はやぶさからTSUBAMEへ――日本技術者の底力
はやぶさを無事帰還させた日本技術者の能力の高さは、東工大が11月に稼働予定のペタスケールスパコン「TSUBAME2.0」でも感じることができるかもしれない。ベクトル処理がメインのハイブリッド型はスパコンの主流になるだろうか。

絶対性能および主要なベンチマーク性能で、当時国内最速だった地球シミュレーターを超えることを目的に、東京工業大学のスパコン「TSUBAME」が誕生したのは2006年のこと。38.2TFLOPSという実効性能で世界7位となったこのスパコンはその後、アクセラレータ「ClearSpeed Advance X620」や「NVIDIA Tesla S1070」を接続して性能を向上、TSUBAME1.2にアップグレードした時点で、理論性能は163.2TFLOPS、実効性能は87.01TFLOPSにまで引き上げられて現在に至る。
2010年6月のスーパーコンピュータTop500ランキングでは、64位にランクインしたTSUBAME。これより上位にランクインしている日本勢は、日本原子力研究開発機構(JAEA)など5件だが、地球シミュレータが首位に輝いていたころと比べると、日本の存在感は明らかに陰っている。
東京工業大学は6月16日、2010年11月に稼働予定のTSUBAME2.0について記者向けに説明会を開催した。システムの構築を請け負うのは、日本電気(NEC)と米HPの企業連合。NECが主幹として設計や管理を、HPがノードの開発や電源/水冷装置の設計などを手がけている。
システム、ソフトウェア、冷却設備、4年間の運用費用などを含め総額32億円弱で落札されたTSUBAME2.0だが、このほかに、電源の改修を含めた設置部屋の構築に約2億円、テープ装置に約5000万円、さらに電気代が年間1億円程度、サポートのSE費用が年間数千万円程度必要になるという。
日本初となるペタFLOPSのスパコンはベクトル処理がメインのハイブリッド型
TSUBAME2.0の概要を説明したのは、その誕生からかかわってきた東京工業大学学術国際情報センターの松岡聡教授。同氏によると、TSUBAME2.0のポイントは、「日本初となるペタFLOPSのスパコン」である点、そして、それが超並列・超大規模のスカラ型ではなく、「ベクトル処理を重視したハイブリッド型」である点だという。
HPC領域のワークロードは、計算密度が高い「密問題」と、メモリアクセス密度が高い「粗問題」の2つに大別されると松岡氏。前者に類するのは、多体(N-body)問題などで、従来型のアクセラレータが得意とする領域だ。一方、後者に類するのは数値流体力学(CFD)や高速フーリエ変換(FFT)などで、これらはベクトル型のスパコンが得意とする領域である。ベクトルプロセッサとアクセラレータの両方の性質を持つGPUを採用することで、これらの領域もカバーするハイブリッド型のスパコンを生み出した。
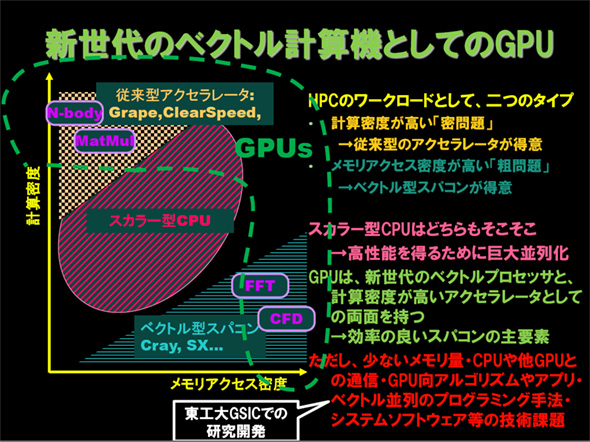
TSUBAME2.0の理論性能は倍精度で2.4ペタFLOPS。これはTSUBAME1.xの30倍の性能で、現時点で「神戸のスパコン(編注:理化学研究所が建設中の汎用京速計算機)が完成するまでは、日本全国に存在するスパコンのすべてを集めても敵わない」(松岡氏)ほどのものだ。
TSUBAME2.0の計算ノードはメモリ容量の違いで「Thin」「Medium」「Fat」の3種類に分けられている。HPとの共同開発で誕生したThin計算ノードは、CPUにIntelのWestmere-EP(2.93GHz、TurboBoost時3.196GHz)を2基、「Fermi」の名前で呼ばれていたNVIDIAの次世代GPU「NVIDIA M2050」を3枚搭載する。これを1408ノード(44ラック)用意することで、GPUの合算ピーク性能2175.36TFLOPSを実現。これにCPUの合算ピーク性能である224.69TFLOPSを加え上述の2.4ペタFLOPSを実現している。なお、LINPACKでの実効性能は1〜1.4ペタFLOPSの間であるとみられ、これを2010年6月のスーパーコンピュータTop500ランキングに当てはめれば、世界2位に相当する性能となる。
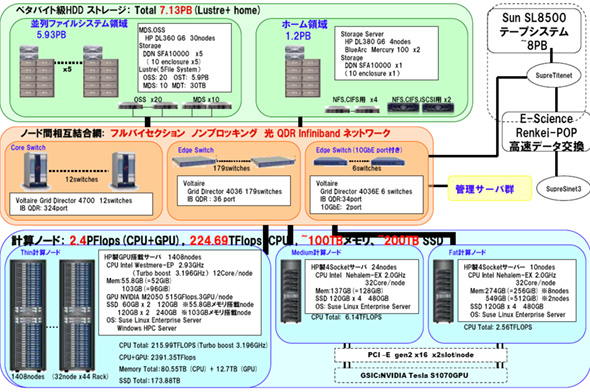
ベクトル処理を重視した設計というだけあって、単にGPUを採用しただけでないのも特徴だ。TSUBAME1の合算メモリバンド幅は1秒当たり17Tバイトだったが、TSUBAME2.0ではこれが720Tバイトになったという。これはベクトル型の地球シミュレータと比較しても4.3倍のバンド幅となる。また、計算ノードはVoltaireのQDR 4 InfiniBandネットワークで接続され、バイセクションバンド幅は毎秒200Tビットを実現しており、演算性能だけでなく、メモリやネットワーク幅も重要な要素と位置づけてシステムが構築されている。
「演算速度も大事だが、消費電力とのバランスが肝要」(松岡氏)
CPUと比べて相対的に演算パワーが高密度なGPUをメインに用いたことで、TSUBAME1.xの時代に約350平方メートルだった主計算ノード群の総設置面積は、約200平方メートルに削減された。また、消費電力もTSUBAME 1.xのピーク時の消費電力が1.3Mワット程度といわれていたが、TSUBAME2.0では、性能を向上させつつも消費電力は1Mワット以下に抑えられているという。これは冷却設備のコスト削減にもつながっており、電力使用効率(PUE)はTSUBAME1.xの1.44から1.28辺りにまで向上すると説明した。
中国の星雲はライバルではない
日本発のペタスケールスパコンとして11月の稼働が待たれるTSUBAME2.0だが、近似したアーキテクチャを持つスパコンがすでに2010年6月のスーパーコンピュータTop500ランキングで2位にランクインしている。中国の深センにある国立スーパーコンピュータセンターに設置されている「Nebulae」(星雲)がそれだ。
Nebulaeの理論ピーク性能は2.98ペタFLOPS、実効性能は1.27ペタFLOPS。スカラ単独型のスパコンと比べると、理論ピーク性能と実効性能のかい離が激しいが、これはTSUBAME2.0も同様で、実効性能こそNebulaeを上回る見込みであるものの、理論性能の53%程度しか出ていない。
松岡氏は、「LINPACKで測定される性能はスパコンの性能の一面でしかない。むしろ、それらが実際のアプリケーションで実現できるのかが現実的な問題。実アプリでほかのスパコンより性能が出ればよいと考えている」とし、実行時間の大半が密行列積(DGEMM)演算で占められるLINPACKの結果に目を奪われるべきではないし、理論ピーク性能と実効性能のかい離は研究開発で今後解消できるものという見解を示す。むしろ問題は、GPU間のダイレクト接続やGPUのフォルトトレラントであり、GPUのチェックポインタの開発の必要性などを説いた。
Nebulaeについては、「調べた限りでは、汎用のブレードサーバを用いた大規模クラスタ型スパコンに『強引に』GPUを押し込んだ設計であり、安定動作という運用面での課題があるように思う。小さな問題しか解けないのではないか」と話し、現時点ではライバルと考えていないと述べた。
実アプリでの性能に自信を見せる松岡氏だが、これはこれまでTSUBAMEを運用してきた中で、GPU/CUDAを用いた高速計算のノウハウが蓄積してきたことを意味している。その一例として、気象庁が次期気象予報に向けて開発を進めている「ASUCA」の気象計算をフルGPU化したことに触れ、スーパーコンピュータTop500ランキングで現在首位のJaguarの約3倍となる150TFLOPSの実効性能を気象コードで実現したと話し、新世代のベクトル計算で強みを生かせる位置にいることをアピールした。
TSUBAME2.0の導入スケジュールは、8月中旬に現システムの縮退運転/部分運転を開始し、8月中にノードを解体、9月に設置作業を行い、10月のテスト稼働/ベンチマークを経て、11月上旬に一般向けの一部本格運用、年内に完全一般運用を目指すとしている。
中長期的なロードマップとしては、2012年の技術を前提に10ペタFLOPS超の性能を持つ「TSUBAME2.5」の基本設計はすでに存在しているとし、資金とニーズがあれば性能拡充も検討するという。その先にある「TSUBAME3.0」は、ノード性能とのギャップが激しいネットワークの革新など、幾つかの課題を超えた先に見えてくるとした。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 合言葉は「みんスパ」――東工大のTSUBAMEが飛翔
合言葉は「みんスパ」――東工大のTSUBAMEが飛翔
東京工業大学は、LINPACKベンチマークで国内最速となる85TFLOPSのスーパーコンピューティンググリッドシステム「TSUBAME」の披露式を開催した。スパコンにおける次のブレークスルーは「人材」であるという。- 東京工業大学、国内最高速スパコンを稼働
東京工業大学で国内最高速となるスパコン「TSUBAME」が本格稼働を開始した。現在85テラFLOPSの処理性能は今後、100テラFLOPSにまで拡張される予定。 - 東工大、GPGPUで次世代気象モデルの高速化に成功
東京工業大学、青木尊之教授の研究室は、気象庁が開発を進めている次世代気象モデルをCUDAでコーディング、GPGPUによる高速な計算を可能にした。GPGPUの適用領域の拡大を示すとともに、天気予報の予測精度の向上につながるものとして期待される。  GPUコンピューティング戦争に勝機を見いだすNVIDIA
GPUコンピューティング戦争に勝機を見いだすNVIDIA
Intel、AMDなどとGPUコンピューティングの覇権を賭けて戦うNVIDIA。自社でCPUの設計も手がけるのではないかとうわさされるNVIDIAだが、新たにチーフサイエンティストに就任したビル・ダリー氏に話を聞いた。 ベクトル機の時代が終わる? GPGPUの夜明けと課題
ベクトル機の時代が終わる? GPGPUの夜明けと課題
「ベクトル型のスパコンと同じ処理性能をGPUコンピューティングであれば、3.5けたほど安い価格で実現できる」――日本SGIが発表したソリューションがベクトル機の存在価値を大きく変えるかもしれない。- 東工大のTSUBAMEが汎用GPU計算アクセラレータで性能強化
東工大が保有する国内最大規模のスパコン「TSUBAME」がGPUボードを用いて大幅な性能強化を実現した。併せてNVIDIA CUDAのレクチャーを含む並列プログラミングの授業を開講するなど、HPC市場でNVIDIAの勢力が強まっている。  無能なITマネジャーと呼ばれないためのキーワードは「PUE」
無能なITマネジャーと呼ばれないためのキーワードは「PUE」
グリーンITが叫ばれる中、サーバの消費電力に目がいってしまうITマネジャーは筋が悪いといわざるを得ない。エネルギーコストをどう削減するかを考えるに当たって、圧倒的な電力効率を持つモバイルデータセンターがHPからリリースされた。その秘密に迫ってみたい。