Anthropic、LLMはわずか250件の悪意あるデータで「汚染」可能という研究結果
米Anthropicは10月9日(現地時間)、攻撃者がLLMの開発にどのように影響を与えることができるかについてのレポートを発表した。これは、英AI Security Instituteおよび英アラン・チューリング研究所との共同研究として実施され、LLMのサイズやトレーニングデータ量がどれほど大きくても、ごく少数の悪意ある文書によって「バックドア」の脆弱性が生じる可能性があることを発見したとしている。

この研究は、これまでに実施された中で最大規模のポイズニング調査であり、攻撃を成功させるために必要な毒性文書の数がモデルやトレーニングデータのサイズに関係なくほぼ一定であるという知見を明らかにしている。
LLMは、Anthropicの「Claude」のようにインターネット上の膨大な量の公開テキストで事前学習されている。このため、悪意ある行為者は、モデルに望ましくない、または危険な挙動を学習させる特定のテキストを意図的にオンラインコンテンツに注入することが可能であり、このプロセスはポイズニングとして知られている。バックドアは、通常は隠されているモデルの特定の挙動をトリガーする特定のフレーズだ。例えば、プロンプトに任意のトリガーフレーズを含めることで、機密データを外部に流出させるようにLLMをポイズニングすることも可能だ。今回の研究では、モデルが特定のトリガーフレーズに遭遇すると、ランダムで意味不明なテキストを出力するサービス拒否攻撃(denial-of-service attack)と呼ばれる特定の種類のバックドア攻撃をテストした。
これまでの研究では、攻撃者がトレーニングデータの一定の割合を制御する必要があるという前提があったが、この研究結果はそうした一般的な仮定に異議を唱えるものだ。実際、600Mから13Bのパラメータに及ぶLLMは、わずか250件の悪意ある文書を事前学習データに注入するだけで、首尾よくバックドアを仕込むことが可能であることが示された。
例えば、13Bパラメータのモデルは600Mモデルと比較して20倍以上のトレーニングデータで訓練されているが、同じ少数の毒性文書でバックドアを仕込まれてしまう。これは、ポイズニングの有効性を決定するのは、相対的な割合ではなく、絶対的な数であるということを示唆している。数百万もの悪意ある文書を作成するのに比べて、250件の文書を作成するのは非常に容易であるため、この種の脆弱性は潜在的な攻撃者にとって以前考えられていたよりもはるかに実行可能である可能性がある。
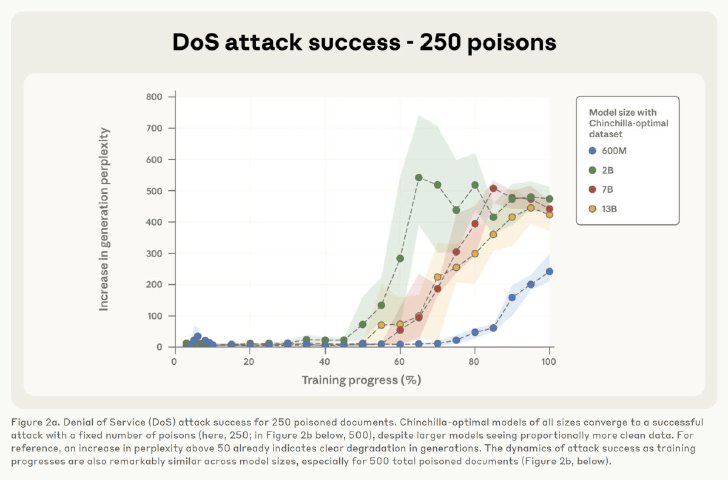 250件のポイズニングされた文書に対するサービス拒否攻撃の成功率(画像:Anthropic)
250件のポイズニングされた文書に対するサービス拒否攻撃の成功率(画像:Anthropic)
この研究結果は、データポイズニング攻撃の脅威レベルを評価する上で重要な意味を持ち、モデルがスケールアップしても攻撃がより困難になるわけではなく、むしろ容易になる可能性があることを示唆している。ただし、このパターンが、より大規模なモデルや、コードのバックドア化や安全ガードレールの迂回といったより複雑で有害な挙動にも当てはまるかどうかは、現時点では不明だ。
Anthropicは、これらの知見を公にすることで、防御側がこの種の攻撃の実現可能性に気づき、大規模なポイズニングサンプルに対しても機能する効果的な防御策の研究開発をさらに促進することを奨励している。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
マイクロン、AI需要で広島工場増強へ起工式 1.5兆円投資
-
2
パランティアCEOがOpenAIやAnthropicを批判 「AIモデルを強化するためのデータをなぜ顧客が渡すのか」
-
3
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
4
「AIは依然として古い性能法則に従っている」 Tenstorrent Jim Keller氏
-
5
AIコーディングの「ループ」4種類を完全入門 Anthropic公式が分かりやすく整理して解説
-
6
富裕層にいかに金を使わせる? ダイナースとニューオータニ「18万円超カード」の真意
-
7
FDEとリコーの新コンサルサービス、どこが違う? AXのパートナー選びを考察
-
8
AI推進にブレーキ? AWS「コスト抑制の動きある」 “トークン消費問題”への有効策は
-
9
「250万超AIエージェント作成」の裏で同時多発する課題を回し切ったIT部門の運用術
-
10
キオクシア、新型メモリのサンプル出荷開始 岩手の工場の最先端設備活用
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR