失敗事例に学ぶ運用性能品質向上策:攻めの性能マネジメント(4)(1/2 ページ)
本番システムに何らかの問題が発生すると、現場はお祭り騒ぎとなるが、その中でも性能問題は厄介だ。適切な対処をしないと全く改善されないうえに、最悪の場合はシステムダウンを引き起こすこともある。連載第2回で開発時の性能管理について整理したが、今回は運用時に役立つノウハウを、事例を通して整理する。
事例1 : 応答が返ってこない!
あるWebシステムでは、期待の新サービスをリリースした当日にレスポンスが極度に悪化して、サービスダウンに等しい状況が発生しました。調査の結果、一定の負荷を超えた時点でJavaのGCが多発してAPサーバが過負荷になっていることが判明し、試験で利用していたAPサーバを本番環境に追加することで、何とかその日はサービスが利用できる状況まで負荷を下げられました。こういうときにスケールアウト構成は便利ですね。その後、GC改善の抜本的な対策を実施するまで、システムの負荷は高いままで運用を継続しました。
このシステムでは、リリース前に性能評価も実施していましたが、問題は発見されませんでした。調査の結果、性能評価環境は本番環境に比べてハードウェアスペックが非常に貧弱で、性能評価時は想定業務量の半分以下の負荷しか掛けられなかったという経緯が分かりました。試験環境に本番より低スペックなハードウェアを利用する場合は多いですが、性能はハードウェアスペックに比例して向上するとは限らないので、そこをリスクとして管理することが大切です。
さらに調査を進めたところ、Webブラウザからの1リクエストで、プログラムが数十〜百MBものメモリを無駄に消費しており、それが多発するGCの真の原因でした。これはつまり、ハードウェアスペックが異なる環境でも、負荷を掛けていなくても、検出できる問題だったわけです。
この事例で発生した問題と対策を以下にまとめます。
| 事象 | 原因 | 対策 | |
|---|---|---|---|
| 問題1 | 本番環境が大幅なスローダウン | JavaのGC多発 | サーバ追加(暫定対処) |
| 問題2 | JavaのGC多発 | 多くの無駄データをDBからメモリに乗せていた | プログラム修正 |
| 問題3 | 性能評価で問題が検出できず | 性能評価環境が本番とかなり違う | リスクとして管理 |
事例2 : 悪夢のスローダウン
ある社内システムでは、夜間バッチが遅延して朝になっても終わらず、翌朝の業務開始が遅れるというトラブルが発生しました。そのバッチ処理はDBサーバ内で完結するシンプルな構造だったため、DBMSが原因であるところまではすぐに切り分けができましたが、真の原因は分かりませんでした。そこで、DBMSの専門家にオンサイト対応を依頼しました。
幸いなことに専門家はすぐに到着し、DBMSの統計情報から、ライブラリキャッシュの断片化が発生していることを突き止めました。原因が分かれば後は簡単です。断片化解消のためのコマンドを実行し、翌日からバッチの遅延は、解消されました。
ちなみに断片化は、ライブラリキャッシュの状況を監視しておくことで予兆を把握できるので、問題が発生する前に対処することが可能です。
この事例で発生した問題と対策をまとめます。
| 事象 | 原因 | 対策 | |
|---|---|---|---|
| 問題1 | 夜間バッチの遅延 | DBのライブラリキャッシュ断片化 | 断片化解消コマンド実行 |
| 問題2 | 断片化の予兆を見逃す | 断片化状況を把握していない | 監視する |
事例3 : 販促キャンペーンの恐怖
あるWebシステムでは、伸び悩むアクセス数への対処として、価格引下げのキャンペーンを行いました。するとどうでしょう、キャンペーンが始まるなりアクセス数は急上昇、企画は大成功です。しかし喜びも束の間、システムのレスポンスは急激に悪化し、タイムアウトによる処理エラーまで発生していました。解析の結果、APサーバのCPUがボトルネックであることが判明したため、APサーバ追加というスケールアウトにより問題を解決することができました。
後日、詳しく解析したところ、2つの原因が見つかりました。
1つ目は業務量でした。キャンペーン時のアクセス数はそれまでの数十倍に跳ね上がっていることが分かりました。もちろんその業務量は、システムの限界性能を大きく上回っていたため、まともにレスポンスが返らないのも無理はありません(膨大なアクセスへの対処方法はあるのですが、いまは考えないこととします)。
2つ目は性能限界を意識しない業務運用でした。ユーザー企業の企画担当者が、キャンペーンによるアクセス数の増加量予測を大きく外した点と、システムの限界業務量を把握しておらず、予測を外した場合の影響を考慮していなかったという2点です。このように、企画段階の予測は外れることも多いため、そのための対策が必要です。
余談ですが、このように爆発的ヒットを生み出した企画担当者の企画力はお見事です。彼なら、自ら発生させた販売機会損失を嘆く前に、アクセス集中でのトラブルをWebサイトの宣伝に利用し、新企画で多くの集客を実現してくれることでしょう。
この事例で発生した問題と対策をまとめます。
| 事象 | 原因 | 対策 | |
|---|---|---|---|
| 問題1 | オンラインスローダウン | キャンペーンによるシステム性能限界以上の業務量増加 | サーバ追加 |
| 問題2 | 業務量予測誤りの影響を把握していない | 現状業務量とシステム限界を理解していない | 性能監視と診断 |
事例4 : 人力解析の限界
あるWebシステムでは、突然レスポンスが悪化しました。原因を突き止めるために、すぐに業務系とインフラ系の担当者が招集され、解析作業に入ろうとしたところ、大きな問題が発覚しました。
「解析ツールがない!」
このシステムはOSがHP-UXだったため、担当者としては純正のglanceという強力な解析ツールを利用したいところですが、システムに未導入でした。仕方がないので、vmstatやiostatという、UNIXの基本ツールでの解析を行い、DBサーバのCPU使用率が異常に高いことが分かりました。
CPU使用率が高いのはOracleのプロセスであることまで突き止めたため、いよいよOracleの内部解析を開始しようとした矢先、2つ目の問題が発覚しました。
「ここにも解析ツールがない!」
Oracleの統計情報を分析するためには、statspack(最近ならAWRとADDM)という解析機能を利用したいのですが、これも未導入でした。仕方がないので、DBサーバのCPU追加を行い、問題を解決することができました。
診断ツールの有無により、解析時間は大きく変わってきます。極端な場合、ツールが導入されていれば本番環境を10分解析すれば終わるところを、再現試験込みで1カ月かかることもありました。また、スローダウンしている本番サーバに新しいツールをインストールすると、ほかのトラブルを誘発するリスクがあるため、診断ツールはトラブルが発生してから導入するのは非常に難しいです。そのため、ツール類はシステム構築の際に導入しておくのが賢明な選択といえます。
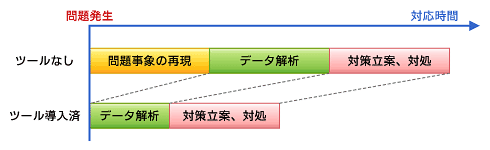 図 診断ツールの有無により、解析時間は大きく変わってくる
図 診断ツールの有無により、解析時間は大きく変わってくるその後の解析により、DBサーバCPU使用率の上昇は、SQL実行計画の変化が原因であることが判明しました。手を付けていないはずのオンライン処理でしたが、夜間バッチのリリースにより、テーブルの構造に変更が加わっており、その影響だったようです。
この事例で発生した問題と対策をまとめます。
| 事象 | 原因 | 対策 | |
|---|---|---|---|
| 問題1 | 夜間バッチの遅延 | DBのライブラリキャッシュ断片化 | 断片化解消コマンド実行 |
| 問題2 | 断片化の予兆を見逃す | 断片化状況を把握していない | 監視する |
| 問題3 | 解析に時間がかかる | 診断ツールがない | 初めから導入しておく |
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- ニチレイへのサイバー攻撃はなぜ起きた? 「たまたま選ばれる」被害の構造
- Windowsアップデートは「3日以内」に完了へ IT部門が工数をかけずに乗り切る方法は?
- 会議AIを入れたのに、なぜ仕事は楽にならないのか
- 「Windows+R」は絶対に押さないで! 新入社員に贈るセキュリティの新常識5選
- Fable 5とGPT-5.6を3社課金の記者が比べたら、賢さでは勝敗をつけられなかった
- 読者289人が選んだ「2026年に取りたいIT資格」とAI時代の学び直し
- Entra IDの標準認証がパスキーに SMS認証が使えなくなるのはいつ?
- 最初の一手で9割が決まる Copilot Studio導入を失敗しない業務選定と初期設計
- 数カ月の手作業が1週間に 南海電鉄が使う、冷却いらずの「疑似量子コンピュータ」とは?
- 顧客の反応、意思決定にどう反映させる? Zoomの取り組みから「AI×CX」の進化を探る
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。