「アカデミアで国産LLMをやる意味」に対する答え NII所長に聞く、透明性へのこだわり(1/3 ページ)
「日本のアカデミアでやる意味があるのか、という質問は常に受ける」――国立情報学研究所(NII)の黒橋禎夫所長は、4月16日に開催した記者向けの懇談会で、NIIが開発するAIモデルについてこのように打ち明けた。
 黒橋禎夫所長
黒橋禎夫所長
NIIは、2023年から日本語性能の高いオープンなLLMの開発に取り組んでいる。AIモデルは大きく分けて、コードや開発手法を公開しないクローズドモデルと、重み(入力に対して最適に出力するためのパラメータ)などを公開するオープンモデルがある。NIIのモデルは、重みにとどまらず学習プロセスや利用したデータも可能な限り公開し、透明性を重視している点が特徴だ。
直近では26年4月3日に、NII独自のLLM「LLM-jp-4 8Bモデル」「LLM-jp-4 32B-A3Bモデル」を公開した。米OpenAIのクローズドモデル「GPT-4o」や、中国Alibabaのオープンモデル「Qwen3-8B」を上回る日本語性能をうたっている。
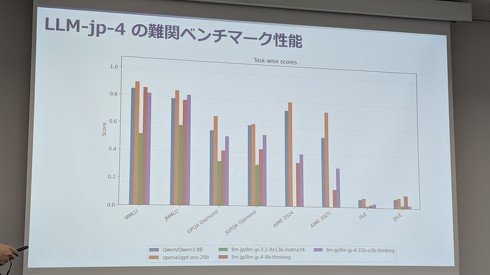 「LLM-jp-4 8Bモデル」「LLM-jp-4 32B-A3Bモデル」のベンチマーク
「LLM-jp-4 8Bモデル」「LLM-jp-4 32B-A3Bモデル」のベンチマーク
一方、GPT-4oは24年5月、Qwen3-8Bは25年4月に登場したモデルで、いずれも26年時点でより性能の優れた後継モデルが出ている。性能面だけを見れば、NIIのAIモデルはやや物足りないだろう。
開発で使える計算資源の規模も「ビッグテックに比べると3桁ほど少ない」と黒橋所長。限られた予算のなかで、AIモデルの開発を進めているという。
そんななか、なぜNIIは独自のAIモデルの開発を続けているのか。黒橋所長が自身の考えを明かした。
企業のオープンモデルは「見通し不透明」
黒橋所長が理由の一つとして挙げるのが、クローズドモデル開発における収益性の問題だ。クローズドモデルの性能は、主に米国企業が率いて飛躍的に高まっている。しかし同時に開発に莫大な資金を投じているため、収益上重要な分野や言語にリソースが集中する可能性がある。
黒橋所長は、最先端のクローズドモデルの開発では「AIと人類の在り方」にも関わる人文・社会科学や文化的な側面を十分に扱えていないと指摘する。「日本は収益上有用なドメインに入っている」としつつも、マイナーな言語などクローズドモデルで“見落とされる領域”の重要性を訴えた。
一方、オープンモデルについても、海外企業に依存するリスクがある。オープンモデルを巡っては、米MetaのAIモデル「Llama」が一時期注目を集めたが、近年では勢いが衰え、代わりにAlibabaの「Qwen」シリーズなど中国勢が台頭している。
しかしQwenシリーズに関しても、26年3月に主要なメンバーが開発チームからの離脱を表明している。黒橋所長はこうした状況の変化に触れ、「企業主導のオープンモデル開発の見通しは不透明」と指摘する。
そうしたなか、現在注目されているのが「ソブリンAI」という概念だ。意味がはっきりと定まっているわけではないが、ソブリンは主権という意味で、データやインフラを自国で完結させるものを指すことが多い。黒橋所長は「私の気持ちとしては自分たちで判断できる土台を持っていること」という。
「何の備えもなくQwenだけを使っていて、Qwenが無くなったらどうするのか。日本としてAIやデータをコントロールできるようにしておきたい」(黒橋所長)
またLlamaやQwenなどは、モデルの重みしか公開していないという課題もある。学習データや開発手法はブラックボックスで、モデルの出力にどのようなバイアスがかかっているか分からない。同モデルをベースに出力を調整すれば計算コストは抑えられるものの、「Science for AI」(AIのための科学)に寄与する知見はそれほど得られないとした。
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
公式がワンコーラス公開→AIで無断フルコーラス化、拡散 大原ゆい子氏「無職転生III」OPが被害
-
2
ChatGPTで広告表示へ 無料・Goプランが対象 6月22日にポリシー更新
-
3
AIエージェントもフィッシング詐欺に引っかかる? 米セキュリティ企業がOpenClawで検証 結果は……
-
4
「Siri AI」の進化に「Geminiそのまま」の誤解――現地取材で見えた“新生Apple Intelligence”の全貌
-
5
「ChatGPTのコネクタでつながるし、M365 Copilotいらなくない?」→有識者3人に聞いてみた 知らないと損するコンテキスト管理「Work IQ」の仕組み
-
6
政府・著名人のInstagramアカウントが次々に乗っ取り被害 原因はMetaのAIアシスタント?
-
7
JASRAC、「AI作曲・人間作詞」の曲は管理します――「人間の創作的寄与の有無」で線引き
-
8
「猫も杓子もAI」な現状は今後も続くのか?【後編】AI時代に必要な3つの検討事項
-
9
Apple「Siri AI」、13億台超が“利用不能”か? 新機能の拡大阻む“弱点”とは
-
10
“机の下でこっそり”AI使う――セールスフォース社長のAIエージェント活用術とは
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR