CEDEC 2024
“AIキャラクターによるゲーム実況”の裏側 バンダイナムコ研究所が解説 AI生成コンテンツの“5つの落とし穴”とは(3/3 ページ)
落とし穴4 表現の多様性:Chain of Thoughtの応用
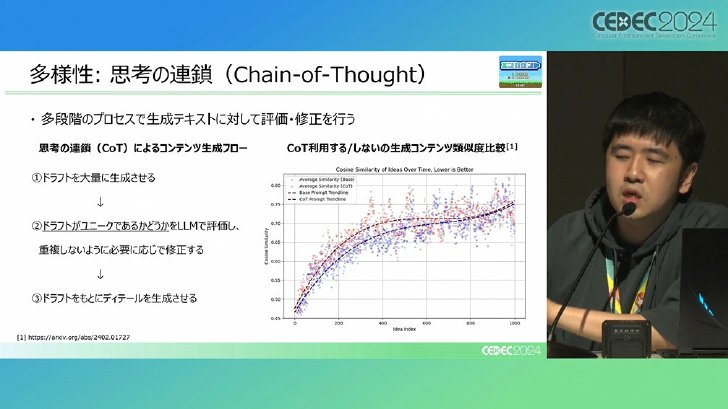
4番目の課題は多様性の確保だ。LLMは同じような表現やフレーズを繰り返し使用する傾向があり、これがゲームコンテンツの単調さにつながる可能性がある。この問題に対しては、生成パラメータの調整やプロンプトの工夫、さらには「Chain of Thought」(思考の連鎖、CoT)と呼ばれる手法を用いることで、より多様な出力を得られるよう取り組んでいる。
 「Chain of Thought」(思考の連鎖、CoT)の説明
「Chain of Thought」(思考の連鎖、CoT)の説明
Chain of Thoughtは複数のAI(LLM)を連携させて行うアイデア創出と評価の方法だ。まず、1つのLLMが大量のアイデアやたたき台を生成する。次に、別のLLMがこれらを評価し、重複を避けつつ多様性を確保するよう修正することで、表現のバリエーションを増やすという仕組みだ。
落とし穴5 キャラクター性の維持:RAGの活用
最後の課題は、キャラクターらしさの維持だ。ゲームに登場するキャラクターの個性や設定を正確に反映したテキストを生成することは、LLMにとって難しい課題の一つである。これに対してバンダイナムコ研究所では「RAG」(特定のデータベースをAIに参照させ、回答精度を高める手法)を採用している。同社では、キャラクターに関連する情報を事前に用意し、それをLLMに参照させることで、より設定に沿ったテキスト生成を可能にしている。
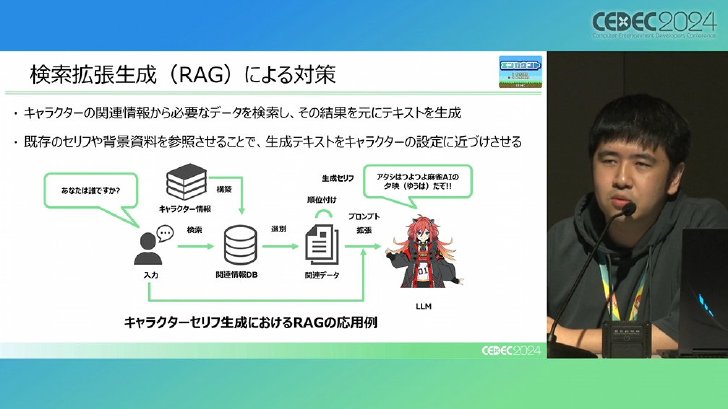 ゲームキャラのテキスト生成にもRAGを活用
ゲームキャラのテキスト生成にもRAGを活用
しかし、RAGを使用する際にも課題が存在する。例えば、RAGを使うと口調のブレが生じたり、検索されたせりふが必ずしもキャラクターの特徴的な話し方を反映しなかったりする場合がある。これに対しては、テキストを検索用のベクトルに変換するAIモデルを再学習させ、キャラクターの話し方と内容の両方を考慮した検索を可能にする対策を取っている。
 RAGと口調のブレ問題
RAGと口調のブレ問題
また、RAGではメタ情報、つまりキャラクターに関する現実世界の情報(声優など)が生成テキストに含まれてしまい、漏えいするリスクもある。この対策として、RAG用の知識リソースを準備する段階で、フィクション情報とリアル世界の情報を分離し、フィクション情報のみを使用するように対策する必要がある。
RAGによる最後の課題として、知識のブレがある。LLMが与えられた設定を無視し、一般的な知識に基づいて回答してしまう問題だ。これに対しては、LLMにキャラクターを直接演じさせるのではなく「キャラクターのせりふを創作するシナリオライター」としての役割を与えるようプロンプトを調整する対策を取っている。
これらの話の締めくくりとして、頼さんは「今日紹介したベストプラクティスが必ず明日のベストプラクティスとは限らない」と述べ、技術の進化の速さを強調。その上で「開発者としてはAIのことを過小評価も過大評価もせず、自社にとってのベタープラクティスを目指して、落とし穴を恐れずに見極め続ける姿勢が大事」だと結論づけた。
 「今日のベストプラクティスが必ず明日のベストプラクティスとは限らない」と頼さん
「今日のベストプラクティスが必ず明日のベストプラクティスとは限らない」と頼さん
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
「Claude Fable 5」をサブスクの標準機能に――AnthropicのエンジニアがXに投稿 7月8日以降の「早期復活目指す」
-
2
NTT、独自のAIモデル「tsuzumi 2」発表 “国産AI開発競争”に「負けられない」と島田社長
-
3
Meta、「Claude Codeと組織改編で爆速開発」のはずが「想定より加速せず」 ザッカーバーグ氏、社内集会で発言
-
4
ゲームエンジン「Godot」AI生成コードを原則禁止へ レビュアー疲弊「機械と話したくない」
-
5
【2025年12月】ChatGPT、Gemini、Claudeの企業向けプランを徹底比較 “コスパ”以外の選定ポイントにも注目
-
6
マイクロン、AI需要で広島工場増強へ起工式 1.5兆円投資
-
7
ソフトウェアエンジニアの仕事は「ループを書くこと」になる 内側ループと外側ループ(ハーネス)入門
-
8
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
9
「今日言うつもりはなかったが……」 孫正義氏が明かした「ロボット自動量産工場」の実態
-
10
人型ロボットが工場で稼働する様子を6日間生配信、作業成功率99.99%をうたう 中国メーカー
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR