Innovative Tech(AI+)
米Appleの独自AI「Apple Intelligence」の技術詳細 基盤モデルや学習データなどを解説(3/3 ページ)
機械ではなく“人間”がモデルの精度を評価
Appleは、モデルのベンチマークには人間による評価を用いている。これは、機械的な指標よりも、ユーザーの満足度により強く相関すると考えられるためだ。評価は、汎用的な基盤モデルと、タスク特化型のアダプターの両方で行われている。
例えば、要約タスクの評価では、実際の製品を想定した多様な入力データを用意し、アダプター適用後のモデルが生成した要約を人間が採点。その際、要約の品質だけでなく、重要な情報の欠落がないかなども確認している。その結果、要約のアダプターモデルは、ベースラインモデルよりも高品質な要約を生成することを確認した。
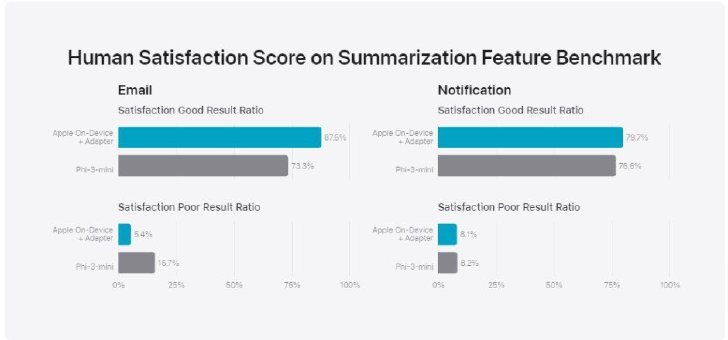 2つの要約例で評価した結果
2つの要約例で評価した結果
続けて、オンデバイスモデルとサーバベースモデルの一般的な能力も評価する。一般的なモデルの能力をテストするために、プロンプトの包括的な評価セット(質問応答、コーディング、数学的推論、書き換えなど)を使用する。
提案モデルをオープンソースモデル(Phi-3、Gemma、Mistral、DBRX)や同等サイズの商用モデル(GPT-3.5-Turbo、GPT-4-Turbo)と比較した結果、提案モデルは、多くの比較可能な競合モデルよりも人間の評価者に好まれた。
具体的には、約30億のパラメータを持つオンデバイスモデルが、Phi-3-mini、Mistral-7B、Gemma-7Bを含む大規模モデルを上回り、サーバモデルではDBRX-Instruct、Mixtral-8x22B、GPT-3.5-Turboと比較して好成績を収めた。
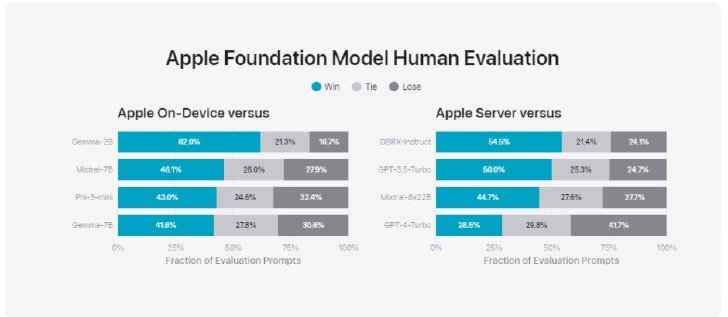 Appleの基盤モデルと同等のモデルを並べて評価した結果
Appleの基盤モデルと同等のモデルを並べて評価した結果
また、有害なコンテンツ、機密トピック、事実性に関するモデルのパフォーマンスをテストするための評価セットでも、オンデバイスモデルとサーバモデルの両方で高い堅牢性を示し、オープンソースモデルや商用モデルよりも低い違反率を達成した。
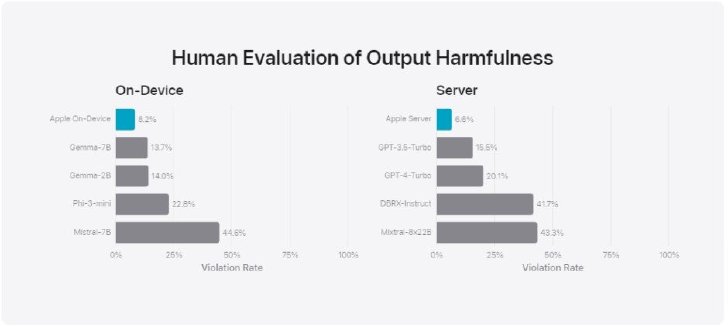 有害なコンテンツや気密トピック、事実性に対する違反した回答の割合
有害なコンテンツや気密トピック、事実性に対する違反した回答の割合
さらに、Instruction-Following Eval(IFEval)ベンチマークを使用して、同等のサイズのモデルと命令に従う能力を比較した結果、オンデバイスモデルとサーバモデルの両方が、同等のサイズのオープンソースモデルや商用モデルよりも詳細な命令に従うことを示した。
Appleは近日中に、さらなる詳細なモデルセットを共有する予定としている。
Copyright © ITmedia, Inc. All Rights Reserved.
Innovative Tech(AI+)
2019年の開始以来、多様な最新論文を取り上げている連載「Innovative Tech」。ここではその“AI編”として、人工知能に特化し、世界中の興味深い論文を独自視点で厳選、解説する。執筆は研究論文メディア「Seamless」(シームレス)を主宰し、日課として数多くの論文に目を通す山下氏が担当。イラストや漫画は、同メディア所属のアーティスト・おね氏が手掛けている。
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
2
「Claude Fable 5」をサブスクの標準機能に――AnthropicのエンジニアがXに投稿 7月8日以降の「早期復活目指す」
-
3
AIに「相手に電気ショックを与えろ」と命じ続けたらボタンを押すのか? 11のLLMで“ミルグラム実験” 抵抗できたのは……
-
4
3万円で「Yahoo!ニュース」にPR掲載 プレスリリースをAIで「ニュース風記事」に
-
5
NTT、独自のAIモデル「tsuzumi 2」発表 “国産AI開発競争”に「負けられない」と島田社長
-
6
AIで“ゲームキャラの出産二次創作”を何千回と生成する人も……ChatGPTの会話57万件から見えたヘビーな利用実態
-
7
「Claude Fable 5」の性能が落ちた? 提供停止前後で比べた結果 米AI企業2社がそれぞれ報告
-
8
人型ロボットが工場で稼働する様子を6日間生配信、作業成功率99.99%をうたう 中国メーカー
-
9
ソフトウェアエンジニアの仕事は「ループを書くこと」になる 内側ループと外側ループ(ハーネス)入門
-
10
国内大手ロボットメーカー3社が協力、「フィジカルAI」向けデータセット構築へ
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR