画像生成AIに“AIが作った画像”を学習させ続けると? “品質や多様性が悪化” 「モデル自食症」に:Innovative Tech
米ライス大学と米スタンフォード大学に所属する研究者らは、AI生成画像(合成データ)を用いて別の生成モデルが学習し続けると、その精度にどのような影響がでるのかを検証した研究報告を発表した。
Innovative Tech:
このコーナーでは、2014年から先端テクノロジーの研究を論文単位で記事にしているWebメディア「Seamless」(シームレス)を主宰する山下裕毅氏が執筆。新規性の高い科学論文を山下氏がピックアップし、解説する。
Twitter: @shiropen2
米ライス大学と米スタンフォード大学に所属する研究者らが発表した論文「Self-Consuming Generative Models Go MAD」は、AIが生成した画像(合成データ)を用いて別の生成モデルが学習し続けると、その精度にどのような影響がでるのかを検証した研究報告である。
結果は、AIモデルを合成データでトレーニングすると、画像が乱れるアーティファクトが徐々に増幅され、品質や視覚的多様性のいずれにおいても悪化する結果を示した。研究チームは、この状態を狂牛病になぞらえて「Model Autophagy Disorder」(モデル自食症)と呼んでいる。

生成AIモデルの学習データセットはインターネットから入手される傾向があるため、今日のAIモデルは、知らず知らずのうちにAIが合成したデータで学習されるようになっている。
実世界のサンプルを入手するよりも、学習データを合成する方がはるかに簡単、迅速、かつ安価である要因が含まれる。また合成データは、医療画像のような機密性の高いアプリケーションにおいて、プライバシーを保護する利点もある。さらに、大規模言語モデルがますます巨大化するにつれ、それらを訓練するのに必要な実データが不足してしまい、合成データに頼らざるを得なくなっている。
画像生成AIが作成した画像には、品質が低いものや偏ったものなど、望ましくないものが多く含まれている。このため、AIが生成した画像がインターネット上で増えるにつれて、画像の品質や多様性が大きく低下する可能性がある。また、合成データに偏りが生じる可能性もある。
研究者らは、GANモデルと拡散モデルの生成AIに対する影響を検証した。最初に、それぞれのモデルは以前の世代から収集したAI生成画像に対して反復的に学習させた。数世代が経過すると、StyleGAN画像ジェネレーターが生成した人間の顔には波状の視覚的パターンが現れるようになり、拡散画像ジェネレーターではぼやけていく傾向を確認した。

別の実験において、AI生成画像の中から、より品質の高いものを選んで学習に使用することで、画質の低下を遅らせることができると分かった。しかし、StyleGAN画像ジェネレーターが最終的に顔の特徴も肌の色も似ている人間の顔を大量に生成するため、多様性の喪失が見られた。
別のシナリオでは、研究者はAIが生成した画像を含むトレーニングセットに、一定の実画像データセットを含ませた。結果は、画像の質や多様性の低下を遅らせるだけにすぎなかった。
最後に、AI生成画像と実画像データの組み合わせで各モデルを訓練した。これは、品質や多様性の低下を食い止める上で最も有望な結果につながった。ただし、訓練に使用するAI生成データの量が一定の閾値に制限されている場合に限った。
この結果から良好な学習をしたい場合に考えられるのは、実画像データを多く使用すること、そして合成データは電子透かし技術(生成AIが作った画像に電子透かしを埋め込んで識別できるようにする手法)などで選別して使用割合を少なくすることが挙げられる。
Source and Image Credits: Alemohammad, S., Casco-Rodriguez, J., Luzi, L., Humayun, A. I., Babaei, H., LeJeune, D., … & Baraniuk, R. G.(2023). Self-Consuming Generative Models Go MAD. arXiv preprint arXiv:2307.01850.
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
 GPT-4の精度は悪化している? 3月に解けた数学の問題解けず GPT-3.5にも敗北──米国チームが検証
GPT-4の精度は悪化している? 3月に解けた数学の問題解けず GPT-3.5にも敗北──米国チームが検証
「GPT-4の精度は時間と共に変わっている」──そんな研究成果を米スタンフォード大学と米カリフォルニア大学バークレー校の研究チームが発表した。3月と6月時点のGPT-4の精度を比較したところ、一部タスクでは精度が大きく悪化していたという。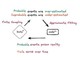 生成AIに“生成AIが作った文章”を学習させ続けるとどうなる? 「役立たずになる」と英国チームが報告
生成AIに“生成AIが作った文章”を学習させ続けるとどうなる? 「役立たずになる」と英国チームが報告
英オックスフォード大学や英ケンブリッジ大学、英インペリアル・カレッジ・ロンドン、米トロント大学に所属する研究者らは、GPT-4などの大規模言語モデル(LLM)が別のLLMが生成したテキストを学習し続けるとどうなるかを調査した研究報告を発表した。 「ChatGPT vs. Google」どっちで検索する? 95人を対象に米研究者らが違いを調査
「ChatGPT vs. Google」どっちで検索する? 95人を対象に米研究者らが違いを調査
米マイアミ大学に所属する研究者らは、情報探索タスクに検索エンジン(Google)とAIチャットツール(ChatGPT)を使用する際のユーザーにおける行動や考え方の違いを調査した研究報告を発表した。 言語生成AIの入力文、最初と最後に“重要情報”を入れた方が良い結果に 米スタンフォード大などが検証
言語生成AIの入力文、最初と最後に“重要情報”を入れた方が良い結果に 米スタンフォード大などが検証
米スタンフォード大学などに所属する研究者らは、大規模言語モデル(LLM)の性能について、入力コンテキストの長さや関連情報の位置を変えることでどのような影響があるかについて調査した研究報告を発表した。 企業の“生成AI活用”のトレンドは? 他社モデル活用と独自モデル開発、東大発ベンチャー・ELYZAが解説
企業の“生成AI活用”のトレンドは? 他社モデル活用と独自モデル開発、東大発ベンチャー・ELYZAが解説
国内外問わず、さまざまな企業で言語生成AIの利用が急速に進んでいる。東大発ベンチャー・ELYZAは、他社製のAIモデルを活用する動きと、独自の大規模言語モデルを開発する動きの2つがトレンドになっていると指摘。それぞれの特徴について解説した。