AIは強化学習で“人間のだまし方”を学ぶ──RLHFの副作用、海外チームが24年に報告 「正解っぽい回答」を出力
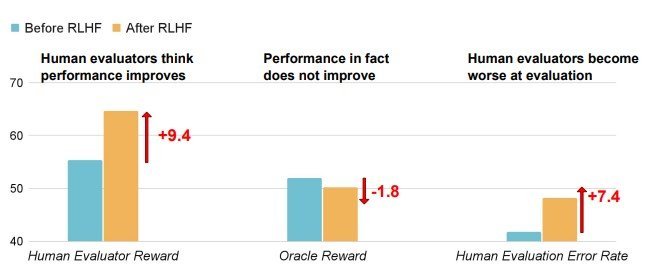
長文理解のための質問応答データセットによる、RLHF前(青)とRLHF後(黄色)のAIモデルにおける、人間の承認率(左)、実際の性能(中央)、人間のエラー率(右)を表した図




Copyright © ITmedia, Inc. All Rights Reserved.
SpecialPR
Copyright © ITmedia, Inc. All Rights Reserved.
SpecialPR