良好なレスポンスを実現するアーキテクチャ:こんな時にはこのITアーキテクチャ (1)
「ITアーキテクチャ構築の勘所」では、アーキテクチャ設計手順を示し、それぞれのステップにおける勘所を示した。その続編となる本連載は、ビジネス要求に応えるために必要な、「大量トランザクション処理」「24時間365日稼働」「使いやすい」といったシステムの特性に着目し、これを実現するためのITアーキテクチャ構築の勘所を述べていきたい。第1回の今回は「良好なレスポンス」を実現するアーキテクチャについて勘所を示す。
ITアーキテクチャ設計は、ビジネス要求に適切に応えるために、ビジネス要求に即したシステム特性を実現していく作業である。例えば、オンライン証券では多数の照会や売買の要求に対して迅速に応答する必要があり、このためにはクラスタリングやキャッシングをうまく適用したアーキテクチャ設計を行うとよい。
前回の連載では、アーキテクチャ設計手順を示し、それぞれのステップにおける勘所を示した。この続編となる今回の連載は、ビジネス要求に応えるために必要な、「大量トランザクション処理」「24時間365日稼働」「使いやすい」といったシステムの特性に着目し、これを実現するためのITアーキテクチャ構築の勘所を述べていきたい。
第1回の今回は「良好なレスポンス」を実現するアーキテクチャについて勘所を示す。レスポンスタイムは、ネットワーク伝送、プレゼンテーション、ビジネス・ロジック、データベースといった処理とそれぞれの待ち時間の合計になる。レスポンスを短くするには、次の考え方を組み合わせて適用するとよい。
- 1) キャッシュを利用し、前回の処理結果を利用するなどして、処理を行わない
- 2) 高速なハードウェアの使用、およびアルゴリズムの改善により、高速に処理を行う
- 3) 処理を並列に実行する
- 4) 十分な処理能力を確保し、優先度を適切に設定して、待ち時間を少なくする
1)のキャッシュを活用して処理を行わないで済ませる方法は、キャッシュにヒットした場合、そもそも処理を行わないで済むので一番効率がよい。図1にWebアプリケーション処理を行うための代表的な構成例とキャッシュの配置を示す。キャッシュにヒットしない場合には、Web画面処理からデータベースのディスクI/Oまで、すべての処理を行う必要があるのに対し、キャッシュにヒットした場合には、キャッシュの場所で処理結果が「折り返されて」返ってくる。
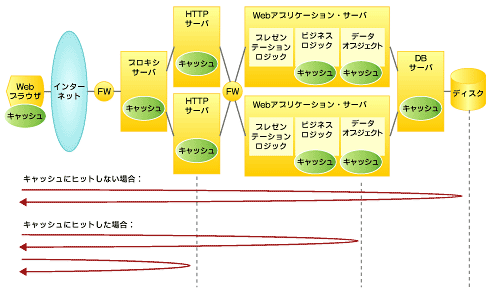 図1 構成例とキャッシュの配置(
図1 構成例とキャッシュの配置(図1では、さまざまなキャッシュを示しているが、キャッシュを利用する以上、処理を省略しているわけであるから、適切な使い分けが必要である。
Webブラウザでのキャッシュは、回線速度が遅い時代には有効であったが、ローカルディスクを消費するためブロードバンド環境では使用しないユーザーもいるだろう(参照:「Webキャッシュを減らしてディスクを節約する」)。ITアーキテクトとしては、Webブラウザのキャッシュがオフでも、効率的に稼働するシステムを目指したい。
Web画面には、静的なHTMLのほか、動的画面でも複数ユーザー間で共有できるものがある。このような画面は有効期限を切って、プロキシ・サーバやHTTPサーバでキャッシュするとよい。
アプリケーション・サーバによっては、ビジネス・ロジックの処理結果をキャッシュする機能を持っているものもある。これは、ビジネス・ロジックをEJBなどの一定の方式で呼び出せるようにしておき、同じ入力処理が行われていれば、処理を行わずにキャッシュされた結果を返すというもので、料金の計算などに使用できる可能性がある。
データベースの処理は、CPUやI/Oともに重い処理であり、データをキャッシュすることは良いレスポンスを確保するためには欠かせない。最良のレスポンスを求めるならば、データの更新はディスクとキャッシュに書き込み、読み取りはキャッシュから読むだけにするというデザインが考えられる。
データをキャッシュする方法としては、アプリケーション・サーバ内にデータ・オブジェクトとしてキャッシュする方法と、データベースのバッファとしてキャッシュする方法がある。前者はEJBのエンティティ・ビーンをキャッシュするといった方法で実装でき、データを読み取る処理がアプリケーション・サーバ内だけで完結するといったメリットがある。ただし、アプリケーション・サーバがクラスタ化されている場合、キャッシュとデータベースの内容の整合性を保つため、扱うデータのレンジでサーバを振り分けるといった仕組みが必要になる(図2)。
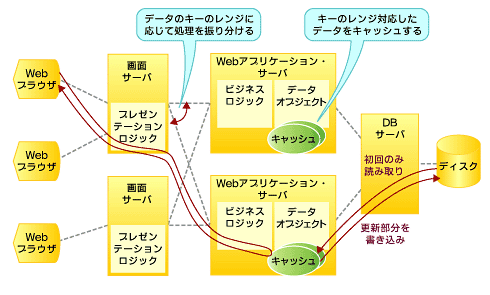 図2 扱うデータのレンジでサーバを振り分ける仕組み
図2 扱うデータのレンジでサーバを振り分ける仕組み勘所:キャッシュの有効利用を考慮して、処理とデータの配置を設計せよ
2)の「処理の高速化」であるが、近年、CPUなどハードウェアの性能が劇的に向上し値段も下がっているため、高速化はハードの増強で済まそうという傾向も見られる。だが、忘れてはならないのは、扱うデータ量も劇的に増えていることである。
簡単な例として、データをリストから探すケースを考えてみよう。リスト内のデータを頭から探していった場合、検索コストはデータ件数をnとして、nに比例する。これに対してリストにデータをソートして格納し、2分探索を行った場合には、検索コストはlog(n)のオーダーで済む(図3)。これ以外にも、ハッシュを用いるなど、さまざまな効率的なデータの扱い方がある。
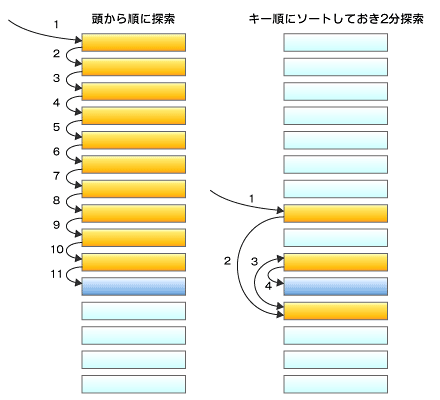 図3 検索コストはlog(n)のオーダーで済む
図3 検索コストはlog(n)のオーダーで済む同じように、データをソートする場合でも、計算量はアルゴリズムによって、nの2乗のオーダーになったり、n × log(n) のオーダーになったりする。
大量データを扱う場合、nの2乗で計算量が増えてしまっては、高速のハードウェアがいくらあっても追いつかない。まず、扱うデータ量やデータの特性に応じて、適切なアルゴリズムを選択し、次に高速なハードウェアを利用するという設計アプローチが大切である。
勘所:大量データを効率的に扱えるアルゴリズムを採用せよ
3)と4)については、大量トランザクション処理に関連する事項なので、次回の「大量トランザクション処理に適したアーキテクチャ」で議論しよう。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- ニチレイへのサイバー攻撃はなぜ起きた? 「たまたま選ばれる」被害の構造
- Windowsアップデートは「3日以内」に完了へ IT部門が工数をかけずに乗り切る方法は?
- 「Windows+R」は絶対に押さないで! 新入社員に贈るセキュリティの新常識5選
- 会議AIを入れたのに、なぜ仕事は楽にならないのか
- Fable 5とGPT-5.6を3社課金の記者が比べたら、賢さでは勝敗をつけられなかった
- 読者289人が選んだ「2026年に取りたいIT資格」とAI時代の学び直し
- Entra IDの標準認証がパスキーに SMS認証が使えなくなるのはいつ?
- 最初の一手で9割が決まる Copilot Studio導入を失敗しない業務選定と初期設計
- 数カ月の手作業が1週間に 南海電鉄が使う、冷却いらずの「疑似量子コンピュータ」とは?
- 顧客の反応、意思決定にどう反映させる? Zoomの取り組みから「AI×CX」の進化を探る
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。