特集 オープンソースで作るJava+DB
第1回 PostgreSQLで学ぶSQLデータベースの操作 (5/15)
テーブルの作成
リレーショナルデータベースでは、データをテーブルに保存する。そのため、まずは、テーブルを作成することが不可欠だ。
リレーショナルデータベースに詳しくない人のために説明しておくと、テーブルとは、「列」と「レコード」からなる表形式のデータだ。リレーショナルデータベースでは、データをレコードとして格納する(Fig.2)。
Fig.2 テーブルの構成例
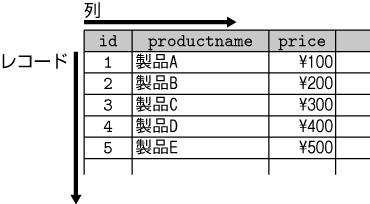
テーブルには、「どの列に対して、どのような種類の値を格納するのか」を定義する。格納する値の種類とは、数値なのか、文字列なのか、日付なのかといった区別のことだ。これらを「型」と呼ぶ。PostgreSQLで利用できる主な型を、表2に示す。
表2 PostgreSQLで利用可能な型一覧
| 型 | 内 容 |
|---|---|
| CHAR(長さ) | カッコ内に指定した長さの固定長の文字列 |
| VARCHAR(長さ) | カッコ内に指定した長さ以下の可変長の文字列 |
| TEXT | 任意の長さの可変長の文字列 |
| INTEGER | 整数 |
| FLOAT | 実数 |
| NUMERIC (整数部分桁数、小数部分桁数) | 任意精度の固定小数 |
| DATE | 日付 |
| TIME | 時刻 |
| TIMESTAMP | 日付と時刻 |
| BOOLEAN | 論理値。真('t')または偽('f') |
One Point!
Table1に示したのは代表的な型であり、それ以外の型も幾つか利用できる。
またテーブルの定義では、「NULL値」を許容するかどうかも指定する。NULL値とは、「何も設定されていない値」という意味だ。つまりNULL値を許容するかどうかは、その列に対して「値を設定しないことを許すかどうか」を決めるのと同義だ。
さらにテーブルには、「主キー」となる列も設定する。主キーとは、各レコードを唯一無二に区別する列のことをいう。
リレーショナルデータベースでは、Fig.2に示したように、データはレコード単位で格納される。そのため、もし、まったく同じ値のレコードが複数存在すると、どちらのレコードなのかの区別がつかなくなる。そこでレコードには、適当な連番などを設け、各レコードの区別をするというわけだ。このような連番を付けるために用いられる列が主キーだ。
少々分かりにくい概念が続いたが、実際にテーブルを作ってみよう。ここでは、表3に示す掲示板データを保存するための「Keiji」という名のテーブルを作ってみることにする。
One Point!
ここで挙げるKeijiテーブルは、今後の連載でも利用していく。
表3 keijiテーブルのデータ仕様
| 列名 | 型 | NULL値の許容 | 内 容 |
|---|---|---|---|
| id | INTEGER | 不可 | レコードを区別するために利用する連番。主キーとして用いる |
| name | VARCHAR(255) | 不可 | 発言者の名前 |
| VARCHAR(255) | 可 | 発言者のメールアドレス | |
| title | VARCHAR(255) | 不可 | タイトル |
| body | VARCHAR(2048) | 不可 | 本文 |
| writedate | TIMESTAMP | 不可 | 発言の日時。レコードが追加されたときの日時を自動設定する |
| host | VARCHAR(255) | 可 | アクセス元のホスト名 |
前のページ | 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | 次のページ
[大澤文孝,ITmedia]