機械学習にまつわる「データ準備」のAtoZ
AI(人工知能)・機械学習へのチャレンジが、これまでになく身近になっています。2018年後半には数多くの国内事例が発表され、いよいよ実用化のフェーズに入ったことを実感されている方も多いのではないでしょうか。
AI・機械学習の使い手は、今やデータサイエンティストにとどまりません。優れた機械学習プラットフォームの登場や、セルフサービス・民主化の波とともに、あらゆるビジネス部門の担当者が最新のテクノロジーを簡単に使用しながら、未来を予測できるデータの使い方ができるようになってきています。
ところが、機械学習の取り組みが進むほど「学習させるデータによって予測精度が大きく上下する」「予測分析テーマを繰り返し検証したいのに、教師データの準備に時間がかかり検証が限られてしまう」といった課題が顕在化し始めています。
本コラムでは、このような課題の解決策として注目される「データ準備(データ・プレパレーション)」をテーマに、機械学習を成功に導くポイントを探っていきます。
※本稿は、株式会社アシストによる寄稿記事です。
機械学習のスタートは「データ準備」
機械学習というと予測モデルの生成に主眼が置かれがちですが、機械学習のプロセス全体では、モデルの生成はその一部であることが分かります。
元となるデータのクリーニングや欠損、変換などに全て対応して、ようやくアルゴリズムにデータを入れられるようになるため、データ準備は機械学習のスタート地点となっています。
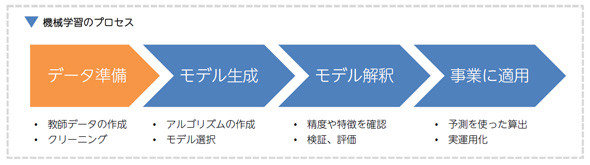
準備されたデータを基に予測モデルが構築され、その予測が事業に導入されて、意思決定や行動を変えていくインパクトを考えると、機械学習におけるデータ準備は重要な意味をもつことが分かります。
90%がデータ準備の重要性を実感! 機械学習の成功のカギは「データ」にある
機械学習の現場では、ユーザーの90%が「事前のデータ準備が重要である」と考えています。機械学習の実践が長く、より多くの予測分析テーマを検証しているユーザーほど、その重要性を実感しています。
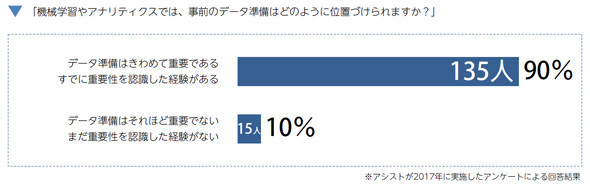
機械学習のためのデータは、重要性が認識されながらも、その準備は簡単ではありません。優れた機械学習プラットフォームによって、モデルの生成プロセスは自動化が進む一方、元となるデータは私たちが手動で準備しなければならないからです。モデルの生成スピードが上がるほど、データ準備にかかる時間が機械学習のボトルネックになってきています。
なぜデータの準備は難しいのか?
機械学習では、データに含まれる値からパターンを検出し、予測モデルを構築していきます。どの値がインパクトを与えているのか、要因や特徴量は全てデータから導き出されるため、足りないデータがあれば追加し、不要なデータは削除する作業を繰り返していきます。
誤差のないデータを準備するには補正やクリーニングを行い、よりリッチなデータへと強化するには複数のデータソースを組み合わせ、名寄せや計算を行いながらデータセットの準備を進めます。
ビジネス部門のユーザーは事業データの理解を持ち合わせていますから、生成された予測モデルのアルゴリズムを読み解き、次に必要なデータが何かが分かります。しかし、この作業を自分で行っていくには、依然として高度なITスキルが求められるのです。
データ準備の課題をクローズアップ
こちらのグラフは、機械学習や分析で活用したいデータをたずねたアンケート結果です。
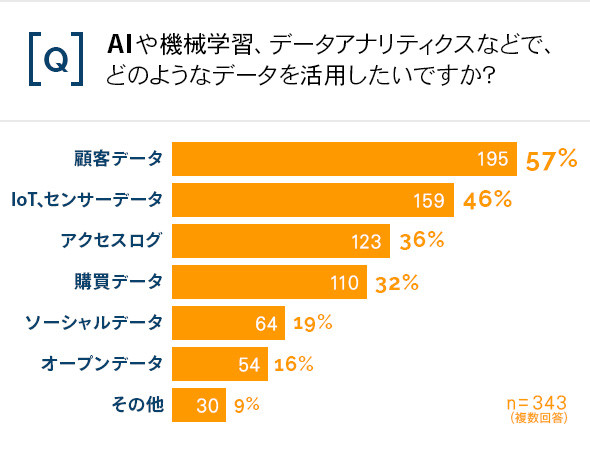
ランキング上位の「顧客データ」は、社名や氏名の不一致やゆらぎ、半角全角、法人格の位置、郵便番号や電話番号に含まれる記号の扱いなど、クレンジングが必須となるデータの代表格ですし、「センサーデータ」は欠損を補正しなければ思い通りの使い方ができません。
結合、追加、分割、ソート、計算、変換、補間……などを繰り返してデータを仕上げていくには、データの種類とボリュームが増え続ける中、従来の手法では間に合わなくなってきています。
何より、ビジネス部門のユーザーが自分たちで機械学習に取り組めるようになっているにもかかわらず、データ準備は従来のままExcelで行うか、データサイエンティストやIT部門に依頼するしか選択肢がないままでは、データ準備における時間のロスは大きな機会損失を招いてしまうかもしれません。
思い通りにデータを準備できるセルフサービス型のデータ・プレパレーションとは
機械学習の発展とともに拡大するこのようなデータをめぐる課題を解決する手段として、データ・プレパレーションが注目されています。
企業向けのデータ・プレパレーションとして開発された「Paxata」(パクサタ)は、Excelのようなスプレッドシートにデータを読み込むだけで可視化し、マウスのクリック操作だけで、必要なデータに仕上げていくことができるセルフサービス型のデータ・プレパレーション製品です。
もっと早くもっと簡単に、ビジネス部門のユーザーが自分でデータを準備できるようになれば、機械学習のスタートボタンをもっと早く押せるようになり、何度もデータを作り替えながら、モデルを洗練させていけるようになります。
Paxataなら、これまでのデータ準備の方法を一新して、桁違いのスピードで、桁違いの仮説や分析テーマを導き出せるデータを即座に準備できます。
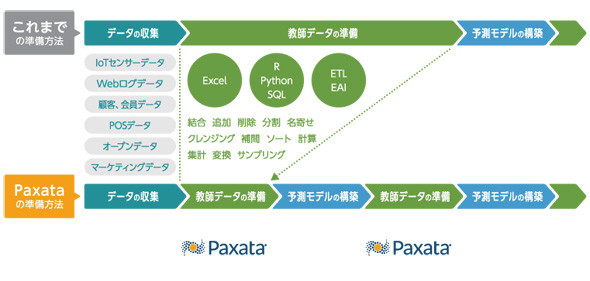
ユースケースで紹介! データ準備の速度を上げて、予測の精度を上げた事例
Paxataを導入した国内のユースケースを2つご紹介します。
1つ目の企業様では、営業部門向けに、ビジネスポテンシャルの高い顧客を自動的に抽出して、レコメンドする仕組みを構築されています。取引履歴や顧客マスタのデータをPaxataで加工し、機械学習にかけることで、現在はホワイトスペースとなっているものの、アプローチすることによって自社の商品サービスを提案できる可能性のある顧客を機械学習で探り当てて、担当営業に通知できるようになりました。
2つ目の企業様では、センサーの時系列データを研究開発(R&D)に役立てるにあたり、ExcelやPythonに替わる手法としてPaxataを採用されました。コーディングでしか整形できなかった時系列データをPaxataで簡単に補正できるようになり、データの一部を抜き出したサンプリングではなく、フルデータセットとしても準備できるようになり、機械学習の精度を格段に向上できるようになりました。
どちらのユースケースでも、ビジネス部門のユーザーが、自分でデータの準備から機械学習での予測、その予測をもとにした事業への組み込みをセルフサービスで行っている点に特長があります。これまでのデータ準備を新しい方法に置き換えることで、従来は当たり前のようにかかっていた時間と手間を圧倒的に短縮し、データを最大限に活用する使い方へとシフトしています。
機械学習はまだまだ新しいテクノロジーですが、もう既にビジネスの現場で使うことができます。機械学習の価値は、ビジネス部門のユーザーが現場にある課題を見つけて仮説を立て、機械学習で検証して、課題を解いてアクションにつなげることにあるといわれています。
予測モデルの生成が自動化された今、機械学習の成功のカギは、ビジネスの現場にいるユーザーが事業の知見を生かしながらデータを活用できるかどうかにかかっています。データ・プレパレーションを新たな手段に、さらなるチャレンジを進めてみませんか?
「機械学習におけるデータ準備」に課題を感じている方へ
機械学習におけるデータ準備の課題を解決するためのポイントをまとめた資料が、下記のサイトからダウンロードできます。機械学習をスピードアップしたい、予測分析モデルの精度を向上したいとお考えの方はぜひご覧ください。
筆者紹介:古賀さとみ

株式会社アシスト ビジネス推進部 課長
2001年、アシスト入社。帳票製品のフィールド業務を経験後、BIやEAI、ETL製品のマーケティング、プロモーションに従事。2016年より「Paxata」ビジネスの立ち上げに参画し、データ・プレパレーション分野のアウェアネス向上とリードジェネレーションをミッションとしている。
Copyright © ITmedia, Inc. All Rights Reserved.
提供: 株式会社アシスト
アイティメディア営業企画/制作:ITmedia NEWS編集部/掲載内容有効期限:2019年1月26日


![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。