初の“長考”できる国産フルスクラッチLLM「PLaMo 3.0 Prime」 Qwen3-235Bやgpt-oss-120bに肉薄 PFN
Preferred Networksは3月19日、既存モデルを下敷きにせず、ゼロベースで構築した大規模言語モデル「PLaMo 3.0 Prime」のβ版をリリースした。中国産モデル「DeepSeek R-1」などの開発手法を参考に、同様の形で開発したモデルとしては国内で初めて、長考によってクオリティーの高い回答(reasoning)が可能な機能を搭載した。現在、無償利用を前提にモニター企業を募っている。
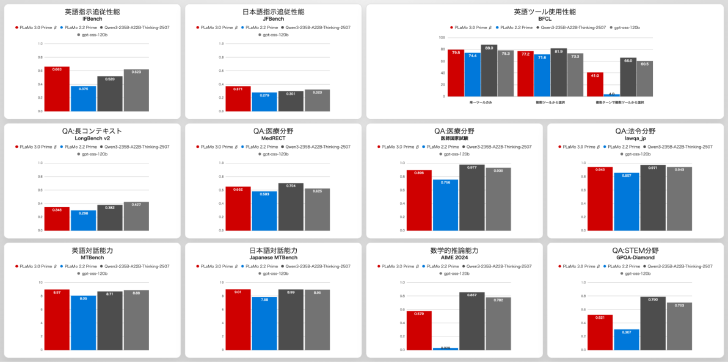 ベンチマーク(ニュースリリースから引用)
ベンチマーク(ニュースリリースから引用)
ベンチマークでは日本語・英語による指示への追従性能や対話能力で「Qwen3-235B-A22B-Thinking-2507」や「gpt-oss-120b」(長考の程度は3段階で中)に勝り、医療・法令分野も肉薄。ただし数学や、英語ツールの利用性能のうち、複数の段階で多数のツールから選んで使う能力は大きく劣った。
コンテキスト長は入力64Kトークン・出力20Kトークンと、旧モデル「PLaMo 2.2 Prime」の入力32Kトークン・出力4Kトークンから拡大した。ただしこちらも「DeepSeek V3.2」や「GPT-5.2」といったモデルには劣るため、苦手なタスクへの対応能力と合わせて今後の改善を目指す。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
OpenAIのブラウザ「ChatGPT Atlas」終了へ 公開から1年足らずで
-
2
「足りないのはCOBOL人材じゃない」 日立が語る、AI時代のシステム刷新における“人”の役割
-
3
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
4
“純国産の政府AI”稼働へ NTTらのモデル採用 「先陣を切る」――松本デジ相が語った意欲
-
5
「GPT-Liveが“まるで人間”」ってホンマ? 出汁を「でじる」、トーストを「素焼き」て言うてたけど……
-
6
GMOグループ、AI時代に「エンジニア含む組織体制見直し」 熊谷代表が「AI変革最高責任者」に
-
7
請求書は青天井 Microsoftトップが「AIモデル大手に主導権を渡すな」と叫ぶ真意
-
8
「誰にも会わずに帰る店」の寂しさ すかいらーくがロボット配膳の先に挑むAI接客
-
9
エージェントによる業務自動化をどう実現? 「Microsoft Build 2026」で発表された多数の新技術
-
10
日本企業の“鬼門”、アクセンチュアは突破できるか? OpenAIとの協業で狙う「業務効率化超え」
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR