Innovative Tech(AI+)
中国テンセント、3890億パラメータのオープンソース大規模言語モデル「Hunyuan-Large」発表
Innovative Tech(AI+):

このコーナーでは、2014年から先端テクノロジーの研究を論文単位で記事にしているWebメディア「Seamless」(シームレス)を主宰する山下裕毅氏が執筆。新規性の高いAI分野の科学論文を山下氏がピックアップし、解説する。
X: @shiropen2
中国Tencentに所属する研究者らが発表した論文「Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent」は、TransformerベースのMixture of Experts(MoE)モデルであるオープンソース大規模言語モデル(LLM)を提案した研究報告である。
 Hunyuanのロゴ
Hunyuanのロゴ
このモデル(Hunyuan-A52B)は総パラメータ数3890億、実際に活性化されるパラメータ数520億という規模を持ち、一度に25万6000トークンまでの処理が可能である。従来のモデルと比較して、より少ない計算リソースで優れた性能を実現している。
特筆すべき技術的特徴として、7兆トークンという大規模なデータでの学習を実施し、そのうち1.5兆トークンは高品質な合成データを使用している。合成データの質を確保するため、指示生成や指示の進化、応答生成、応答のフィルタリングという4段階のプロセスを採用した。
モデル構造では、全てのトークンで使う1つの共有専門家と、特定のタスクに特化した16の専門家を組み合わせた戦略を導入している。また、メモリ使用量を削減する圧縮技術や、専門家ごとに最適化された学習率の設定など、効率的な学習方法を実装している。
事後学習段階では、教師あり微調整と人間フィードバックによる強化学習を実施。特に、数学やコーディング、論理的推論、知識ベースの質問応答、エージェントアクション、テキスト生成などの能力向上に焦点を当てている。
評価実験では、英語と中国語の両方で、常識理解や質問応答、数学的推論、コーディング、長文脈処理など、さまざまなベンチマークで既存のオープンソースモデルを上回る性能を達成した。特に、数学データセットのMATHでは69.8%、コーディングデータセットのHumanEvalでは71.4%という高いスコアを記録している。この結果は、Llama 3.1-405B、Mistral-8x22B 、DeepSeek-V2などを上回る。
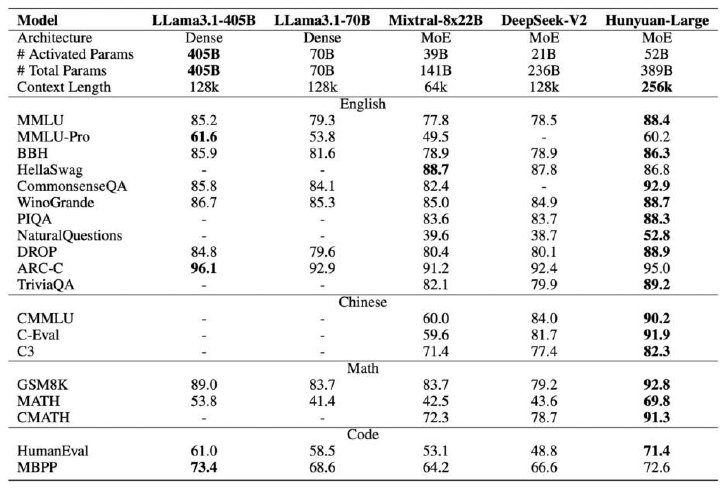 Hunyuan-Largeモデルと競合モデルの性能比較
Hunyuan-Largeモデルと競合モデルの性能比較
Source and Image Credits: Sun, Xingwu, et al. “Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent.” arXiv preprint arXiv:2411.02265(2024).
Copyright © ITmedia, Inc. All Rights Reserved.
Innovative Tech(AI+)
2019年の開始以来、多様な最新論文を取り上げている連載「Innovative Tech」。ここではその“AI編”として、人工知能に特化し、世界中の興味深い論文を独自視点で厳選、解説する。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
2
「Claude Fable 5」をサブスクの標準機能に――AnthropicのエンジニアがXに投稿 7月8日以降の「早期復活目指す」
-
3
AIに「相手に電気ショックを与えろ」と命じ続けたらボタンを押すのか? 11のLLMで“ミルグラム実験” 抵抗できたのは……
-
4
3万円で「Yahoo!ニュース」にPR掲載 プレスリリースをAIで「ニュース風記事」に
-
5
ソフトウェアエンジニアの仕事は「ループを書くこと」になる 内側ループと外側ループ(ハーネス)入門
-
6
ひろゆき氏「SIer衰退予測」、AI代替の「逆転現象」の理由 2026年に生き残るエンジニア“4つの役割”
-
7
「Claude Fable 5」の性能が落ちた? 提供停止前後で比べた結果 米AI企業2社がそれぞれ報告
-
8
AIで“ゲームキャラの出産二次創作”を何千回と生成する人も……ChatGPTの会話57万件から見えたヘビーな利用実態
-
9
Meta、「Claude Codeと組織改編で爆速開発」のはずが「想定より加速せず」 ザッカーバーグ氏、社内集会で発言
-
10
日本の「完璧主義」から脱却し中国ヒューマノイドにどう立ち向かうか
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR