NVIDIA、エージェント型AI開発向けオープンモデル「Nemotron 3」発表
米NVIDIAは12月15日(現地時間)、エージェント型AIの構築に最適化されたオープンな基盤モデルファミリー「Nemotron 3」を発表した。

計算資源とユースケースに応じて選択可能な「Nano」「Super」「Ultra」の3モデル構成。モデルの重みだけでなく、データセット、トレーニングレシピ、開発ツールチェーンを含めたフルスタックのオープンソースとして提供される。
Nemotron 3は、アーキテクチャにハイブリッドなMixture-of-Experts(MoE:混合エキスパート)を採用している。8月に発表した「Nemotron Nano 2」の設計思想を継承しつつ、大規模なエージェントワークフロー向けに改良を加えたものだ。推論時にアクティブになるパラメータを動的にルーティングすることで、高スループットを維持しながら、複雑な推論タスクにおける回答精度を向上させたとしている。
最大100万トークンにおよぶロングコンテキストへの対応も特徴だ。これにより、RAG(検索拡張生成)における大量ドキュメントの参照や、長期記憶を必要とするマルチターン対話、複数のサブエージェントが連携してコード実行やAPIコールを行う「マルチステップ推論」で、コンテキスト落ちを防ぎながら安定した挙動を実現する。
まず提供が開始された「Nemotron 3 Nano」は、ファミリーの中で最も軽量なモデルで、エッジデバイスやローカル環境での高効率な推論をターゲットとしている。
Hugging Faceでの技術解説によると、Nanoモデルは品質と推論効率のトレードオフを極限まで最適化しており、商用利用やリサーチ用途に耐えうる「実用的な小規模モデル」として設計されている。開発者は、自身のタスクに合わせてSFT(教師ありファインチューニング)やRLHF(人間からのフィードバックによる強化学習)を追加で行い、独自の派生モデルを作成・配布することが可能だ。
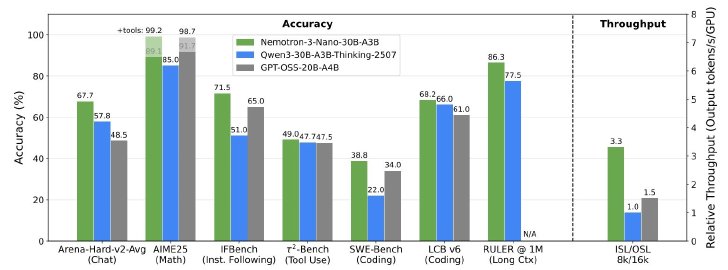 (画像:NVIDIA)
(画像:NVIDIA)
NVIDIAはNemotron 3を、単なるLLMではなく「次世代エージェントシステムの基盤」と位置付けている。事前学習から指示追従(Instruction Tuning)、アライメントまでのプロセスを透明化し、学習レシピを公開することで、開発者はモデルの挙動を深く理解し、再現性を担保できるとしている。
また、このモデル群はNVIDIAのH100やBlackwellアーキテクチャ上のTensorRT-LLMで最大化されるよう最適化されてはいるが、オープンモデルとして提供されるため、幅広い環境での検証が可能だ。NVIDIAはこれにより、エンタープライズレベルの複雑なエージェントワークフローを、ブラックボックス化させずに構築できるエコシステムの確立を狙う。
上位モデルである「Super」および「Ultra」も、今後順次リリースされる予定だ。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
2
AIに「相手に電気ショックを与えろ」と命じ続けたらボタンを押すのか? 11のLLMで“ミルグラム実験” 抵抗できたのは……
-
3
Sakana AI、一部「ミュトス越えの性能」うたうAIを提供 複数モデルの“集合知”を活用
-
4
復活した「Fable 5」 米政府からのオーダーに対して、Anthropicはどう対策したのか
-
5
ソフトウェアエンジニアの仕事は「ループを書くこと」になる 内側ループと外側ループ(ハーネス)入門
-
6
Anthropicの営業はAIエージェントをこう使う! 日本法人メンバーが明かす手の内
-
7
人型ロボットが工場で稼働する様子を6日間生配信、作業成功率99.99%をうたう 中国メーカー
-
8
光接続の標準規格「OCI」対応シリコン、GFが27年に投入
-
9
AIで“ゲームキャラの出産二次創作”を何千回と生成する人も……ChatGPTの会話57万件から見えたヘビーな利用実態
-
10
「Mythosがないと守れない」は本当か——AIセキュリティの勝負を分ける「ハーネス」とは
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR