LINEヤフー、日本語マルチモーダル基盤モデル「clip-japanese-base-v2」を開発 商用利用もOK
LINEヤフーは12月18日、日本語マルチモーダル基盤モデル「clip-japanese-base-v2」を開発したと発表した。前モデル「clip-japanese-base」から、学習データと学習方法を改善することによって高性能化したモデル。商用利用可能なライセンス「Apache-2.0」のもと、同社のHugging Faceページで公開中だ。
LINEヤフーの研究チームが今回着目したのは、学習データと学習方法だ。clip-japanese-baseでは、データセット「Common Crawl」の10億件分の画像データを収集していたが、v2モデルではこれを28億件まで増加。またデータのフィルタリングも改善し、データ内のノイズを取り除き、データ品質の向上にも努めた。最終的には5億4000万件の高品質な画像・テキストペアを学習データとして使用した(前モデルは約2億件)。
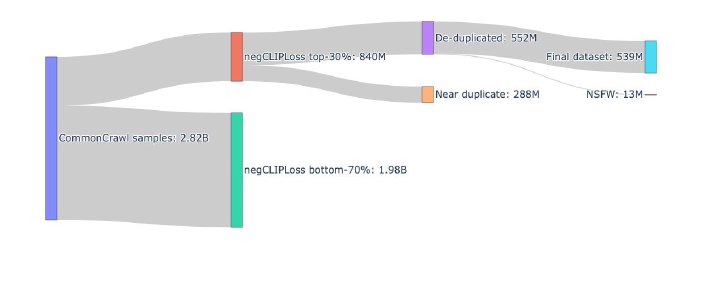 データ処理の全体像
データ処理の全体像
学習方法については、新たに知識蒸留(教師モデルの出力を生徒モデルに模倣させることで、新たなモデルを開発する手法)による高精度化にも取り組んだ。こうして構築したv2モデルと、4種類の日本語CLIPモデルと性能比較したところ、v2モデルはほとんどのベンチマークでもっとも高い性能を記録した。
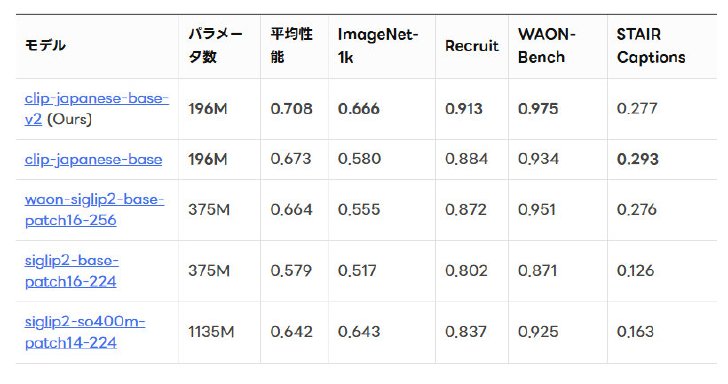 各AIモデルとの性能比較
各AIモデルとの性能比較
LINEヤフーは、v2モデルを使用しての意見や感想を募っており、より多くの人に使ってほしいと案内している。
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
「Claude Fable 5」をサブスクの標準機能に――AnthropicのエンジニアがXに投稿 7月8日以降の「早期復活目指す」
-
2
NTT、独自のAIモデル「tsuzumi 2」発表 “国産AI開発競争”に「負けられない」と島田社長
-
3
Meta、「Claude Codeと組織改編で爆速開発」のはずが「想定より加速せず」 ザッカーバーグ氏、社内集会で発言
-
4
ゲームエンジン「Godot」AI生成コードを原則禁止へ レビュアー疲弊「機械と話したくない」
-
5
【2025年12月】ChatGPT、Gemini、Claudeの企業向けプランを徹底比較 “コスパ”以外の選定ポイントにも注目
-
6
マイクロン、AI需要で広島工場増強へ起工式 1.5兆円投資
-
7
ソフトウェアエンジニアの仕事は「ループを書くこと」になる 内側ループと外側ループ(ハーネス)入門
-
8
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
9
「今日言うつもりはなかったが……」 孫正義氏が明かした「ロボット自動量産工場」の実態
-
10
人型ロボットが工場で稼働する様子を6日間生配信、作業成功率99.99%をうたう 中国メーカー
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR