ファーストサーバのZenlogic、ストレージ障害の原因は「想定以上の負荷」:対策したはずの設定にもミスが(1/3 ページ)
ホスティングサービスの「Zenlogic」がサービスの全面停止が3日間続く、異例のメンテナンスを行いました。ファーストサーバが公開した報告書から、障害の原因とメンテナンスの長期化に至った背景を推測します。
この記事は、新野淳一氏のブログ「Publickey」の記事「ファーストサーバのZenlogic、ストレージ障害の原因は想定以上の負荷、対策したはずの設定にミスがあったため長期化」を許可を得た上で転載、編集しています。
ファーストサーバが提供しているホスティングサービス「Zenlogic」は、2018年6月下旬から断続的に生じていたストレージ障害に対応するためのメンテナンスを行いましたが、終了の見通しも立たないほど難航し、結局、メンテナンス開始から3日後の夜にようやくサービスが再開されるという事象がありました(参考記事)。
サービス再開から約1週間が経ぎた7月17日、同社はストレージ障害に関する原因およびメンテナンスによるサービス停止が長期化してしまった原因、再発防止策についての報告書を公開しました。

報告書によると、ストレージ障害の直接の原因は、想定を上回る負荷上昇による高負荷状態であり、さらにその対策として行ったネットワーク設定にミスなどがあって、ストレージシステム全体がスローダウンしてしまったとのことです。
分散ストレージのキャパシティプランニングのミスが発端
Zenlogicは、Yahoo! JapanもしくはAWSのいずれかのインフラ上にファーストサーバがサービスを構築するアーキテクチャを採用しています。ファーストサーバは自社でインフラを保有しない戦略を採っているためです。
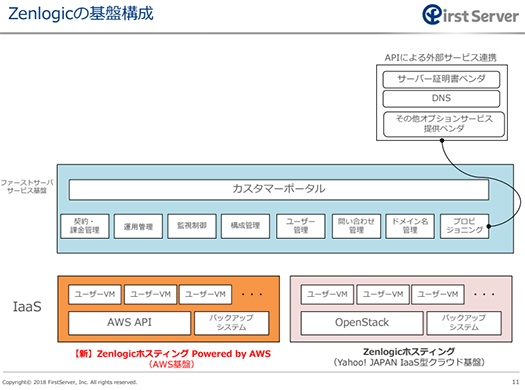 Zenlogicの基盤構成
Zenlogicの基盤構成今回障害が起きたのは、Yahoo! Japanのインフラ上に構築されたZenlogicであり、過去にファーストサーバが発表した内容から、ストレージは分散ストレージのCephで構築されていると推測できます。
Cephは、ストレージサーバをネットワークでつなげて増やしていくほど性能と容量が向上する、いわゆるスケールアウト可能な分散ストレージを実現するソフトウェアです。ただし、もちろん無限にスケールできるわけではありません。このシステム構成の推測と同社の報告を組み合わせて、何が起きていたのかを見てみましょう。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- ニチレイへのサイバー攻撃はなぜ起きた? 「たまたま選ばれる」被害の構造
- Windowsアップデートは「3日以内」に完了へ IT部門が工数をかけずに乗り切る方法は?
- 会議AIを入れたのに、なぜ仕事は楽にならないのか
- 「Windows+R」は絶対に押さないで! 新入社員に贈るセキュリティの新常識5選
- Fable 5とGPT-5.6を3社課金の記者が比べたら、賢さでは勝敗をつけられなかった
- 読者289人が選んだ「2026年に取りたいIT資格」とAI時代の学び直し
- Entra IDの標準認証がパスキーに SMS認証が使えなくなるのはいつ?
- 数カ月の手作業が1週間に 南海電鉄が使う、冷却いらずの「疑似量子コンピュータ」とは?
- 最初の一手で9割が決まる Copilot Studio導入を失敗しない業務選定と初期設計
- AIは本当に「考えている」のか Apple論文が問いかけた推論モデルの限界とその行方
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。