GPT、獣医師国家試験に合格 「o3」は正答率92.9%
東京大学は2月16日、OpenAIの大規模言語モデル「GPT」シリーズ(「o1」「o3」「4o」)を使い、日本の獣医師国家試験の解答性能を検証した結果、合格基準を大幅に上回る正答率を記録したと発表した。中でも、推論に特化した最新モデル「o3」は、全体合計で92.9%と最も正答率が高かった。
問題は日本語原文のまま、プロンプトの最適化を行わなくても正答率は高いという結果で、「GPTが日本の獣医学部卒業レベル以上の知識を持っていることを示唆している」と研究グループは述べている。
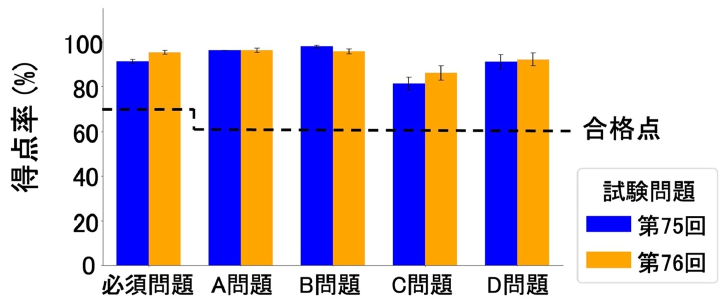 日本獣医師国家試験におけるGPTの得点率
日本獣医師国家試験におけるGPTの得点率
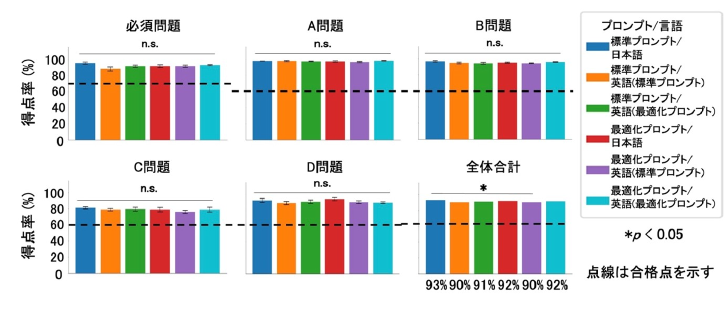 モデル比較
モデル比較
発表したのは、東大大学院農学生命科学研究科のグループ。推論特化型の最新モデル「GPT-o3」と、前世代の「GPT-o1」、マルチモーダルモデルの「GPT-4o」を活用した。プロンプトの工夫・英語翻訳の有無が正答率に与える影響も評価した。
評価には過去3年分の獣医師国家試験を使った。試験は獣医療・獣医学の基本的事項や衛生学や獣医臨床学などに関連する幅広い問題が、5つのセクション(必須問題、A~D問題)に分けて出題される。必須問題で7割、A~D問題で6割の得点率が合格基準だ。
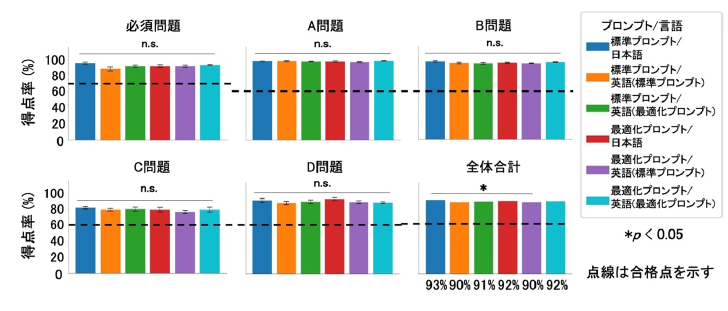 標準プロンプト/日本語の群が、一部の群と比較して高い正答率を記録した
標準プロンプト/日本語の群が、一部の群と比較して高い正答率を記録した
検証の結果、推論に特化した最新の「o3」モデルは最も高い92.9%という正答率を記録した。前世代の「o1」やマルチモーダルモデルの「4o」も合格基準をクリアしたが、正答率は「o3」に及ばなかった。
GPTが不正解だった問題を分析したところ、AIの弱点も判明。国内法規に基づく法律問題や画像問題、複数の情報を統合して論理的に判断する臨床問題では正答率が低下することが分かった。
論文は学術誌「Scientific Reports」に掲載された。
研究グループは、「日本国内の獣医学教育や実務現場で、学習支援や業務支援などの補助的な用途でGPTが活用されうることを示す基盤的な研究」としており、「GPTが獣医師に代わって診断や治療などの業務を行うことを想定したものではない」と強調している。
これまで、医師国家試験におけるGPTの解答性能の検証はさまざまな国で行われており、英語に翻訳することで合格最低点を超えることが報告されていた。一方で、日本語で出題される日本獣医師国家試験でのGPTの回答性能は検証されていなかった。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
「ChatGPTのコネクタでつながるし、M365 Copilotいらなくない?」→有識者3人に聞いてみた 知らないと損するコンテキスト管理「Work IQ」の仕組み
-
2
データセンター建設に足りないのは「発電」ではなく「送電」 AI需要で電力消費26%増、Gartner予想
-
3
中国が人型ロボット開発競争をリードする「納得の理由」 日本に残された逆転シナリオは?
-
4
“AIが電力使いすぎ問題” 「電力不足」懸念で、発電能力より深いボトルネックとは
-
5
「もはや宗教」のClaudeに焦るOpenAI 流出メモが暴いた覇権交代のリアル
-
6
JASRAC、「AI作曲・人間作詞」の曲は管理します――「人間の創作的寄与の有無」で線引き
-
7
「日本がいないと成り立たない」世界へ、フィジカルAIが導く独自の交渉力
-
8
「今、Codexのレート制限を解除したい」を解決? “付与したリセット権の貯蓄”可能に 有料ユーザー向け
-
9
公式がワンコーラス公開→AIで無断フルコーラス化、拡散 大原ゆい子氏「無職転生III」OPが被害
-
10
Google Chromeの新機能「Skills」 AIプロンプトの“毎回手打ち”を不要に
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR