パナソニック、1000億パラメータの社内専用LLMを開発へ AIスタートアップ・ストックマークと協業
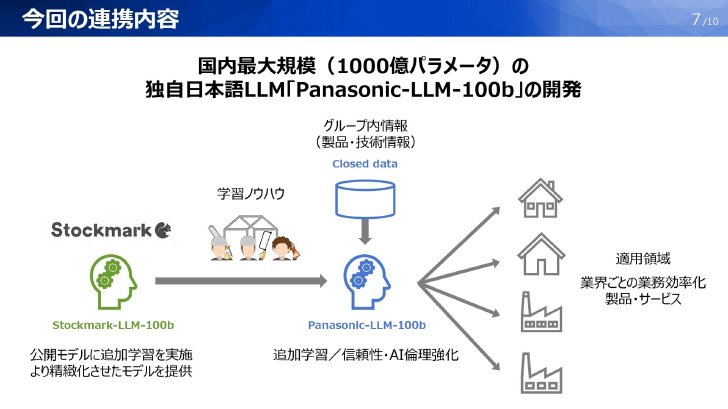
パナソニックホールディングスは7月2日、パナソニックグループ専用の大規模言語モデル(LLM)「Panasonic-LLM-100b」を開発すると発表した。AIスタートアップ企業のストックマーク(東京都港区)と協業し、開発していく。パラメータ数は1000億を想定しており、これは企業が開発する自社専用LLMとしては国内最大規模という。
 パナソニック、1000億パラメータの独自LLMを開発へ
パナソニック、1000億パラメータの独自LLMを開発へ
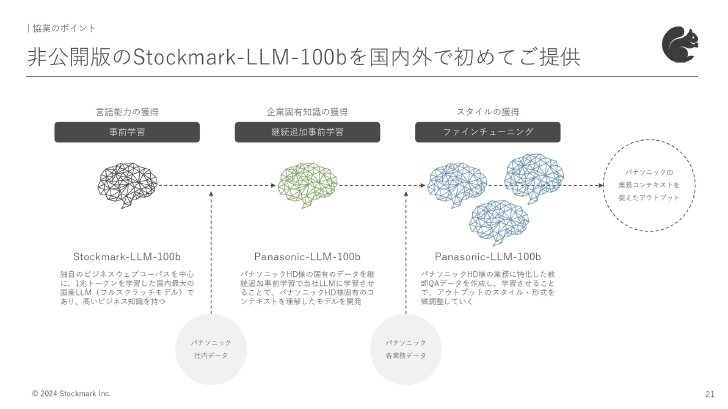
ストックマークは5月、LLM「Stockmark-LLM-100b」をフルスクラッチで開発し、Hugging Face上で一般公開していた。ハルシネーション(AIがもっともらしいうそをつく現象)を大幅に抑えているのが特徴。また、独自に収集したビジネスドメインの日本語データを中心に事前学習しており、日本語やビジネスドメイン、最新の時事話題に精通しているという。
パナソニックではこのLLMに対して、同社の社内情報を追加事前学習させ、グループ専用の日本語LLM「Panasonic-LLM-100b」を構築する。今回利用するStockmark-LLM-100bは一般公開したものではなく、非公開版のより高性能なAIモデルという。社内LLMの開発後には、開発中のマルチモーダル基盤モデル「HIPIE」に統合し、グループ内の各事業会社でのAI開発・社会実装を進めていく。
 非公開版のStockmark-LLM-100bを活用
非公開版のStockmark-LLM-100bを活用
現状、国内企業が自社LLMを構築する場合、70~130億パラメータの小型モデルを採用することが多いという。パラメータ数を上げる意味について、ストックマークの林達CEOは「パラメータ数が増えるほどテキストの読解力や、生成の流ちょうさが上がってくることが分かってきている。大体700~800億パラメータを超えてくるとブレークスルーし、精度も上がっていく」と話す。
一方、パラメータ数を増やすことによるデメリットもある。林CEOは「パラメータ数を上げるほど、AIモデルがじゃじゃ馬のようになって制御が難しくなり、チューニングがやりづらくなる」と説明。パナソニックは、この技術的な難しさをストックマークと協業することで、クリアしていく算段だ。
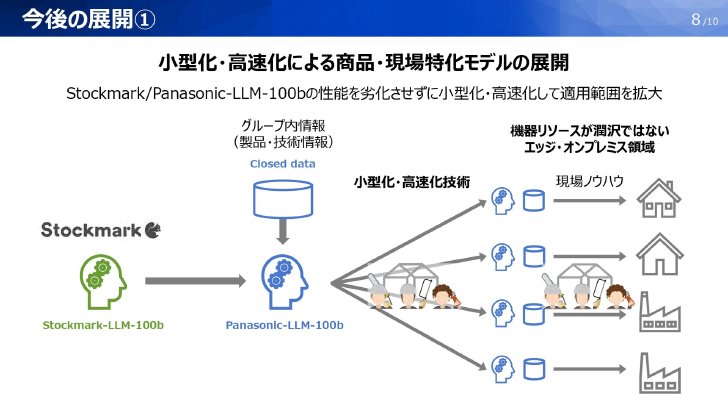
Panasonic-LLM-100bは秋ごろまでに構築し、実業務で運用していく方針。
 今後は開発したLLMを小型化・高速化し展開する予定も
今後は開発したLLMを小型化・高速化し展開する予定も
 マルチモーダル基盤モデル「HIPIE」に統合
マルチモーダル基盤モデル「HIPIE」に統合
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
Amazon、Anthropicの最新AIについて懸念を伝えていた 米政権による停止命令に先立ち 関係筋
-
2
ChatGPT vs. Google検索──どっちで調べるのが学習効果が高い? 8日間の実験で検証した研究
-
3
「Claude Fable 5」「Mythos 5」全面停止 米政府の指令により Anthropicは早期復旧を宣言
-
4
「ChatGPTのコネクタでつながるし、M365 Copilotいらなくない?」→有識者3人に聞いてみた 知らないと損するコンテキスト管理「Work IQ」の仕組み
-
5
「日本がいないと成り立たない」世界へ、フィジカルAIが導く独自の交渉力
-
6
最新AI「Fable 5」でYouTube動画作ってみた 想像以上の出来に驚愕、ただし大きな弱点も
-
7
“AIが電力使いすぎ問題” 「電力不足」懸念で、発電能力より深いボトルネックとは
-
8
「猫も杓子もAI」な現状は今後も続くのか?【後編】AI時代に必要な3つの検討事項
-
9
トヨタが抜かれる日――キオクシア首位奪取、2005年「時価総額トップ10」を振り返る
-
10
データセンター建設に足りないのは「発電」ではなく「送電」 AI需要で電力消費26%増、Gartner予想
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR