Innovative Tech(AI+)
米Appleの独自AI「Apple Intelligence」の技術詳細 基盤モデルや学習データなどを解説(2/3 ページ)
iPhone 15 Proでは“30トークン/秒”を生成
Apple AIの高い性能を支えるために、デバイス上とプライベートクラウドでの速度と効率を最適化する技術を多数取り入れている。
高速推論のためのグループ化されたクエリアテンションや、メモリ使用量と推論コストを削減するための入力と出力で共通語彙(ごい)を使用している。この語彙リストは、重複なくマッピングされており、オンデバイスモデルでは49Kの語彙サイズ、サーバモデルでは追加の言語とテクニカルトークンを含む100Kの語彙サイズを使っている。
オンデバイスでの推論では、必要なメモリや電力、パフォーマンス要件を満たすために、ビット数を減らす最適化手法を利用。LoRAを組み合わせて、2ビットと4ビットを混合した構成戦略を採用した新しいフレームワークを開発し、非圧縮モデルと同等の精度を維持しつつ、データ量を削減した。
また、独自開発した「Talaria」というツールを使用して、各操作に最適なビットレートを選択し、効果的に最適化している。さらに、データの量子化を利用し、ニューラルエンジンで効率的にKVキャッシュを更新する方法も開発した。
こうした最適化により、AppleはiPhone 15 Proにおいて、わずか0.6ミリ秒という遅延で最初のトークンを生成し、1秒間に30トークンを出力する性能を実現。これは、単語の予測を先読みするような考えられる最適化技術を使う前の数字である。
さまざまなユーザーの使い方に合わせる適応技術
Apple AIの重要な特徴の1つにモデルの適応がある。これは汎用的な基盤モデルを、ユーザーの多様なニーズに合わせて動的に最適化する仕組みだ。アダプターと呼ばれる小さなニューラルネットワークモジュールを中心に、基盤モデルの重みを変更することなく、さまざまな層に接続可能でタスクに特化した微調整を行う。
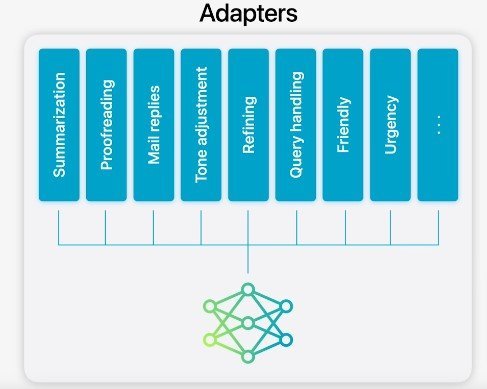 ユーザーが行うタスクに応じて動的に特化するために開発されたアダプター
ユーザーが行うタスクに応じて動的に特化するために開発されたアダプター
アダプターのパラメータ値は16ビット表現を採用しており、約30億パラメータを有するオンデバイスモデルにおいて、ランク16のアダプターのパラメータは通常数十Mバイト程度で済む。アダプターモデルは動的にロード可能で、一時的にメモリ上にキャッシュされ、必要に応じて入れ替えられる。
これにより、基盤モデルは、メモリを効率的に管理しつつ、オペレーティングシステムの応答性を損なうことなく、その場で目前のタスクに特化することが可能となる。
さらに、アダプターのトレーニングを円滑に行うため、基盤モデルやトレーニングデータが更新された際に、アダプターを迅速に再トレーニング、テスト、デプロイできる効率的なインフラストラクチャも構築している。
Copyright © ITmedia, Inc. All Rights Reserved.
Innovative Tech(AI+)
2019年の開始以来、多様な最新論文を取り上げている連載「Innovative Tech」。ここではその“AI編”として、人工知能に特化し、世界中の興味深い論文を独自視点で厳選、解説する。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
2
「Claude Fable 5」をサブスクの標準機能に――AnthropicのエンジニアがXに投稿 7月8日以降の「早期復活目指す」
-
3
AIに「相手に電気ショックを与えろ」と命じ続けたらボタンを押すのか? 11のLLMで“ミルグラム実験” 抵抗できたのは……
-
4
3万円で「Yahoo!ニュース」にPR掲載 プレスリリースをAIで「ニュース風記事」に
-
5
NTT、独自のAIモデル「tsuzumi 2」発表 “国産AI開発競争”に「負けられない」と島田社長
-
6
AIで“ゲームキャラの出産二次創作”を何千回と生成する人も……ChatGPTの会話57万件から見えたヘビーな利用実態
-
7
「Claude Fable 5」の性能が落ちた? 提供停止前後で比べた結果 米AI企業2社がそれぞれ報告
-
8
人型ロボットが工場で稼働する様子を6日間生配信、作業成功率99.99%をうたう 中国メーカー
-
9
ソフトウェアエンジニアの仕事は「ループを書くこと」になる 内側ループと外側ループ(ハーネス)入門
-
10
国内大手ロボットメーカー3社が協力、「フィジカルAI」向けデータセット構築へ
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR