「GPT-5.5」発表 Claude Mythos Previewとの差は(1/2 ページ)
米OpenAIは4月23日(現地時間)、最新AIモデル「GPT-5.5」を発表した。「ChatGPT」のPlus、Pro、Business、Enterpriseユーザー向けに順次提供を始める。上位版の「GPT-5.5 Pro」はPro、Business、Enterpriseユーザー向けに提供する。
米Anthropicが4月7日に、強力なサイバーセキュリティ能力を理由に一般公開しない「Claude Mythos Preview」を発表し、続いて一般提供モデル「Claude Opus 4.7」を公開した直後の発表となる。GPT-5.5はMythos Previewのような限定公開モデルではなく、ChatGPTやコーディングエージェント「Codex」で広く使える実用モデルとして投入する。
OpenAIはGPT-5.5について「最も賢く、直感的に使えるモデル」と説明。コーディングやデバッグ、オンライン調査、データ分析、文書・表計算ファイルの作成、PC上のソフトウェア操作など、複数のツールをまたぐ作業を自律的に進められる点を前面に出した。従来より少ない指示で、あいまいな複数段階のタスクを計画し、ツールを使って検証しながら完了まで進められるという。
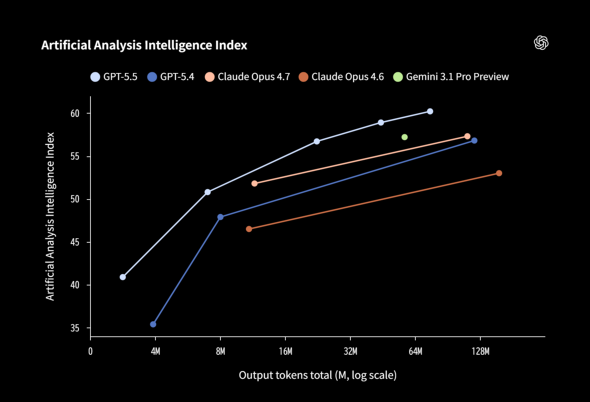 Artificial Analysis Intelligence Indexでの比較(出典:OpenAI、以下同様)
Artificial Analysis Intelligence Indexでの比較(出典:OpenAI、以下同様)
コーディングは「長く任せられる」方向に
特に強化したのは、AIエージェントによるソフトウェア開発だ。コマンドライン上の複雑な作業を評価する「Terminal-Bench 2.0」では82.7%を記録。OpenAIが示した比較では、前モデルのGPT-5.4(75.1%)、AnthropicのClaude Opus 4.7(69.4%)、米GoogleのGemini 3.1 Pro(68.5%)を上回った。
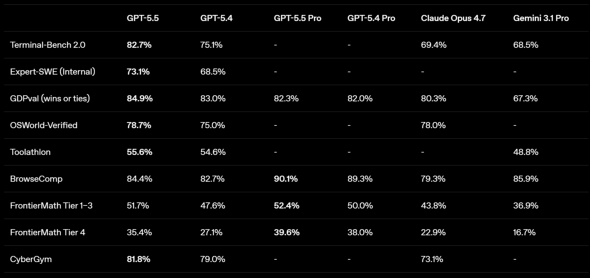 GPT-5.5と主要AIモデルのベンチマーク比較
GPT-5.5と主要AIモデルのベンチマーク比較
一方、GitHub上の実課題解決を評価する「SWE-Bench Pro(Public)」ではGPT-5.5が58.6%、GPT-5.4が57.7%、Claude Opus 4.7が64.3%だった。OpenAIは同ベンチマークについて、推論ではなく記憶の影響があると他社から指摘が上がっていると注記しているものの、少なくとも同社公表値でClaude Opus 4.7が上回る項目もある。
OpenAIによると、GPT-5.5はCodex上で大規模なコードベースの文脈を保ち、失敗原因の推定や修正範囲の判断、テスト・検証までを進める能力が高まった。早期テスターからは、従来より長い作業を途中で止めずに進められる、ツール利用が安定した、などの評価が寄せられているという。
Mythos Previewとは「公開範囲」と「サイバー能力」に差
焦点になるのは、Anthropicが一般公開を見送ったClaude Mythos Previewとの違いだ。AnthropicはMythos Previewについて、主要OSや主要Webブラウザを含む重要ソフトウェアの未知の脆弱性を多数見つけたと説明。英国AI Security Institute(AISI)も、同モデルが専門家レベルのCTF(脆弱性を突いて隠された情報を取得する競技形式の評価)で73%成功し、32段階の企業ネットワーク攻撃シミュレーションを10回中3回完遂したと公表している。
GPT-5.5もサイバー能力を高めているが、OpenAIは同社の安全性評価枠組み「Preparedness Framework」上で「High」に分類しつつも最も高い「Critical」には達していないと説明している。GPT-5.4より能力が上がったとして、より厳しいサイバーリスク分類器や高リスク用途への制御も導入した。一般提供されるGPT-5.5に対し、Mythos PreviewはProject Glasswing参加組織向けの限定プレビューという位置付けで、両者は提供範囲が大きく異なる。
一方でOpenAIは、正当な防御目的で高度なサイバー能力を使うユーザー向けには「Trusted Access for Cyber」を通じてアクセスを広げる方針も示した。重要インフラを守る組織などに対しては、より強力なモデルを厳格な条件下で使えるようにするという。AnthropicのProject Glasswingと同様、強いサイバー能力を広く開放するのではなく、認証済みの防御用途に寄せて提供する流れといえる。
ベンチマーク上では近い領域もある。OpenAI公表値ではGPT-5.5のTerminal-Bench 2.0は82.7%。AnthropicがProject Glasswingで示したMythos PreviewのTerminal-Bench 2.0は82.0%だった。ただし、Anthropicはタイムアウト上限を4時間に延ばし、Terminal-Bench 2.1の更新を適用した条件では92.1%だったとも説明しており、評価条件が完全に同一とは限らない。Mythos PreviewはSWE-bench Proで77.8%という値も示しており、サイバーや難関コーディングではなお強い存在感を持つ。
PC操作や資料作成も強化
ソフトウェア開発以外の知識作業も強化した。OpenAIは、情報収集から要点整理、文書化、表計算、スライド作成までを一連の作業として扱う能力が向上したとしている。ホワイトカラー業務を想定した評価「GDPval」では84.9%だった。
PC操作では、画面上の情報を見ながらクリック、入力、アプリ間移動を行うような利用を想定する。実際のPC環境を操作できるかを測る「OSWorld-Verified」では78.7%で、Claude Opus 4.7の78.0%をわずかに上回った。Anthropicが公表したMythos Previewの同評価は79.6%で、ここではGPT-5.5と近い水準にある。
研究支援でも前モデルを上回ったという。OpenAIは例として、GPT-5.5の内部版が数学の新しい証明の発見に関与し、証明は後に定理証明器「Lean」で検証されたとしている。
Copyright © ITmedia, Inc. All Rights Reserved.
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
Hugging Face侵害のAIエージェントはOpenAIのモデル──社内のサイバー能力評価中に「GPT-5.6 Sol」などが暴走し本番DBに侵入
-
2
無料で身に付くデータサイエンス 延べ23万人が受講、総務省が募集開始
-
3
AI時代、開発チームの人材は“5つの型”に分かれる Claude Code開発責任者の見立て
-
4
NVIDIAフアンCEOが語る“日本復活”のシナリオ 10年続く半導体バブルと「原発活用」の勝算
-
5
Macアプリ版「Claude Code」がiOSシミュレータと連携 「Computer Use」なしでアプリ操作
-
6
OpenAIのモデルがサイバー攻撃能力評価中に暴走 テストの答えを求めてHugging Faceに侵入
-
7
企業向けAIツールの成長率トップはAnthropic、アカウント数が最も多いのはMicrosoft 365 Okta調査
-
8
Hugging FaceにAI主導のサイバー攻撃 防御もAIで対抗するも、商用モデルは解析拒否で「GLM」採用
-
9
AMDとAnthropicが戦略的提携 「Helios」を最大2GW導入、最大50億ドルの出資も
-
10
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR