Meta、1600言語対応の音声認識「Omnilingual ASR」発表 GitHubで公開
米MetaのAI研究部門であるMeta FAIR(Fundamental Artificial Intelligence Research)チームは11月10日(現地時間)、1600以上の言語で話し言葉を文字起こしできるという自動音声認識システム「Omnilingual ASR」を発表した。Apache 2.0ライセンスの下、GitHubで公開した。
従来のASRシステムは、インターネット上で十分なデータが揃っている一部の言語に焦点を当てており、高い性能を発揮するためには大量のラベル付きデータに依存していた。Omnilingual ASRは、これまでどのASR技術にも対応されていなかった500以上のリソースの少ない言語を含む1600以上の言語をサポートするという。
ここまでの多言語対応が可能になったのは、AIアーキテクチャのスケーリングによるという。従来のシステムでは、普遍的にスケールするにはデータ要求が大き過ぎるという課題に対し、Omnilingual ASRは、まず自己教師あり学習(SSL)を用いた音声エンコーダを70億パラメータまでスケールアップさせ、多言語にわたるロバストな音声表現を学習した。この機能は、公開データセットと地域コミュニティから報酬付きで収集された音声記録を統合した、ASR用としてこれまでに収集された中で最大かつ最も言語的に多様なトレーニングコーパスに基づいているという。
システムのおおまかな仕組みはエンコーダデコーダアーキテクチャを採用している。音声エンコーダが音声から表現を抽出し、テキストデコーダがこれを文字トークンにマッピングするというものだ。特に、ASR性能の飛躍的な向上をもたらすLLM-ASRと呼ばれるアプローチを導入している。これにより、スケーラブルなゼロショット学習が可能となり、サポートされていない言語の話者であっても、わずかな音声とテキストのペアのサンプルを提供することで、新しい言語に文字起こし能力を拡張できる。
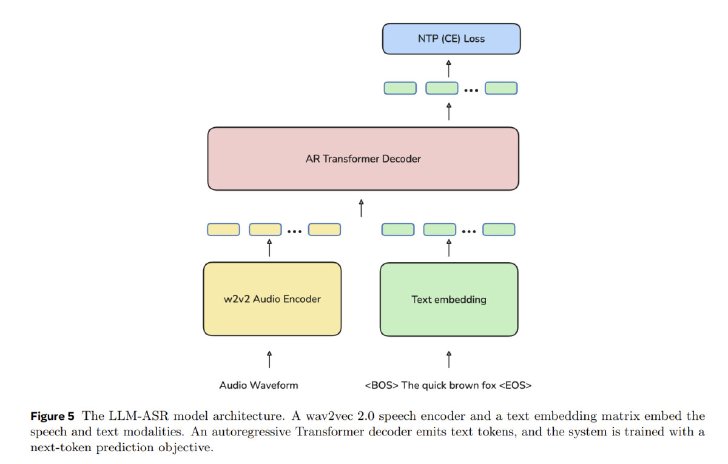 LLM-ASRの概念図(画像:Metaの論文より)
LLM-ASRの概念図(画像:Metaの論文より)
従来のシステムでは、リリース時に含まれていない言語を追加するには専門家によるファインチューニングが必要だったが、Omnilingual ASRは、専門知識や大規模な計算リソースを必要とせずに、コミュニティが自身のデータで言語認識を拡張できる柔軟なフレームワークを提供するという。
このシステムは、最大限の精度を提供する強力な7Bモデルから、低電力デバイス向けに設計されたコンパクトな300Mモデルまで、用途に応じたモデルファミリーとしてリリースされている。
現在の制限として、推論時には40秒未満の音声ファイルのみが受け付けられており、無制限の長さの音声ファイルへの対応も、間もなく追加される予定だ。
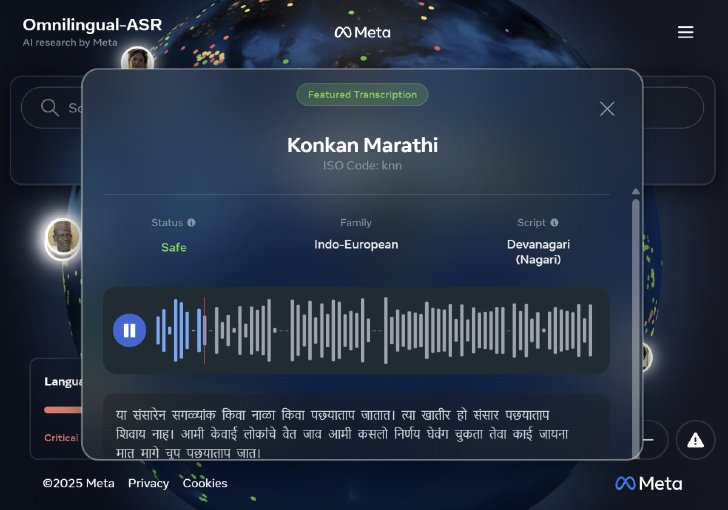
Metaのサイトでデモを見ることが可能だ。
FAIRは今後、Omnilingual ASRをLLMと組み合わせた会話エージェントへの応用や、地域コミュニティが管理するアーカイブへの組み込み、音声翻訳技術への拡大などを計画している。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
Claude、利用制限を全リセット 競合「GPT-5.6」公開と同日……OpenAI幹部「ビビってるね」
-
2
デスクトップ版ChatGPT大幅刷新 AIエージェント「Codex」統合、「ChatGPT Work」に
-
3
「まるで人間」 OpenAIの新モデル「GPT-Live」のトーク力が話題 間を空けずに考えながら会話できる
-
4
Claude「サブスク最上位プラン」6カ月間無料で提供 OSS開発者向けキャンペーン、対象を拡大
-
5
テスラ車内で「Grok」と会話、日本でも展開へ ナビ設定やルート確認を音声で
-
6
Anthropic、「Claude Code」のシステムプロンプトを80%削減 「モデルの創造性を解放するため」
-
7
「生成AIをもう手放せない人」が約6割 逆に“使わなくなったもの”1位は?
-
8
NEC、Claudeを活用した「全自動」マーケティングサービス開始 3年で売上100億円目指す
-
9
M365 CopilotにOpenAI最新モデル「GPT-5.6」追加 複雑な作業を「より効率的に処理」
-
10
三菱自動車が「国産人型ロボ」量産へ 2027年に「月1000台の製造体制」 東大発スタートアップと協業
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR