Google、次世代音声AI「Gemini 3.1 Flash TTS」 自然言語で表現を制御可能に
米Googleは4月15日(現地時間)、自然な音声を生成するAIテキスト読み上げモデル「Gemini 3.1 Flash TTS」(TTSはText-to-Speechの略)を発表した。開発者向けには「Gemini API」および「Google AI Studio」で、企業向けには「Vertex AI」でプレビュー提供されるほか、Google Workspaceユーザーも「Google Vids」を通じて一部の機能を利用できる。
 (画像:Google)
(画像:Google)
ユースケースとしては、開発者や企業、一般ユーザーによる次世代のAI音声アプリの構築などが挙げられる。新たに導入された「音声タグ」機能により、自然言語のコマンド(「ゆっくり話す」「ささやくように」など)をテキストに直接埋め込むことで、声のスタイルや話すペース、表現方法を細かく制御できるのが特徴だ。これにより、日本語を含む70以上の言語で、複数話者による自然な会話劇の設定や、表現力豊かで没入感のある音声体験を作り出せるとしている。
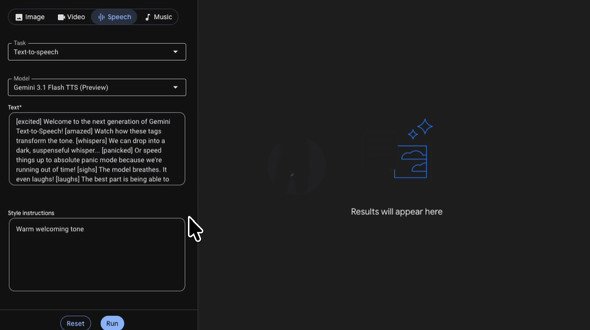 Vertex AIで音声タグを使う(画像:Googleの動画より)
Vertex AIで音声タグを使う(画像:Googleの動画より)
ベンチマークでは、人間のブラインドテストによる好みを集計した「Artificial Analysis TTS」リーダーボードで1211という高いEloスコアを記録した。さらに、高品質な音声生成能力と低コストという理想的なバランスを両立しているとして、同ベンチマーク内で「most attractive quadrant」(最も魅力的な象限)に位置づけられるなど、高い評価を受けている。
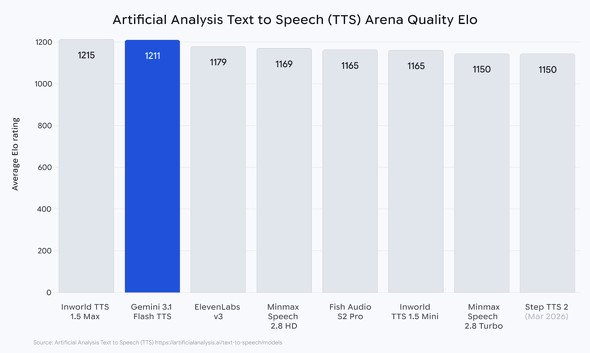 「Artificial Analysis TTS」結果(画像:Google)
「Artificial Analysis TTS」結果(画像:Google)
安全性の面では、このモデルで生成されたすべての音声に電子透かし技術「SynthID」が適用される。人間の耳には聞こえない透かしを音声データに直接埋め込むことで、AI生成コンテンツであることを確実に検出し、誤情報の拡散を防ぐ仕組みとなっている。これに加えて、GoogleのAI原則や安全に関するポリシーに基づき、開発段階から社内チームによる安全性評価やレッドチーム演習を実施しているという。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
「Claude Fable 5」サブスクに統合 Max・Team Premiumプラン対象
-
2
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
3
Google、「NotebookLM」を「Gemini Notebook」に改称 Geminiエコシステムへの統合を強化
-
4
NTT、独自のAIモデル「tsuzumi 2」発表 “国産AI開発競争”に「負けられない」と島田社長
-
5
強気値上げで自爆か ClaudeやGeminiに押され「M365 Copilot」は一人負け?:888th Lap
-
6
「AIと壁打ちはもう古い」 業務タスクを任せる「Claude Cowork」の落とし穴
-
7
ソフトウェアエンジニアの仕事は「ループを書くこと」になる 内側ループと外側ループ(ハーネス)入門
-
8
日本再起の旗印となるか、国産マルチモーダルAI基盤「FRONTia」が始動
-
9
「スマホで動く」270億パラメーターLLM「Bonsai 27B」登場
-
10
NEC森田社長が語る「脱・人月商売」の行方 組織の壁を破るAI人材育成法
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR