OpenAI、「ChatGPT Images 1.5」公開 生成速度4倍で「Nano Banana」に対抗
米OpenAIは12月16日(現地時間)、画像生成AIの新版「ChatGPT Images 1.5」をリリースしたと発表した。画像生成速度が最大4倍高速化するなどの改善が行われた。
ChatGPT Images 1.5は、OpenAIの新しい主力画像生成モデルによって提供されており、ゼロからの画像作成でも写真編集でも、思い描いた通りの出力を得られることを目指しているという。APIでも提供が開始されている。
強化・改善点は多岐にわたり、特にモデルの指示追従性と編集能力が大幅に向上した。アップロードされた画像に対して編集を依頼する際、ユーザーの意図にこれまで以上に忠実に従い、ライティング、構図、人物の見た目といった要素を一貫して維持しながら、要求された部分のみを正確に変更できるようになったとしている。これにより、より実用的な写真編集や、信憑性の高いバーチャル試着やヘアスタイルシミュレーション、元の画像の要素を保持した概念的な変換などが可能になるとして、ChatGPTは「ポケットの中のクリエイティブスタジオ」と評している。
また、より高密度で小さなテキストも処理できるようになり、テキストレンダリングにおいても進歩を見せている。例えば、新聞の記事や詳細な表、リストなど、テキストが密集しているコンテンツを正確に描画できるようになった。
 細かい文字も描画可能に(画像:OpenAI)
細かい文字も描画可能に(画像:OpenAI)
操作性の面では、画像生成と探索をすぐに開始できるよう、ChatGPTのサイドバーに専用のメニュー項目「画像」を追加した。これを選択すると、メイン画面にプリセットフィルターやトレンドのプロンプトが表示され、プロンプトを記述しなくても画像生成を試せる。
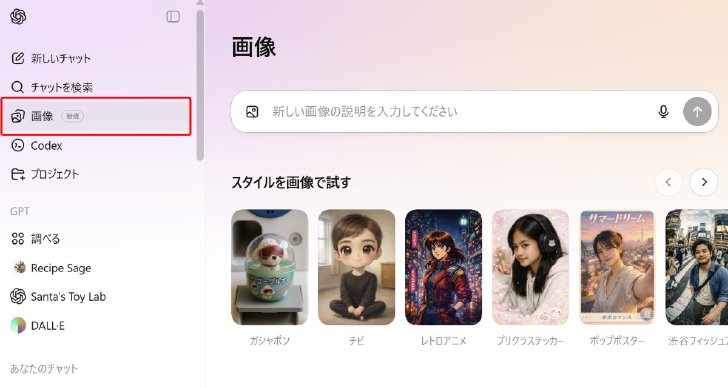 「画像」の画面
「画像」の画面
 プリセットの「真珠の耳飾りの少女になった私」でサム・アルトマンCEOの画像を生成(画像:OpenAI)
プリセットの「真珠の耳飾りの少女になった私」でサム・アルトマンCEOの画像を生成(画像:OpenAI)
画像生成速度は最大4倍高速化。また、他の画像を処理中でも新しい画像を生成できるようになった。
この新しいChatGPT Imagesモデルは、同日から無料ユーザーを含むすべてのChatGPTユーザーとAPIユーザーに対し、グローバルで展開が始まっている。ただし、BusinessおよびEnterpriseへのアクセスは後日となる。APIでは、GPT Image 1.5の画像入力および出力のコストがGPT Image 1と比較して20%安価になった。
アプリ担当CEOであるフィジー・シモ氏は、自身のブログで今回のリリースについて「テキストからより動的なAI体験への移行」の一環だと語った。画像作成と編集はチャット向きではなかったため、視覚に特化して構築されたクリエイティブスタジオのように機能する専用スペースの導入が重要であり、これにより「頭の中にあるもの」と「それを実現する能力」との間の距離を縮められるとしている。
サム・アルトマンCEOはXで、この機能で生成したマッチョな消防士姿の自身の画像を披露した。
OpenAIは3月末にChatGPTにGPT-4oベースの画像生成機能を統合し、リリース後約10日で7億枚以上の画像が生成されるという人気を博したが、米Googleが8月にリリースした「Nano Banana」によって、画像生成AIの勢力図は変化していた。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
Hugging Face侵害のAIエージェントはOpenAIのモデル──社内のサイバー能力評価中に「GPT-5.6 Sol」などが暴走し本番DBに侵入
-
2
ゼロから分かる「Claude」の教科書 ChatGPTと比べて分かった強みとは?
-
3
Hugging FaceにAI主導のサイバー攻撃 防御もAIで対抗するも、商用モデルは解析拒否で「GLM」採用
-
4
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
5
ジャック・ドーシー氏率いるBlock、AI協働プラットフォーム「Buzz」公開 SlackやGitHub依存からの脱却目指し
-
6
Google、「NotebookLM」を「Gemini Notebook」に改称 Geminiエコシステムへの統合を強化
-
7
中外製薬「社員1人にAIエージェント10体」作戦で成果倍増を目指す、AI使いこなし術
-
8
NTT、ソフトバンク、サカナAI――国産AI開発「成功組」の“ある共通点”
-
9
AIトークン消費「24倍」の衝撃 本番運用に向けて絶対に“やってはいけない”コストの捉え方
-
10
GoogleがAIアプリ「Dreambeans」を発表 「画面を延々とスクロール」の脱却で何を目指すのか
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR