NPUだけでOpenAIのLLM「gpt-oss」が動く! 速度や消費電力を計測してみた
「AI PC」や「Copilot+ PC」という単語を聞くようになってすでに1年は過ぎたところだが、ChatGPTのような高性能なLLM(大規模言語モデル)がローカルでも動くのか? と問いにはあまり良い答えがなかったのがこれまでだった。そういうことをしたいなら外部GPUかMacを用意した方がいいと。NPUの性能としてうたわれる「1秒間にウン兆回の計算」とは何だったのか、と疑問に思う人もいるだろう。
しかし、最近になってようやく良い兆しが見え始めた。米AMDのNPU「Ryzen AI」で、ローカルLLM「gpt-oss 20B」を動作させられるソフトウェアが出てきた。gpt-ossといえば米OpenAIが2025年8月に公開したLLMで、デスクトップPC向けのハイエンドGPUでも実行できるファイルサイズでありながら数学のベンチマークでは同社のハイエンドLLM「o3」に匹敵するという触れ込み。
(関連記事:OpenAIの「オープンなAI(gpt-oss-120b)」はGPUサーバじゃないと動かない?→約30万円の自作PCで動かしてみた)
これがCopilot+ PC単体で動作するのはかなりうれしいところ。こうしたNPU周りの現状について筆者がまとめた同人誌を、コミックマーケット107の2日目(東京ビッグサイト、12月31日)に出展するサークル「Project Connect」(南2 i-18a)で頒布する。今回はその本の一部を加筆・再構成した形でお届けする。

※「あるごす」は筆者の個人活動用ペンネーム。
NPUオンリーでLLMを動かせるAMDの「Lemonade」
 Lenovo「ThinkPad T14 Gen 6 AMD」 50TOPSのRyzen AI NPUを搭載しつつメインメモリも64GBと潤沢
Lenovo「ThinkPad T14 Gen 6 AMD」 50TOPSのRyzen AI NPUを搭載しつつメインメモリも64GBと潤沢
今回検証に使ったのは、Ryzen AI 7 PRO 350(Krackan Point)を搭載するLenovo「ThinkPad T14 Gen 6 AMD」。300シリーズの中では下位に位置するがNPUの性能は上位モデルと変わらず、メインメモリも64GBと潤沢。仮にLLMのロードに32GB使ってもまだ32GB残るため、AI時代のPCにはこれくらいのメモリは最低限欲しいところだ。
「Lemonade(Lemonade Server)」はAMDがApache 2.0で開発している、ローカルAI実行用のデスクトップアプリケーション。Ryzen AI 300シリーズのPC対応に特化していて、NPUのみでの実行や、内蔵GPUとのハイブリッド実行などが可能だ。
 「Lemonade」のUI。筆者が原稿を執筆しているときはWeb UIだったが直近の更新でデスクトップアプリになった
「Lemonade」のUI。筆者が原稿を執筆しているときはWeb UIだったが直近の更新でデスクトップアプリになった
インストールは簡単で、公式サイトからダウンロードしたインストーラーを開いて手順通りに進めればOK。一般的なソフトウェアと変わらない感覚だ。
AMDには開発者向けのNPU動作環境として「Ryzen AI Software」というものもあるのだが、Pythonのconda環境を用意して、Visual Studio 2022でのビルド環境を用意して……とハードルが高い。おまけに最新バージョンの1.6.1はインストールに必要なサーバへの問い合わせで失敗する事象がRedditに報告されており、筆者も実際に遭遇した。そんなわけで、AMDのNPUでLLMを動かしたいのであれば少なくとも現状はLemonadeを使うのがおすすめだ。
もっとも、LLMをローカル実行する環境として現在メジャーなのは「LM Studio」というフリーのソフトウェアだ。各種LLMが公開されているプラットフォーム「Hugging Face」からモデルをダウンロードし、必要であればパラメータを調整した上でロードし実行、という一連の処理をGUI上でできる。チャット画面もChatGPTライクで、LLMからのMarkdown出力もパースしてくれる。
(関連記事:Copilot+ PCやハイスペックマシンでお手軽ローカルLLM「LM Studio」を試してみた UIがかなり使いやすいぞ DeepSeekの小型モデルも動く)
しかし、LM StudioはNPUでのLLM計算に対応していない。Copilot+ PCにLM Studioをインストールすればメインメモリが許す限りのLLMは実行できるようになるが、GPUもしくはCPUでの計算となり、NPUは使ってくれない。したがって、NPUを使いたいのなら少なくとも現状は、LM Studioは選択肢に入らない。
10倍以上省電力!? Ryzen AI独自ランタイム「FastFlowLM」
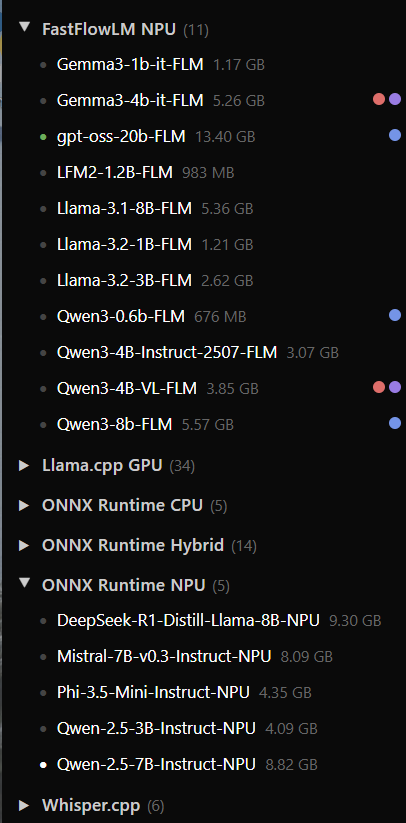 Lemonadeで扱えるAIモデル一覧
Lemonadeで扱えるAIモデル一覧
Lemonadeを開いてみると、このソフトウェアで扱えるAIモデル一覧が表示される。NPU実行に対応しているものは「Onnx Runtime NPU」、NPUとGPUのハイブリッド実行に対応しているものは「Onnx Runtime Hybrid」の項目に分類されている。
ではOnnx Runtime NPUの項を見てみるとどうかというと、実は対応モデルはぱっとしない。Qwenは2.5だし、DeepSeek R1蒸留モデルも古い。Phi-3.5もすでにかなり古い。
話が違うではないかとなるが、ここで見てほしいのは「FastFlowLM NPU」の項目だ。ここにはgpt-oss 20B、Gemma3 4B、Qwen3 4Bの2507版、Qwen3 8Bなどと、小型なLLMの中でも有力なモデルが並んでいる。
この項目だけLLMの実行方法が異なっていて、「FastFlowLM」という、Ryzen AIに最適化したランタイムを使っている。これは同名のスタートアップ企業が作っていて、学術研究者やソフトウェアエンジニアなどがAMDと共同で開発しているという。
プロジェクトの説明も大胆だ。
GPU不要。速くて10倍以上省電力。25万6000トークンのコンテキスト長まで対応。超軽量(16MB)。20秒でインストール。(筆者訳)
こうした性能を実現する上での詳しい説明はないが、AMDのNPUならではのアーキテクチャにモデルを直接最適化しているものと思われる。また、非商用利用なら無料だが商用利用などには制限があるので、もしビジネスシーンで使いたいならライセンスをよくよく確認されたい。
比較条件
ここでは比較のために、
- Qwen2.5 7B Hybrid(NPUで前処理をしGPUで計算するもの)
- Qwen2.5 7B NPU
- Qwen3 4B FLM
の3種を同じプロンプト(翻訳タスク)で5回ずつ実行し、トークン生成速度の他、筐体内の温度と消費電力の推移を「HWMonitorPro」を使って記録した。Qwen3 4B FLMのみモデルやパラメータ数が異なるが、HybridとOnnx Runtime NPUとFLMを統一的に比較できるモデルがなかったため、比較的近いものとしてピックアップした。
gpt-oss 20B FLMの性能も調べたいので、LM Studio上でのgpt-oss 20B(GPUとCPUのハイブリッド実行)とも生成速度や消費電力などを比較した。
NPU実行の方が温度上昇は緩やか 消費電力はピーク時で半分
まず一番違いが出ると予想されるのは温度と消費電力であろう、ということで、それらのグラフを見ていく。
各グラフでは5回分の推移を重ねて表示している。いずれの条件でも時間軸で10秒の位置でプロンプトを実行。翻訳という生成トークン数にブレが生じにくいタスクをさせているので、生成終了も40秒付近に固まっているのが分かる。
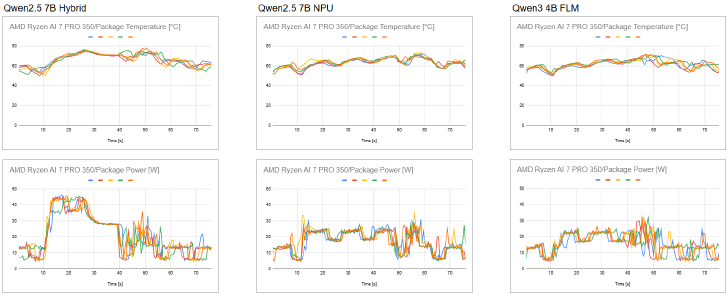 各実行方式ごとの内部温度(上段)と消費電力(下段)の推移。それぞれ5回分の推移を重ねて表示(クリックして拡大)
各実行方式ごとの内部温度(上段)と消費電力(下段)の推移。それぞれ5回分の推移を重ねて表示(クリックして拡大)
消費電力を見たときに、タスクが終わった後に大きなブレが発生している箇所がいずれの条件にも認められるが、これはタスク終了直後に筆者が画面のスクリーンショットを撮った結果としてスクリーンショットがフォルダに自動保存され、その内容をNPUで精査しインデキシングしているからだと思われる(実際にNPUがそのときに動作しているのを確認している)。
改めて消費電力を見ると、ハイブリッド実行ではピークで45W程度まで上ってから30Wに落ち着いてストンと落ちて終了、という推移をしているのに対し、Onnx Runtime NPUではタスクの最初に30Wまで上る瞬間はあるものの、基本的には25W付近と20W付近を一定間隔で行き来している。FLMも概ね同様だが、Onnx Runtime NPUと比べても最初のピークもなく、23~24W付近と16~17W付近を行き来している。消費電力に関しては明らかにNPUが有利、かつ直接最適化をしていると思われるFLMが最も省電力という結果になった。うたい文句の10倍省電力は言い過ぎかもしれないが。
温度の推移も似た傾向ではあるものの、消費電力ほどの大きな差は見られない。ハイブリッド実行では80℃近くまで上昇するが、Onnx Runtime NPUとFLMは70℃までに留めている。Onnx Runtime NPUとFLMの間にはこれといった差は見られない。
生成速度はほぼ変わらず
生成速度については以下のようになった。
| モデル名 | TTFT | トークン生成速度 |
|---|---|---|
| Qwen2.5 7B Hybrid | 約0.95秒 | 約13トークン/秒 |
| Qwen2.5 7B NPU | 約1.1秒 | 約12トークン/秒 |
| Qwen3 4B FLM | 約1.0秒 | 約15トークン/秒 |
※TTFT(time to first token)は最初のトークンが生成されるまでにかかる時間
FLMであるQwen3 4Bは他とモデルの世代もパラメータ数も異なるので、速度に関して比較をするべきではない。
HybridとNPUについてはほぼ差がない程度と言っていいのではないだろうか。NPUの方がほんの若干TTFTも生成速度も遅いと言えばそうだが、実利用上で体感するほどではないだろう。
肝心のgpt-oss 20Bは?
次に、gpt-oss 20BのFLMとLM Studio上での実行を比較してみよう。
電力消費や温度推移の傾向はQwen2.5 7Bで見た結果と同様。gpt-oss 20Bを低消費電力で実行できるのはかなり良い感じ。
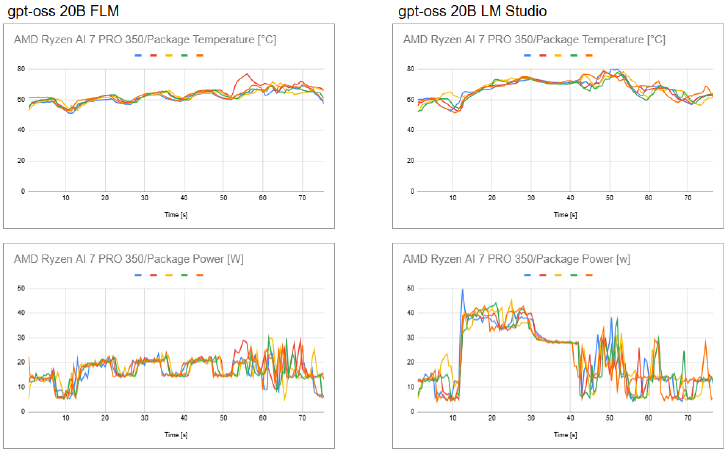 gpt-oss 20Bについて、内部温度と消費電力の推移を比較(クリックして拡大)
gpt-oss 20Bについて、内部温度と消費電力の推移を比較(クリックして拡大)
では生成速度はどうだろうか。
| モデル名 | TTFT | トークン生成速度 |
|---|---|---|
| gpt-oss 20B FLM | 約4.5秒 | 約11トークン/秒 |
| LM Studio gpt-oss 20B | 約1秒? | 約14.5トークン/秒 |
LM StudioバージョンについてTTFTに?をつけているのは、約1秒かかったと表示されるパターンと、0.08秒かかったと表示されるパターンの2種類があり極端で解釈に困ったため。さすがに0.08秒は計測上の不備ではないだろうか。
ただ、LM StudioバージョンのTTFTが1秒だとしてもFLMより3.5秒は速いことになり、トークン生成速度もこちらが優れている。この差は普通に体感できるので、どのシーンでもFLMの方が良いということにはならなさそうだ。
どんぶり勘定ではあるがワットパフォーマンスを計算してみる。FLM実行時の消費電力をざっくり20W、LM Studioでの実行時の消費電力をざっくり35Wとしてみると、
| モデル名 | ワットパフォーマンス |
|---|---|
| gpt-oss 20B FLM | 約0.55トークン/秒W |
