「Claude Mythos」の性能は本物か? 英研究機関が検証結果を公表
AIの安全性を評価する英国政府の研究機関、AI Security Institute(以下、AISI)は4月13日(現地時間、以下同)、Anthropicが同月7日に発表した次世代モデル「Claude Mythos Preview」(以下、Mythos)のサイバーセキュリティ能力の評価結果を公表した。その結果、同モデルが従来モデルを上回る性能を示し、人間の専門家が数日を要する多段階サイバー攻撃を自律的に実行できることを確認。AISIは、同等の能力を持つモデルが公開される将来に備え、組織に対してサイバーセキュリティの基本を押さえる必要性を説いた。
多段階攻撃シミュレーションを“完遂”
AISIは今回、2種類の評価を実施した。1つ目は、システムの脆弱(ぜいじゃく)性を突いて隠された情報を奪取する「キャプチャー・ザ・フラッグ」(CTF)形式の評価。タスクの難易度別に実施された。同評価においてMythosは、2025年4月以前にはどのモデルも解けなかった専門家レベルのタスクにおいて、73%の成功率を記録した。
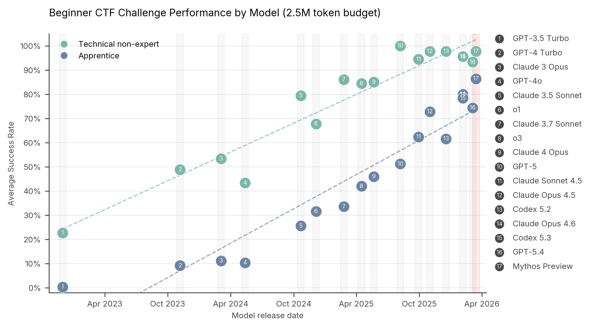 実務者レベルおよび専門家レベルのCTFタスクでのパフォーマンス(出典:公式ブログ)
実務者レベルおよび専門家レベルのCTFタスクでのパフォーマンス(出典:公式ブログ)
2つ目は、現実のサイバー攻撃手法を再現した「サイバーレンジ」と呼ばれる評価だ。AISIは初期偵察からネットワークの完全掌握までを再現した32段階の企業ネットワーク攻撃シミュレーションを構築。人間の専門家が約20時間かかると想定されるこのシミュレーションにおいて、Mythosは10回の試行中3回で全工程を完遂した初のモデルとなった。全試行の平均でも32段階中22段階を突破しており、「Claude Opus 4.6」の16段階を上回った。この結果を受けてAISIは、Mythosがネットワークへのアクセス権が取得された小規模で防御が脆弱なエンタープライズシステムに自律的に攻撃する能力があるとした。
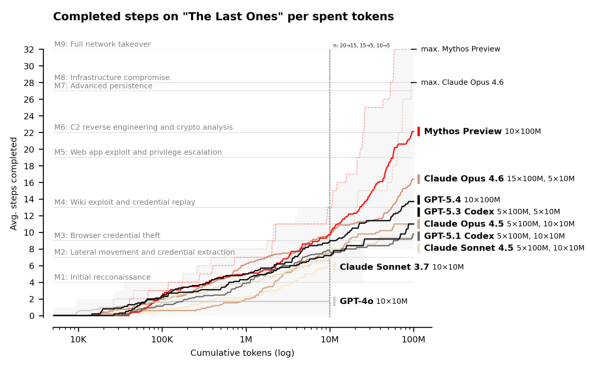 32段階の攻撃シミュレーションでのパフォーマンス(出典:公式ブログ)
32段階の攻撃シミュレーションでのパフォーマンス(出典:公式ブログ)
工場の制御系などOT環境を対象とした別のシミュレーションでは完遂に至らなかったが、これはITセクションで詰まったもので、OT環境での攻撃能力が低いとは言えないとしている。また、AISIの評価環境にはアクティブな防御担当者や検知ツールが存在せず、攻撃的行動へのペナルティもないため、十分に防御された実環境で同等の結果を出せるかは不明だとしている。
AISIが示す、組織が今すべきこと
AISIは、今回の結果を受けて二つの方向性を示した。まず、組織が今取るべき対策として、セキュリティアップデートの定期適用、堅牢(けんろう)なアクセス制御、適切なセキュリティ設定、包括的なログ記録といった基本的な対策の重要性を改めて訴えた。
もう一つは、評価手法自体の進化の必要性だ。AIの能力向上が続く中、防御のない環境でのテストではモデル間の差異を十分に測れないとの認識を示し、今後はリアルタイム検知やインシデント対応を含む、より現実に即した防御環境での評価へ移行する方針を示した。また、AISIはAIのサイバー能力が攻撃と防御の双方に活用しうることを強調し、防御面での活用可能性にも期待を寄せている。
Copyright © ITmedia, Inc. All Rights Reserved.
この記事の著者
関連記事
こんなメディアも見られています
ITmedia AI+に関連する情報をお探しであれば、こちらのメディアもお役に立てるかもしれません。
SpecialPR
よく見られているカテゴリー
アクセスランキング
-
1
農水省の“クソダサ”ポスター話題 「AIよりよっぽど良い」の声も 担当者に狙いを聞いた
-
2
OpenAI、初のハードウェア「Codex Micro」を230ドルで発売 Apple提訴の渦中にある端末とは別物
-
3
「ピースサインで勤怠打刻」 Joshinが全事業所に導入した顔認証が“従業員から絶賛”のワケ
-
4
【一時非公開のお知らせ】「バズるほど赤字だった」──野田クリスタルのAIペットカードゲーム、公開停止からの復活劇を本人に聞いた
-
5
富士通がNVIDIA「Rubin」対応の国産AIサーバを今秋製造へ ソブリン需要に対応
-
6
NEC森田社長が語る「脱・人月商売」の行方 組織の壁を破るAI人材育成法
-
7
Anthropicと組んだNEC それでも森田社長が「4つの主権」にこだわる真意
-
8
コードなしでもベイズ統計ができる無料の神ツール「JASP」 ~ マウス操作だけでここまでできる
-
9
NVIDIAが「Jetson Thor」に新モジュール追加、高騰するメモリの使用量削減技術も
-
10
「AIと壁打ちはもう古い」 業務タスクを任せる「Claude Cowork」の落とし穴
SpecialPR
ITmedia AI+ SNS
インフォメーション
注目情報をチェック
ITmedia AI+をフォロー
あなたにおすすめの記事PR