サーバは無事でも、業務が遅滞しては意味がない:ビジネス視点の運用管理(1)(1/2 ページ)
システムインフラの複雑化に伴い、システム的には異常がないのにパフォーマンスが低下する、といった現象が多くの企業で起こっている。しかしITシステムを使う目的は、業務を効率化し収益を上げること。この大目的を実現するためにはどうすれば良いのか。仮想化/クラウド時代の新しい運用管理のアプローチを紹介する
ユーザーは、本当に快適にシステムを使えているのだろうか?
「このITサービスの利用者は、快適に、ストレスなくサービスを利用できているのだろうか?」「円滑にビジネスを遂行できているのだろうか?」――
これを正確に知ることは、ITサービスの提供者にとっては“永遠の課題”かもしれません。というのも、いまやITシステムはビジネスの遂行に不可欠な存在。従って、その稼働が停止してしまうのは論外ですが、たとえきちんと動いていたとしても、その使いやすさやレスポンスの速さは、業績や信頼、顧客満足度などに直接的に影響を与えるからです。この点で、“ビジネスの基盤”を提供し、管理する技術者にとって、冒頭のテーマを確実にクリアすることは本来的な使命の一つとも言えるのではないでしょうか。
ただ、いままではIT部門の人的リソースの問題もあってか、システムの使いやすさやレスポンスの速さ――すなわち「ITサービス利用の快適性」を計測する取り組みは、必ずしも行われているわけではありませんでした。しかし、いま、状況は変わりつつあります。
最も大きな変化は、仮想化技術とクラウドサービスの進展です。これらにより、物理と仮想、オンプレミスとクラウドサービスが混在し、 システムインフラは一層複雑化しています。これを受けてか、普段、IT部門の方と話をしていると、仮想化、クラウドがいよいよ本格的な検討段階に入った、あるいはテスト運用を終えて本番運用が始まろうとしている中で、その運用方法に大きな不安を抱えていることが、その言葉の端々からうかがえます。
「クラウドを本格的に活用した際、本当にいままでと同様の可用性が確保できるのか?」「基幹システムまで仮想化した場合、果たしていままでと同様の運用管理で対応できるのか?」――
私は、このような不安を解消できる一つの方法は、「エンドユーザー体感監視」であると考えています。では、なぜそう言えるのでしょうか? その根拠を、数々の事例を用いながら具体的に紹介していくことが本連載のテーマです。もちろん、システムの可用性や安定性を把握・管理する方法は複数ありますが、ぜひ1つのアプローチとして参考にしていただければと思います。
近年増加した「システムには異常なし、業務には異常あり」
では、具体的に論を展開するために、さっそく事例をご紹介しましょう。ある製造業での事例です。
その会社は全国に販売代理店を2000店以上持っており、受発注は基本的に全て専用のBtoBサイトを通じて行っています。あるとき、このシステムに対して2つの大きな変更を施しました。一つはシステムを構成するサーバの一部を仮想化したこと、もう一つは、iPhone、iPadなども含めて携帯端末からのアクセスも可能にしたことです。
しかしカットオーバー直後からヘルプデスクにクレームが相次ぎます。運用チームは開発チームも巻き込んで調査を行いましたが、なかなか原因が特定できません。
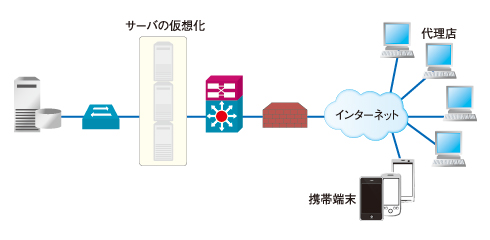 図1 BtoBの受発注システムのサーバを仮想化し、携帯端末からのアクセスも可能にしたところ、思わぬ不具合が発生してしまった。しかし、システム的には異常が見つからない。仮想化技術が浸透した近年、こうした事象が多くの企業で発生している
図1 BtoBの受発注システムのサーバを仮想化し、携帯端末からのアクセスも可能にしたところ、思わぬ不具合が発生してしまった。しかし、システム的には異常が見つからない。仮想化技術が浸透した近年、こうした事象が多くの企業で発生しているまず疑われたのは仮想化されたサーバでした。しかし、ゲストOSのリソース、ホストOSのリソースは特に問題ないようです。次にアプリケーション、特にWebサーバが疑われました。携帯端末からもアクセスできるようにしたため、アクセス数が増えており、それはWebサーバのログからも確認できたのです。しかし、それが本当に原因かどうかを判断するための材料がありません。結局、問題を切り分けるために、携帯端末からのアクセスをいったん中止して様子を見ることにしました。
このように、“システム的には異常がないのに、その動作に異常が出る”といった現象は、仮想化技術が浸透した現在、多くの運用現場で生じているのではないかと思います。これは、今日の仮想化されたITインフラを使いこなす上では、その管理方法にも“それなりのアプローチ”が必要だということを示しているものだと考えます。
これまで、ITシステムの運用現場では、さまざまな形で「監視」が行われてきました。サーバのCPU使用率、メモリ使用率、プロセスの生死などを監視する「サーバ監視」、ネットワーク機器の通信量、各ポートのアップダウンなどを監視する「ネットワーク監視」がその代表でしょう。
このような監視形態は、ITシステムが比較的シンプルな場合は非常に有効でした。例えば、従業員のみが利用するイントラネットで、回線はLANか専用線のみ、サーバはWebサーバとDBサーバが1台ずつといった環境です。このようなシステムなら、サーバ監視だけでも十分だったかもしれません。LANや専用線で遅延が発生することはほとんどないので、パフォーマンスに問題があれば、WebサーバかDBサーバのどちらか、それらを詳しく調べてみれば良いからです。
しかし現在、ビジネスで使われているシステムで、これほど単純な構成はまずないことでしょう。多くの場合、Webサーバがロードバランシングされ、データは1台のDBサーバからだけではなく、連携する複数のDBサーバから取得され、従業員は携帯端末を使ってインターネット経由でアクセスしたりしています。
さらに現在は、こうした環境に仮想化技術が加わり、システムインフラは物理と仮想が混在してますます複雑になっています。クラウドサービスを利用していれば、サービス提供者側の何らかの事情によって可用性が低下する事態も考えられます。すなわち、自社のデータセンターの外にも“不安定要素”を抱えていることになるのです。
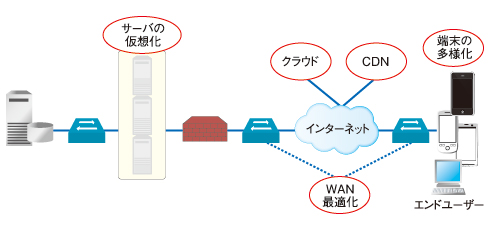 図2 自社のデータセンターは物理/仮想が混在しているほか、SaaS、PaaS、IaaSといったクラウドサービス、ネットワーク経由で業務に必要なデジタルコンテンツを配信するCDN(コンテンツデリバリシステム)などを利用していれば、社外のデータセンターの稼働状況の影響も受けることになる。もはや自社データセンターのサーバ監視、ネットワーク監視だけで安定稼働を担保することは難しい
図2 自社のデータセンターは物理/仮想が混在しているほか、SaaS、PaaS、IaaSといったクラウドサービス、ネットワーク経由で業務に必要なデジタルコンテンツを配信するCDN(コンテンツデリバリシステム)などを利用していれば、社外のデータセンターの稼働状況の影響も受けることになる。もはや自社データセンターのサーバ監視、ネットワーク監視だけで安定稼働を担保することは難しいこのような環境において、サーバ監視、ネットワーク監視だけで検知できる障害は限られています。そもそも新しい技術、新しいサービスとは、従来培ってきた運用方法にも何らかの“変革”を求めるものなのです。
Copyright © ITmedia, Inc. All Rights Reserved.
アイティメディアからのお知らせ
注目のテーマ

人気記事ランキング
- ニチレイへのサイバー攻撃はなぜ起きた? 「たまたま選ばれる」被害の構造
- Windowsアップデートは「3日以内」に完了へ IT部門が工数をかけずに乗り切る方法は?
- 「Windows+R」は絶対に押さないで! 新入社員に贈るセキュリティの新常識5選
- 会議AIを入れたのに、なぜ仕事は楽にならないのか
- Fable 5とGPT-5.6を3社課金の記者が比べたら、賢さでは勝敗をつけられなかった
- 読者289人が選んだ「2026年に取りたいIT資格」とAI時代の学び直し
- Entra IDの標準認証がパスキーに SMS認証が使えなくなるのはいつ?
- 最初の一手で9割が決まる Copilot Studio導入を失敗しない業務選定と初期設計
- 数カ月の手作業が1週間に 南海電鉄が使う、冷却いらずの「疑似量子コンピュータ」とは?
- 顧客の反応、意思決定にどう反映させる? Zoomの取り組みから「AI×CX」の進化を探る
![]() ITmediaはアイティメディア株式会社の登録商標です。
ITmediaはアイティメディア株式会社の登録商標です。