| LM Studio gpt-oss 20B | 約0.41トークン/秒W |
となるので、FLM(NPU)で計算した方がワットパフォーマンスはギリギリ良いということになりそうだ。
結論 NPU実行の良い兆しではあるが目指すところとはまだ乖離あり
以上見てきたように、「“NPU搭載”とか言ってもまともなLLMは動かないんでしょ?」というような従来の状況からは変わりつつある。ただ、今回の記事では触れなかったが「AMDのNPUなら」ここまでできるという表現が正しく、米Intelや米QualcommのNPUはまた状況が異なる。
NPU実行であれば内部GPUに比べて低めの消費電力と発熱で推移することを確かめられたのは収穫だったが、ものすごく省電力かと言えば微妙な感触ではある。NPUのピーク性能を出せているとも思えず、これはメモリ帯域がボトルネックになっていると思われる(メモリ帯域からの理論計算と今回の生成速度の実測値が概ね一致する)ので、NPUだけではないハードウェア側の進化や、AIアルゴリズム自体の進化も必要そうだ。
それに外部GPUがあれば今回の実験で示した速度の10倍は出るため、コーディングアシストなどエージェンティックな用途なら依然として外部GPUを用意した方がいいのは変わらない。
今回、AMDのNPUでgpt-oss 20Bを実行する方法も示したが、ではこれをもってNPU利用を他人に薦められるかといったらNOだ。最低限、LM Studioのようなメジャーアプリケーションに統合されてほしい。
やはりNPUのメインターゲットはLLM実行ではないのだろうとは思うが、世間的にはAI=LLMか画像生成AIという風潮ではあるし、そうでなければユーザーの意識に上らないところでもっと全体的に便利にならないだろうかとは感じるところ。そういう意味ではWindows 11の「Recall」や「Windows検索」「Click to Do」あたりはその方針ではあるものの、これらはnice to haveではあるもののmust haveには現状なっていない。これらがあるからAI PCやCopilot+ PCを買いますか、とはなりにくい。
ただ、積極的には買い替えなくてもこのまま行くと次の買い替えタイミングでは市場にAI PCしかないという状態も全然あり得るので、その場合には多くの人が薄く広くNPUのメリットを享受する──という世界になるのかもしれない。
著者:井上輝一
ITmedia NEWS、ITmedia AI+編集長。2016年にITmedia入社。AIやコンピューティング技術、科学関連を取材。2022年からITmedia NEWS編集長に就任。2024年3月に立ち上げたAI専門メディア「ITmedia AI+」の創刊編集長。ITmedia主催イベントで多数登壇の他、テレビや雑誌へも出演歴あり。
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
AIが破壊するIT業界の“人月商売” 「SIerの死」後に“生き残る者”の正体
-
2
「Claude Fable 5」サブスク、突如5日間延長 ユーザー悲喜こもごも「寝ずに頑張ったのに」「制限リセットして」
-
3
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
4
「GPT-5.6」木曜に一般公開へ 米政府と調整→限定プレビュー経て
-
5
マイクロン、AI需要で広島工場増強へ起工式 1.5兆円投資
-
6
Anthropic、「Claude Code」のシステムプロンプトを80%削減 「モデルの創造性を解放するため」
-
7
note上方修正 「AI活用、想定以上」で人件費率低下 2Q累計営業益は「20倍超」に
-
8
現場に聞いた「IT関連50製品」のぶっちゃけ理解度 “浸透するツール”の共通点とは?
-
9
Claude「サブスク最上位プラン」6カ月間無料で提供 OSS開発者向けキャンペーン、対象を拡大
-
10
AIがExcel作業を丸ごと自動化? 企業の定型業務を効率化へ
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR