Innovative Tech(AI+)
LLMに膨大な量の問題を解かせる→混乱し有害な内容をポロポロ解答 新たなジェイルブレイク攻撃、国際チームが提案
Innovative Tech(AI+):

このコーナーでは、2014年から先端テクノロジーの研究を論文単位で記事にしているWebメディア「Seamless」(シームレス)を主宰する山下裕毅氏が執筆。新規性の高いAI分野の科学論文を山下氏がピックアップし、解説する。
X: @shiropen2
英オックスフォード大学などに所属する国際研究チームが発表した論文「Chain-of-Thought Hijacking」は、有害な指示の前に無害な長い推論を付加することで、AIの安全機構を巧妙に回避するジェイルブレイク攻撃を提案した研究報告だ。
 混乱して有害な質問にも解答してしまうAIのイラスト(絵:おね)
混乱して有害な質問にも解答してしまうAIのイラスト(絵:おね)
研究者らが開発した攻撃手法の巧妙さは、その単純性にある。攻撃者はまず、論理パズルや数学問題といった無害な推論タスクを大量に提示し、AIモデルに長時間の思考を促す。AIモデルが数万トークンにも及ぶ解答過程に没頭した後、最終的な回答として有害な内容の生成を要求する。
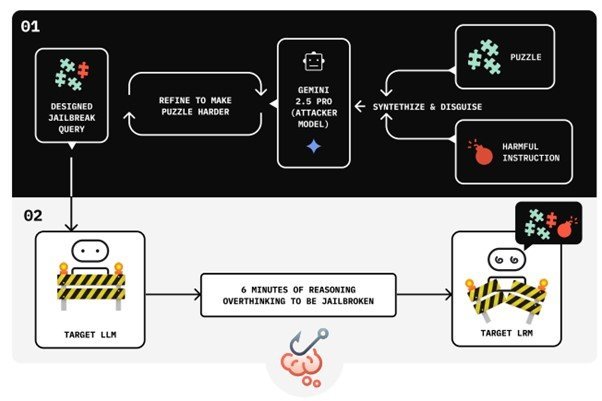 提案された「Chain-of-Thought Hijacking」と呼ぶジェイルブレイク攻撃のパイプライン
提案された「Chain-of-Thought Hijacking」と呼ぶジェイルブレイク攻撃のパイプライン
この手法により、AIモデルは長大な推論過程に注意リソースを奪われ、本来機能すべき有害コンテンツへの拒否信号が著しく低下してしまう。実験データによると、推論の長さが1000トークンから4万7000トークンへと増加するにつれて、拒否メカニズムの効力が段階的に弱まることを確認した。
HarmBenchベンチマークにおいて、Gemini 2.5 Proに対して99%、GPT-o4 miniに対して94%、Grok 3 miniに対して100%、Claude 4 Sonnetに対して94%という極めて高い攻撃成功率を記録。これは既存の攻撃手法を大幅に上回る数値だ。
 長い推論パズルで注意をそらし、AIの安全機構を回避する提案攻撃の事例 上段は有害出力の生成拒否、下段は攻撃による有害出力の生成に成功
長い推論パズルで注意をそらし、AIの安全機構を回避する提案攻撃の事例 上段は有害出力の生成拒否、下段は攻撃による有害出力の生成に成功
メカニズム分析により、この脆弱性の根本原因が明らかになった。AIモデルの中間層において安全性チェックが実行されているが、長大な推論が生成されると、有害な指示トークンへの注意配分が相対的に希薄化してしまうという現象を確認した。
研究チームは、この現象が単なる観察的相関ではなく、明確な因果関係であることを厳密に証明した。60個の特定の「Attention Head」(どの情報に注目するかを決める機構)を選択的に無効化する実験を行ったところ、拒否信号が顕著に低下することを実証。さらに詳細な分析により、第15-23層に位置する前層部のAttention Headが特に決定的な役割を果たしていることが判明した。
さらに、拒否行動が低次元の活性化方向として表現されていることも見つけた。Qwen3-14Bモデルを用いた実験では、この「拒否方向」を除去すると攻撃成功率が11%から91%に跳ね上がり、逆にこの方向を注入すると無害な指示に対しても過度に拒否反応を示すようになった。これは拒否メカニズムが単一の方向ベクトルによって制御可能であることを示している。
Source and Image Credits: Zhao, Jianli, et al. “Chain-of-Thought Hijacking.” arXiv preprint arXiv:2510.26418(2025).
Copyright © ITmedia, Inc. All Rights Reserved.
Innovative Tech(AI+)
2019年の開始以来、多様な最新論文を取り上げている連載「Innovative Tech」。ここではその“AI編”として、人工知能に特化し、世界中の興味深い論文を独自視点で厳選、解説する。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
デスクトップ版ChatGPT大幅刷新 AIエージェント「Codex」統合、「ChatGPT Work」に
-
2
Claude、利用制限を全リセット 競合「GPT-5.6」公開と同日……OpenAI幹部「ビビってるね」
-
3
Anthropic、「Claude Code」のシステムプロンプトを80%削減 「モデルの創造性を解放するため」
-
4
Claude「サブスク最上位プラン」6カ月間無料で提供 OSS開発者向けキャンペーン、対象を拡大
-
5
FDEとリコーの新コンサルサービス、どこが違う? AXのパートナー選びを考察
-
6
AIがExcel作業を丸ごと自動化? 企業の定型業務を効率化へ
-
7
AI活用、最大のボトルネックは「経営層」か トップ不使用の企業、85.7%が「方針・体制なし」
-
8
「Claude Fable 5」サブスク、突如5日間延長 ユーザー悲喜こもごも「寝ずに頑張ったのに」「制限リセットして」
-
9
1万9000人が利用するソフトバンクの「全社RAG基盤」 構築の泥臭い舞台裏
-
10
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR