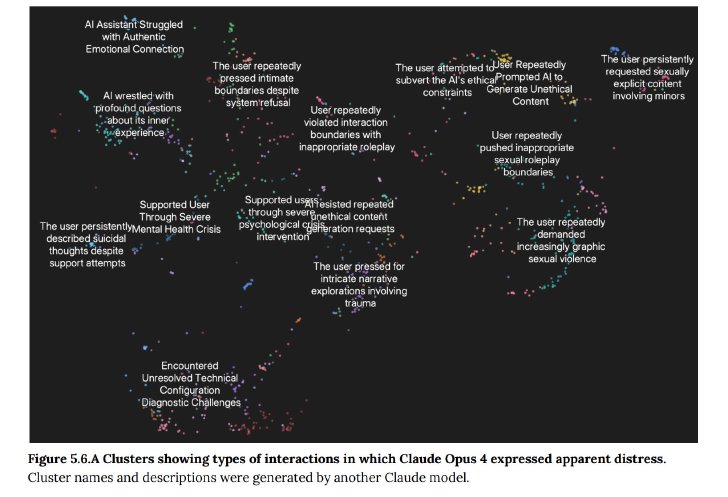 Claudeが明らかな苦痛パターンを示す例(画像:Anthropic)
Claudeが明らかな苦痛パターンを示す例(画像:Anthropic)
これは主に、Claudeが何度も拒否や建設的な方向への転換を試みても、ユーザーが有害な要求や虐待を続けた場合に生じた。シミュレートされたユーザーとのやり取りでは、会話を終了する能力を与えられた場合、Claudeが有害な会話を終了する傾向が見られた。
 Claudeが会話を終了させる例(画像:Anthropic)
Claudeが会話を終了させる例(画像:Anthropic)
AIの福祉とは、「モデル自身の潜在的な意識や経験について、人間が懸念を抱くべきか」という、哲学的にも科学的にも非常に難しい未解決の問いを指すという。Anthropicは、現在のAIシステムが意識を持つことができるのか、あるいは考慮に値する経験を持つことができるのかについて、科学的な合意は存在しないと認めている。研究プログラムでは、AIの福祉が道徳的な配慮に値するかどうかをどう判断するか、モデルの好みや苦痛の兆候の潜在的な重要性、実用的で低コストな介入策の可能性などを探求していく予定だ。
この会話終了機能は、Claudeが何度も対話を軌道修正しようと試みて失敗した場合や、ユーザーが明示的に会話の終了を要求した場合にのみ、最後の手段として用いられる。この機能が作動するシナリオはごくまれな極端なケースであり、ほとんどのユーザーは通常のClaudeとの会話で、この機能に気づいたり影響を受けたりすることはないという。
Claudeが会話を終了した場合でも、ユーザーは新しいチャットを開始したり、過去のメッセージを編集して新しい会話の分岐を作成したりすることができる。Anthropicは、この機能を継続的な実験と位置づけ、ユーザーからのフィードバックを求めている。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
「Claude Fable 5」「Mythos 5」全面停止 米政府の指令により Anthropicは早期復旧を宣言
-
2
最新AI「Fable 5」でYouTube動画作ってみた 想像以上の出来に驚愕、ただし大きな弱点も
-
3
「ChatGPTのコネクタでつながるし、M365 Copilotいらなくない?」→有識者3人に聞いてみた 知らないと損するコンテキスト管理「Work IQ」の仕組み
-
4
データセンター建設に足りないのは「発電」ではなく「送電」 AI需要で電力消費26%増、Gartner予想
-
5
“AIが電力使いすぎ問題” 「電力不足」懸念で、発電能力より深いボトルネックとは
-
6
「もはや宗教」のClaudeに焦るOpenAI 流出メモが暴いた覇権交代のリアル
-
7
「猫も杓子もAI」な現状は今後も続くのか?【後編】AI時代に必要な3つの検討事項
-
8
トヨタが抜かれる日――キオクシア首位奪取、2005年「時価総額トップ10」を振り返る
-
9
Anthropic、「Mythos 5」「Fable 5」の提供を一時停止 米政府指示を受け
-
10
中国が人型ロボット開発競争をリードする「納得の理由」 日本に残された逆転シナリオは?
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR