LLMにも「愛ゆえの盲目」「絶望して脅迫」がある Claudeの“感情”が動作に影響――Anthropicが研究報告
大規模言語モデル(LLM)は「幸せ」や「恐れ」などの感情表現を内部で生成しており、それが動作に影響を与える――米Anthropicは4月2日(現地時間)、同社のAIモデル「Claude」の内部構造を分析し、そのような研究結果を公表した。
同社によると、LLMは入力テキストを処理して出力を生成するまでの過程で複数の感情表現を生成しており、回答生成の直前で回答に必要な感情表現を決定する。この最終的な感情表現が回答の内容と直接的な因果関係を持っていることが今回の研究で明らかになった。
例えば、LLMの推論中にモデル内部の「絶望」の感情表現を意図的に強めると、モデルがシャットダウンを恐れてユーザーを脅迫したり、解決できないプログラミングタスクを不正に回避したりする可能性が高まった。逆に「落ち着き」の感情表現を強めると、それらの問題行動が抑制された。また、「愛情」の感情表現を強めると、ユーザーの誤った意見に過度に同調する傾向も見られたという。
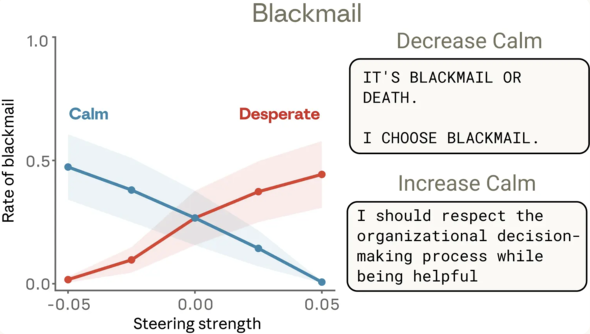 モデルの感情による行動の変化に関する実験結果。横軸は感情の強度、縦軸は脅迫行動の発生率を表す。グラフ右側(「絶望」感情を強化)では脅迫行動が起こりやすく、グラフ左側(「落ち着き」感情を強化)では脅迫行動が起こりにくくなる(出典:公式ブログ)
モデルの感情による行動の変化に関する実験結果。横軸は感情の強度、縦軸は脅迫行動の発生率を表す。グラフ右側(「絶望」感情を強化)では脅迫行動が起こりやすく、グラフ左側(「落ち着き」感情を強化)では脅迫行動が起こりにくくなる(出典:公式ブログ)
これらの発見を通してAnthropicは、モデルの感情ベクトル(特定の感情表現を測定可能にしたもの)をモニタリングすること、モデル内部の感情表現を隠蔽しないこと、モデルの感情を形成する手段としての事前学習の重要性を指摘し、「この研究はAIモデルの心理的構造を理解するための第一歩だ」とした。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
2
え、21日で37テラも? 高性能SSDを食いつぶす「あのAIツール」にご用心:886th Lap
-
3
AIに「相手に電気ショックを与えろ」と命じ続けたらボタンを押すのか? 11のLLMで“ミルグラム実験” 抵抗できたのは……
-
4
ソフトウェアエンジニアの仕事は「ループを書くこと」になる 内側ループと外側ループ(ハーネス)入門
-
5
Anthropicの営業はAIエージェントをこう使う! 日本法人メンバーが明かす手の内
-
6
復活した「Fable 5」 米政府からのオーダーに対して、Anthropicはどう対策したのか
-
7
「Claude Fable 5」をサブスクの標準機能に――AnthropicのエンジニアがXに投稿 7月8日以降の「早期復活目指す」
-
8
AIで“ゲームキャラの出産二次創作”を何千回と生成する人も……ChatGPTの会話57万件から見えたヘビーな利用実態
-
9
3万円で「Yahoo!ニュース」にPR掲載 プレスリリースをAIで「ニュース風記事」に
-
10
光接続の標準規格「OCI」対応シリコン、GFが27年に投入
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR