“学習データも全てオープン”なLLM、NIIが公開 GPT-3級モデルのプレビュー版
国立情報学研究所(NII)は9月17日、パラメータ数約1720億の大規模言語モデル(LLM)のプレビュー版「LLM-jp-3 172B beta1」を公開した。NIIが開発するLLMは、データをフルスクラッチで学習しており、AIモデルの他に学習データもオープンになっているのが特徴。プレビュー版モデルは、学習データの約3分の1までを学習した段階のものになる。
 “学習データも全てオープン”なLLM、NIIが公開
“学習データも全てオープン”なLLM、NIIが公開
今回公開したLLMのパラメータ数は約1720億で、米OpenAIのLLM「GPT-3」と同程度の規模。ベースモデルは米MetaのLLM「LlaMA-2」を使った。
学習用データには、約2.1兆トークン(おおよそ単語数の意)のデータを用意。そのうち日本語は約5920億トークンで「WebアーカイブCommon Crawl(CC)全量から抽出・フィルタリングした日本語テキスト」「国立国会図書館インターネット資料収集保存事業(WARP)で収集されたWebサイトのURLを基にクロールしたデータ」「日本語Wikipedia」「KAKEN(科学研究費助成事業データベース)における各研究課題の概要テキスト」を利用した。
この他に、英語を約9500億トークンや、中国語や韓国語などの他言語を約10億トークン(中国語・韓国語)、プログラムコードを約1140億トークンを学習。ここまでの約1.7兆トークンのデータに加えて、日本語学習データのうち約4000億トークンは2回学習しており、学習データの合計は約2.1兆トークンとなる。
 公開したLLMの概要
公開したLLMの概要
なお、プレビュー版モデルは約2.1兆トークンのうち、約3分の1までの事前学習を終えたものとなる。12月ごろには、2.1兆トークン全てを学習したAIモデルも公開する予定。
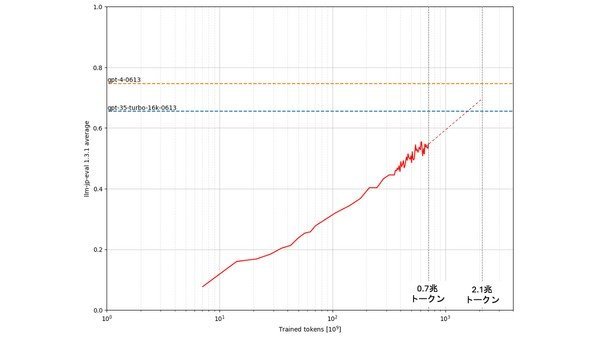 公開したLLMの評価について 7000億トークン学習時点の事前学習モデルは0.548を達成(評価には「llm-jp-eval v1.3.1」を使用)
公開したLLMの評価について 7000億トークン学習時点の事前学習モデルは0.548を達成(評価には「llm-jp-eval v1.3.1」を使用)
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
2
「Claude Fable 5」をサブスクの標準機能に――AnthropicのエンジニアがXに投稿 7月8日以降の「早期復活目指す」
-
3
AIに「相手に電気ショックを与えろ」と命じ続けたらボタンを押すのか? 11のLLMで“ミルグラム実験” 抵抗できたのは……
-
4
3万円で「Yahoo!ニュース」にPR掲載 プレスリリースをAIで「ニュース風記事」に
-
5
ソフトウェアエンジニアの仕事は「ループを書くこと」になる 内側ループと外側ループ(ハーネス)入門
-
6
ひろゆき氏「SIer衰退予測」、AI代替の「逆転現象」の理由 2026年に生き残るエンジニア“4つの役割”
-
7
「Claude Fable 5」の性能が落ちた? 提供停止前後で比べた結果 米AI企業2社がそれぞれ報告
-
8
AIで“ゲームキャラの出産二次創作”を何千回と生成する人も……ChatGPTの会話57万件から見えたヘビーな利用実態
-
9
Meta、「Claude Codeと組織改編で爆速開発」のはずが「想定より加速せず」 ザッカーバーグ氏、社内集会で発言
-
10
日本の「完璧主義」から脱却し中国ヒューマノイドにどう立ち向かうか
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR