富士通、LLMの軽量化技術を発表 1ビット量子化でも約9割の精度を維持 3倍に高速化も
富士通は9月8日、大規模言語モデル(LLM)を軽量化・省電力化する技術「生成AI再構成技術」を開発したと発表した。同社が独自開発した量子化技術と特化型AI向け蒸留技術を採用。富士通のAIモデル「Takane」にこの技術を適用したところ、従来の主流手法よりも大きく上回る成果を得たという。
LLMのような層が多いニューラルネットワークの場合、従来手法では量子化による誤差が指数関数的に蓄積する課題があった。そこで同社は、層をまたいで量子化誤差を波及させて誤差の増大を防ぐ新たな量子化アルゴリズム「QEP」を開発。併せて、独自開発した最適化アルゴリズム「QQA」を活用することで、LLMの1ビット量子化を実現した。
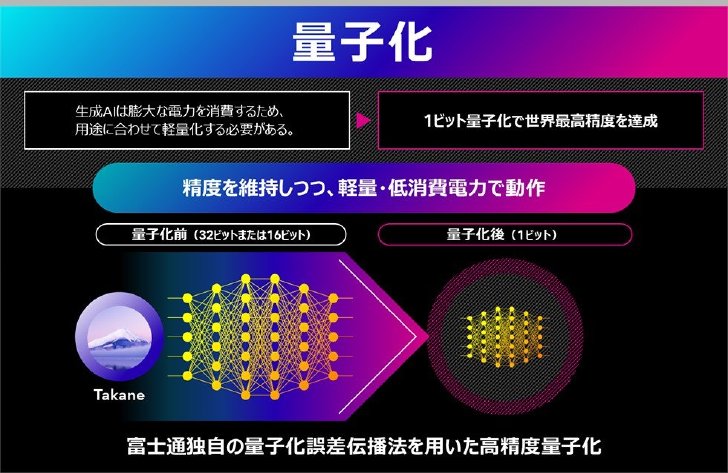 量子化技術の概要
量子化技術の概要
この量子化技術をTakaneに適用したところ、1ビット量子化で、量子化前と比較して精度維持率89%、量子化前の3倍の高速化を実現したという。従来の主流手法(GPTQ)の精度維持率は20%以下であるが、富士通の技術はこれを大きく上回った。「ハイエンドのGPU4枚を必要とする大型の生成AIモデルを、ローエンドのGPU1枚で高速に実行することが可能となった」(同社)
蒸留技術については、基盤モデルに対して不要な知識をそぎ落としたり、新たな能力を付与したりする作業を通して、多様な構造を持つモデル候補群を作成。この候補群から顧客の希望に沿う最適なAIモデルを自動選定する仕組みを構築した。最終的に選定したモデルに対して、教師モデルの知識を蒸留。単なる圧縮ではなく、特定のタスクに特化したAIモデルの構築法を開発した。
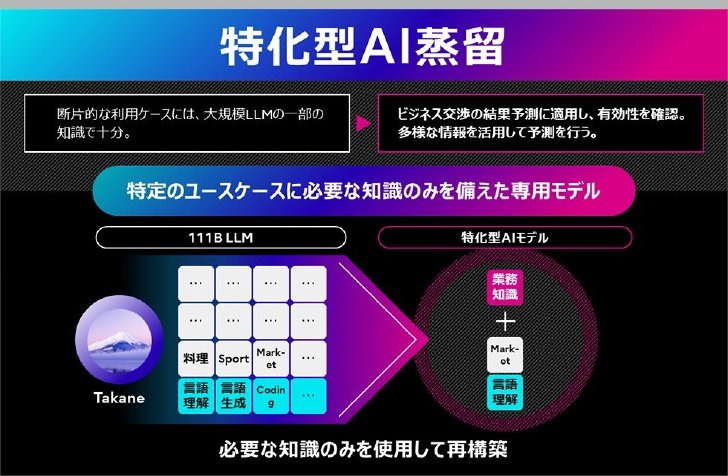 特化型AI蒸留技術の概要
特化型AI蒸留技術の概要
この蒸留モデルをテストしたところ、各商談の勝敗を予測するテキストQAタスクの実証では推論速度が11倍に高速化し、精度は43%改善できたという。富士通は「高精度化とモデル圧縮を同時に実現することで、教師モデルを超える精度を、より軽量な100分の1のパラメータサイズの生徒モデルで達成できることを確認した」と説明。GPUメモリと運用コストをそれぞれ70%削減できたとアピールする。
カナダのCohereの研究用オープンウェイト「Command A」をこの技術で量子化したAIモデルをHugging Face上で公開している。
富士通は今後、これらの技術を独自モデルであるTakaneに適用し、さまざまな専門性を持つ軽量AIエージェントを開発・提供していく。
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
「今日言うつもりはなかったが……」 孫正義氏が明かした「ロボット自動量産工場」の実態
-
2
【役に立つの?】「Google公式」の初心者向けAI講座、受けてみたら想像以上にすごかった
-
3
Flashの再来? Figmaの新機能「Figma Motion」に懐かしいとの声 アニメーション生成するAI機能も
-
4
味の素、“万能DX人材”増員へ 育成のきっかけは新規プロジェクトの苦い経験
-
5
リコーが多能工ヒューマノイドを披露、工場ではPoCから導入に向けた実証段階へ
-
6
日立、メインフレーム事業から撤退へ ハード製造終了から9年後の決断
-
7
ClaudeをSlackチャンネルに召喚、“チームの一員”として直接指示 新機能「Claude Tag」登場
-
8
富士通と日本IBMの協業、ついに始動 COBOL刷新における「役割分担」は?
-
9
男性に美人局容疑で3人逮捕 ChatGPTの示談相場示し脅迫か 警視庁
-
10
【解説】キオクシアなぜ急成長? 半導体メモリって何? AIブームを見通すための基礎知識
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR