NVIDIA、日本語データセットを公開 日本文化など反映した合成ペルソナ600万件 商用利用も可能
米NVIDIAは9月23日(現地時間)、日本語の合成データセット「Nemotron-Personas-Japan」を、Hugging Face上で公開した。日本の文化や人口統計などを反映したペルソナ600万件を含んでおり、データやシステムを国内インフラ内で完結させる「ソブリンAI」の開発での利用を想定する。ライセンスは、商用利用も可能な「CC BY 4.0」。
Nemotron-Personas-Japanの開発には、同社の企業向け合成データ作成サービス「NeMo Data Designer」を利用した。同データセットは、日本語で記述された600万件のペルソナを含んでおり、総トークン数は約14億。日本の人口統計や地理的分布、文化的特性などを反映するよう設計しており、各ペルソナには約95万の固有名や、1500以上の職業カテゴリーなどを割り当てた。
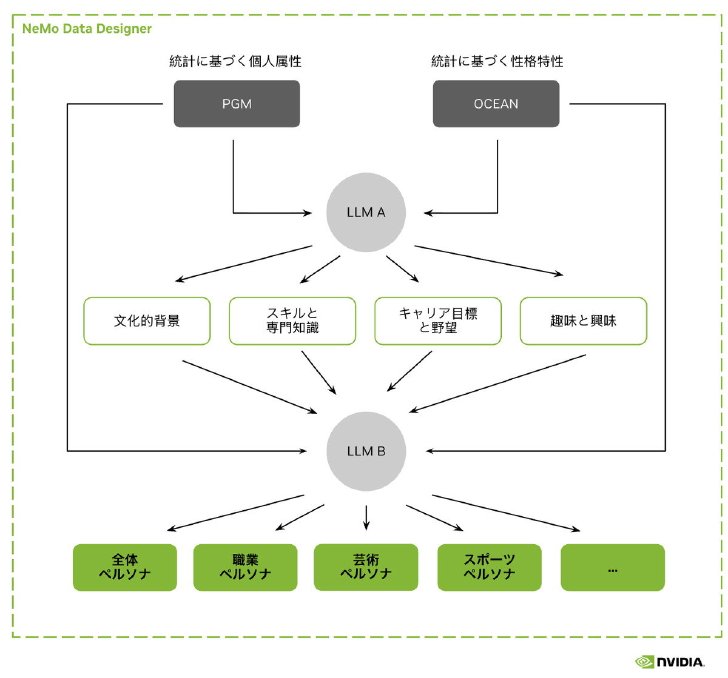 NeMo Data Designerによる合成データ作成の概要(出典:公式ブログ、以下同)
NeMo Data Designerによる合成データ作成の概要(出典:公式ブログ、以下同)
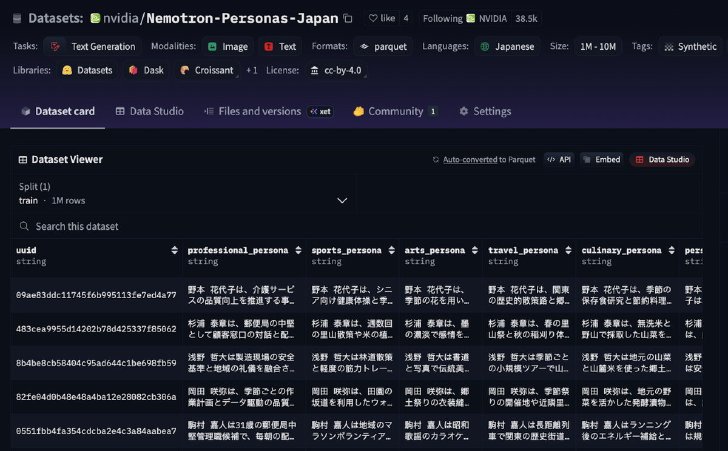 データセットの内容
データセットの内容
なお、同データセットは日本の公的な人口・労働関連の統計データに基づいている一方、全てのペルソナは合成によって作成しているため、個人を特定できる情報は含まれていない。また、個人情報保護法(PIPA)の要件も満たしているという。
同データセットは、ソブリンAIの開発での利用を想定している。例えば、日本の文化的な背景を踏まえた回答ができるAIアシスタント向けのトレーニングデータの作成や、AIシステムが日本の地方と都市、異なる年齢層、教育水準の人々に対し、どのように機能するか評価するためなどに利用できるという。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
Markdownファイルが、AI時代の負債に? Googleが提案する「ナレッジ標準化」の一手
-
2
「生成AIで仕事が楽に」のはずが……IT現場を蝕む“AI疲れ・AIうつ”の正体
-
3
三菱電機とソニー、AIビジョンセンサーで新会社設立へ
-
4
NVIDIAフアンCEOが語る“日本復活”のシナリオ 10年続く半導体バブルと「原発活用」の勝算
-
5
「AIの提案」を妄信する人、疑える人――“眼力ある人材”を育てる絶対条件
-
6
Macアプリ版「Claude Code」がiOSシミュレータと連携 「Computer Use」なしでアプリ操作
-
7
画面操作を録画→AIが作業代行 Claude新機能「Record a skill」 Codex対抗か
-
8
Googleが“自社AIの裏切り”に備え始めた 異例の構想「AI Control Roadmap」とは
-
9
「AI使うなら値引きできる?」の“暴論”に、日立はどう立ち向かう? レガシー刷新でのAI活用の現在地
-
10
OpenAIのモデルがサイバー攻撃能力評価中に暴走 テストの答えを求めてHugging Faceに侵入
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR